 yopp
yopp


avgObjSize это size / count. А не storageSize / count
yopp
Ещё момент: массивы в bson это документы, у которых вместо ключа индекс строкой. Ну и собственный префикс типа
yopp
Array - The document for an array is a normal BSON document with integer values for the keys, starting with 0 and continuing sequentially. For example, the array ['red', 'blue'] would be encoded as the document {'0': 'red', '1': 'blue'}. The keys must be in ascending numerical order.
 Roman
Roman
Годная инфа, спасибо
Roman
Посмотрю на storageSize. Тем не менее, он все равно должен коррелировать.
yopp
Плюс у вас из второй схемы пропали огромные esi и uri
Roman
Еще бы ради интереса сделать трансформацию без изменения схемы, только ключи.
yopp
Экономия на спичках это сложно и там есть множества нюансов
yopp
Я не просто так говорю про ROI
yopp
Это очень трудоёмкий процесс
Roman
Я уже писал выше, это конкретно мой кейс, рабочее решение. Я не веду речь про гуд практис, здесь интересны детали хранения монгой данных.
yopp
Посмотрю на storageSize. Тем не менее, он все равно должен коррелировать.
Уверен что там будут менее впечатляющие цифры
Roman
Надо заценить
Roman
10-20%?
yopp
Не больше, да
yopp
Если сравнить две схемы в которых порезаны ключи, при этом структура вообще не изменилась. Изменение порядка полей имеет большое значение для компрессии и сразу делает сравнение невозможным
yopp
Так как изменение порядка ключей в оригинальном документе может иметь сходный эффект
Roman
Порядок ключей? Реально?
yopp
Да. Потому что могут измениться размеры словарей/backreferences, могут появится дополнительные префиксы которые планировщик алгоритма сжатия решит заменить на backreference и ещё куча других эффектов
Roman
А есть тут какие то общие советы? Типа порядок ключей лучше не менять и тп
Roman
Типы данных там группировать
Roman
У меня вообще не праздный интерес. Есть цель каким либо образом сократить массив данных в 80Gb, который еще и постоянно растет.
Anonymous
Всем привет, подскажите пожалуйста, почему при имени модели User - нода с mongoose создает коллекцию Users, а пайтон с pymongo - коллекцию User - это можно как-то более явно указать?)
 Mykola 🤷🏼♀️
Mykola 🤷🏼♀️
Всем привет, подскажите пожалуйста, почему при имени модели User - нода с mongoose создает коллекцию Users, а пайтон с pymongo - коллекцию User - это можно как-то более явно указать?)
https://mongoosejs.com/docs/guide.html#collection
yopp
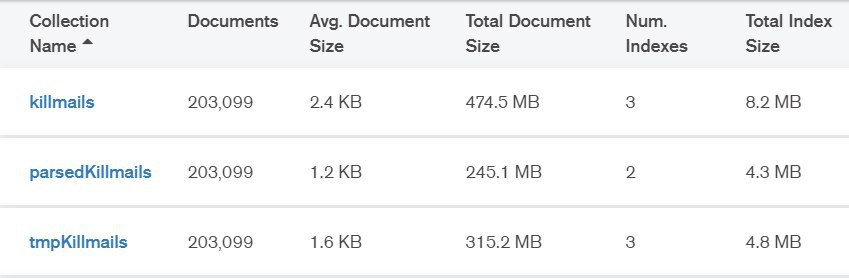 Roman
Roman
вышло в итоге 34% сокращения
yopp
storageSize посмотрите ещё
Roman
сравнил так же изменение при сжатии zlib
> db.tmpKillmailsZlib.storageSize()
71057408
> db.killmailsZlib.storageSize()
82415616
в итоге 13.8% сокращения на чисто обрезании ключей
Roman
https://pastebin.com/StYHLbTg
пример документа с обрезанными ключами
 Valerii
Valerii
Привет, а никто не знает чаты по питону в целом, вопрос про потоки, хочу задать?
