 Roman
Roman


в доке такого нет
 Nick
Nick
Привет
На гитхабе видел несколько схем такого типа
const mongoose = require('mongoose')
var Schema = mongoose.Schema;
const userSchema = new Schema({
chat_id: {
type: Number,
index: true,
unique: true,
required: true
},
first_name: {
type: String,
required: true
},
last_name: String,
username: String,
}, {
timestamps: true
})
const User = mongoose.model("User", userSchema)
module.exports = User
Но я всё время получаю ошибку
The 2nd parameter to `mongoose.model()` should be a ' +
'schema or a POJO
Подскажите, пожалуйста, что я делаю не так
внешне никакой ошибки нет и все согласно доке https://mongoosejs.com/docs/guide.html
Nick
единственный вопрос к
{
timestamps: true
}
 Paul
Paul
 Daniyar
Daniyar
ребят, по умолчанию mongoose по createdAt сортирует же да?
Daniyar
если я индексацию по createdAt не давал и в aggregate в конце приписал sort by createdAt (чтоб он вразброс не давал) он не будет есть память для сортировки?
 4eburator
4eburator
Привет всем есть тут есть ктото кто в реплике разберается?
Daniyar
 Mykola 🤷🏼♀️
Mykola 🤷🏼♀️
ребят, по умолчанию mongoose по createdAt сортирует же да?
Не сортирует.
Индексы нужно отдельно ставить на createdAt.
Можно вооружиться .explain и тестить
 yopp
yopp
если я индексацию по createdAt не давал и в aggregate в конце приписал sort by createdAt (чтоб он вразброс не давал) он не будет есть память для сортировки?
если индекса нет, то сортировка будет в памяти
Daniyar
спасибо
yopp
 Anton
Anton
Какой самый эффективный способ получить последние n элементов коллекции?
Nick
Какой самый эффективный способ получить последние n элементов коллекции?
индекс по дате и выборка с лимитом - единственный способ
Mykola 🤷🏼♀️
Какой самый эффективный способ получить последние n элементов коллекции?
есть ещё capped коллекции
https://docs.mongodb.com/manual/core/capped-collections/
Anton
Да я уже решил все делать на клиенте, коллекции максимум могут быть 100 элементов и сами объекты небольшие
Vladimir
Привет! Разбираюсь с тем как устроен bson, насколько я понял ключи хранятся как есть, просто строкой. Также в монге документы хранятся в виде валидных bson. Возник вопрос почему ключи не кодируются, для экономии места, времени на сравнение и т.п.? Кажется что поскольку ключи в документах примерно одинаковые обычно, то это может давать большой оверхед, так ли это?
Mykola 🤷🏼♀️
Да я уже решил все делать на клиенте, коллекции максимум могут быть 100 элементов и сами объекты небольшие
.sort({ _id: -1}) по идее тоже должен работать хорошо, т.к. по дефолтному индексу
Daniil
Привет! Разбираюсь с тем как устроен bson, насколько я понял ключи хранятся как есть, просто строкой. Также в монге документы хранятся в виде валидных bson. Возник вопрос почему ключи не кодируются, для экономии места, времени на сравнение и т.п.? Кажется что поскольку ключи в документах примерно одинаковые обычно, то это может давать большой оверхед, так ли это?
https://stackoverflow.com/questions/11429804/why-are-key-names-stored-in-the-document-in-mongoddb
Vladimir
Спасибо, то что нужно
Roman
Оверхед по итоговому размеру данных весьма большой может получаться
yopp
Все эти оптимизации не имеют смысла, так как в 98% случаев даже snappy нивелирует все нюансы
yopp
Экономить на размере ключей почти никогда не имеет смысла
Roman
Все эти оптимизации не имеют смысла, так как в 98% случаев даже snappy нивелирует все нюансы
Snappy по дефолту стоит или указывать на коллекцию надо?
yopp
По-дефолту. С 4.2 есть поддержка zstd
Roman
Да дефолт
By default, WiredTiger uses block compression with the snappy compression library for all collections
Roman
Все эти оптимизации не имеют смысла, так как в 98% случаев даже snappy нивелирует все нюансы
Так вот, смысл все таки есть, проверялось на реальном примере и уменьшилась коллекция в два раза, путем сокращения ключей до 3-4 символов без особой потери читаемости