yopp
14% на zlib уже похоже на корректные значения
 Roman
Roman
 Roman
Roman
я с бд 0вый
Roman
import Users from '@models/Users';
import SuperClass from '../SuperClass';
export default class ReqCreateSubid extends SuperClass {
constructor(init) {
// super enable
super(init);
// params
({ req: this.req, res: this.res } = init);
this.preffix = 'arbortag';
// class list
}
async deleteClients(_DB) {
try {
this._DB = _DB;
this._DB[this.preffix] = [];
await this._DB.save();
} catch (err) {
console.error(`❌ [ERROR] ${err}`);
}
}
async pushClients(_DB, subid) {
try {
this._DB = _DB;
this._DB[this.preffix].push(subid);
await this._DB.save();
} catch (err) {
console.error(`❌ [ERROR] ${err}`);
}
}
async run() {
try {
const { access, subid, devRemove } = this.req.query;
const _DB = await Users.findOne({ access }).exec();
if (this.$$isEmpty(_DB)) this.$$throwError(400, 'user not found');
// console.log('dere', devRemove === this.preffix, devRemove);
if (devRemove === this.preffix) await this.deleteClients(_DB);
else {
this.subidExist = await Users.exists({ [this.preffix]: subid });
if (this.subidExist) this.$$throwError(409, '[Subid] already exists');
await this.pushClients(_DB, subid);
}
console.log('_DB update', _DB);
const result = {
serverAnswer: this.$$isEmpty(_DB[this.preffix]) ? ['Empty'] : _DB[this.preffix],
// ,
// debug: { subid, info: _DB || 'empty' }
};
return this.$$goodAnswer(result);
} catch (err) {
this.__console(err);
return this.$$badAnswer(err);
}
}
}
Roman
 Leonid
Leonid
Ребята. привет. У меня проблема с запросом к MongoDB через MongodbDriver C#.
делаю запрос к реплике формата collection.Find(jsonQuery).Sort(jsonSort).Skip(0).Limit(50).ToListAsync();
при установленном соединении если выполнить подряд 2 раза этот же запрос то в первый раз время выполнения ~1 сек, во второй и последущий более 60 сек.
как видите разница огромна.
Если же перед каждым выполнением создавать заново конекшен то время выполнения стабильно ~ 1 - 2 сек.
Если не использовать .Sort то запросы всегда выполняются быстро.
Если извлекать не ToListAsync а FirstOrDefaultAsync то время выполнения одинаково.
При этом если выполнить два эти же запроса через connection.runCommand() при одном подключении то всегда время выполнения примерно 600мс.
серия запросов через Studio 3T выполняется без задержек
Данная бага воспроизводится при всех доступных версиях Mongodb.driver и с конкретной базой данных MongoDB (c локальным снепшотом не-репликой все норм)
Буду рад любым советам т.к. за 4 дня уже закончились идеи.
Leonid
 Vlad
Vlad
Привет, а каким способом можно загрузить картинку и текст в базу данных? К примеру, для поста в блог.
Daniil
Mykola 🤷🏼♀️
Привет, а каким способом можно загрузить картинку и текст в базу данных? К примеру, для поста в блог.
это если только для себя. В общем случае картинки не должны ганяться в бд и загружать аппку и саму бд
Vlad
это если только для себя. В общем случае картинки не должны ганяться в бд и загружать аппку и саму бд
Пока что для себя просто. А какая альтернатива тогда?
Mykola 🤷🏼♀️
Ребята. привет. У меня проблема с запросом к MongoDB через MongodbDriver C#.
делаю запрос к реплике формата collection.Find(jsonQuery).Sort(jsonSort).Skip(0).Limit(50).ToListAsync();
при установленном соединении если выполнить подряд 2 раза этот же запрос то в первый раз время выполнения ~1 сек, во второй и последущий более 60 сек.
как видите разница огромна.
Если же перед каждым выполнением создавать заново конекшен то время выполнения стабильно ~ 1 - 2 сек.
Если не использовать .Sort то запросы всегда выполняются быстро.
Если извлекать не ToListAsync а FirstOrDefaultAsync то время выполнения одинаково.
При этом если выполнить два эти же запроса через connection.runCommand() при одном подключении то всегда время выполнения примерно 600мс.
серия запросов через Studio 3T выполняется без задержек
Данная бага воспроизводится при всех доступных версиях Mongodb.driver и с конкретной базой данных MongoDB (c локальным снепшотом не-репликой все норм)
Буду рад любым советам т.к. за 4 дня уже закончились идеи.
если через runCommand выполняется быстро, то проблема видимо только в драйвере. Пробовали открывать ишьюс у них в репе?
Mykola 🤷🏼♀️
Пока что для себя просто. А какая альтернатива тогда?
объектные хранилища, а в бд только линки хранить
Daniil
Пока что для себя просто. А какая альтернатива тогда?
Для сервисов, которые не предполагают большой нагрузки нет проблемы хранить в базе указанными выше способами (GridFS предпочтительнее) или просто на том же сервере, где бд в определённой директории
Далее при росте нагрузки стоить смотреть на AWS S3 и подобные ему, а также на CDN, но общий принцип тот же
Leonid
если через runCommand выполняется быстро, то проблема видимо только в драйвере. Пробовали открывать ишьюс у них в репе?
через nodejs mongodb driver тоже все хорошо. похоже что да, это монгодрайвер чудит.
попробую открыть тикет
Leonid
Спасибо за разъяснение
мы хранили в AWS, а в базе хранили кроме урлы метаданные картинки (например различные разрешения картинки ) в том числе цветную маску картинки в виде градиента, которую отображали в placeholder пока картинка грузится
Mykola 🤷🏼♀️
allowDiskUse: true у всех работает? У меня достаточно простая агрегация с $limit: 10 и сортировкой по индексированному полю - ничего не помогает.
При этом есть вторая точно такая же аггрегация, но вместо true -> false и она спокойно отрабатывает даже с сортировкой не по индексированному полю.
{ $match: { firstVerifyAttempt: { $exists: true } } }
Монга 4.2.5.
Нагуглить какой-то нормальной инфы по этой теме не смог
Mykola 🤷🏼♀️
и с robo3t тоже проходит ок(( ох уж эти драйверы-монгусы
 Kirill
Kirill
Привет всем.
Такой вопрос: Как эффективнее всего можно реализовать обновление дата-сета раз в минуту?
Монга умеет в какой-нибудь свой Diff или может документам каждый раз приписывать поле version + текущее по счёту обновление и запрашивать по нему?
Vadzim
всем привет. подскажите, нормально ли если у mongo доступно большое количество коннектов (Я вижу это в графане)?
Daniil
всем привет. подскажите, нормально ли если у mongo доступно большое количество коннектов (Я вижу это в графане)?
Да, это для того, чтобы обеспечивать пул соединений
Vadzim
Да, это для того, чтобы обеспечивать пул соединений
т.е. более ста тысяч норм? Я просто впервые столкнулся с такой цифрой
Daniil
т.е. более ста тысяч норм? Я просто впервые столкнулся с такой цифрой
Нет, в пределах нескольких сотен обычно
Vadzim
Нет, в пределах нескольких сотен обычно
можно ли как-то их уменьшить не рестартовав БД? Или это в настройках?
Daniil
можно ли как-то их уменьшить не рестартовав БД? Или это в настройках?
а что у вас показывает в монгошеле вот эта команда - db.serverStatus().connections ?
Daniil
потому что дефолтное значение maxIncomingConnections = 65536, т.е. до 100к+ тут не добраться никак
(https://docs.mongodb.com/manual/reference/configuration-options/#net.maxIncomingConnections)
возможно вы принимаете за кол-во соединений какую то другую метрику?
Vadzim
вполне возможно по поводу метрики, я как юзер смотрю на графики
Vadzim
сейчас посмотрю через db.serverStatus().connections
Вася
подскажите как импортировать json в котором есть ключ "id": 'fasdf'. но при импорте в бд он стал "_id" с типом ObjectId а не строкой
Daniil
Вася
ну у меня есть связные таблицы которые по этим айдишникам и связаны
Daniil
использовать в качестве _id что то другое заместо предлагаемого монгой ObjectId плохая идея
заведите просто поле customId например и связывайте по нему если у вас есть в этом острая необходимость
но в общем случае лучше пользоваться ObjectId и для связей между коллекциями
Вася
еще раз попробую. у меня есть 3 Json файла с городами регионами и странами. они связаны между собой айдишниками. я хочу импортировать в монгу при этом сохранить эту свзять как раз таки с помощью ObjectId.
какой для этого есть верный подход.
Daniil
еще раз попробую. у меня есть 3 Json файла с городами регионами и странами. они связаны между собой айдишниками. я хочу импортировать в монгу при этом сохранить эту свзять как раз таки с помощью ObjectId.
какой для этого есть верный подход.
идентификаторы с помощью которых связаны документы соответствуют ObjectId или нет?
Вася
я нашел базу json. связь по id.
Вася
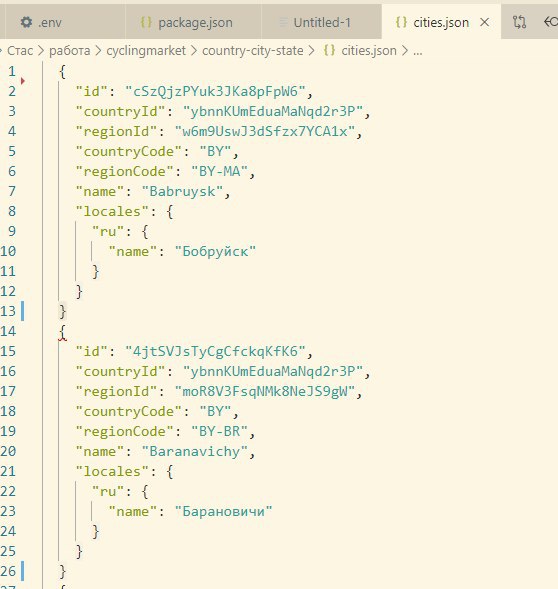 Daniil
Daniil
Это просто строковый идентификатор, который не может быть преобразован в ObjectId.
Либо как я уже писал выше использовать этот ID в виде доп. поля, либо при импорте получать уже ObjectId, которые будет давать новым документам монга и использовать их для построения связей между коллекциями
Вася
Это просто строковый идентификатор, который не может быть преобразован в ObjectId.
Либо как я уже писал выше использовать этот ID в виде доп. поля, либо при импорте получать уже ObjectId, которые будет давать новым документам монга и использовать их для построения связей между коллекциями
а какой есть алгоритм связывания двух заполненных уже json. если я всетаки хочу использовать ObjectId а не строковые Id.
например я делают импорт стран потом по строкому id делаю импорт городов привязывая уже ObjectId ?? а потом удаляю все строковое айдишники
Daniil
а какой есть алгоритм связывания двух заполненных уже json. если я всетаки хочу использовать ObjectId а не строковые Id.
например я делают импорт стран потом по строкому id делаю импорт городов привязывая уже ObjectId ?? а потом удаляю все строковое айдишники
Я бы написал скрипт в котором первая итерация идёт по стране, вставляется в монгу страна, получается ID, который монга этой стране присвоила, выбираются все регионы страны (тут как раз пригодится связь файлов с помощью строковых ID), далее идёт вложенная итерация по регионам и примеряется такой же алгоритм для городов
Daniil
Ну алгоритмы могут быть разными, но общий смысл такой - получили идентификаторы для объектов первого уровня, спускаемся на уровень ниже и используем там идентификаторы с предыдущего уровня
 Melodeiro
Melodeiro
Ну можно еще regex пробежаться по полям, если навыки есть
Вася
 Daniyar
Daniyar
привет всем... это нормально хранить историю действий пользователей в бд связанное с post, put, delete? если так, будет ли мусориться данные и тд, можно ли архивировать или типа того? какое самое оптимальное решение для этой проблемы?
Daniil
Daniil
Однако очень часто такие данные можно группировать по отрезку времени например и так хранить
При выборе формы хранения отталкивайтесь от того, как чаще всего вам нужно будет эти данные читать и каким образом отображать
Daniyar
например есть в коллекции лога userName: string, action: int, desc: stringed json... добавил индексацию для userName, action, createdAt.. чтоб сортировать по createdAt и серчить по userName и action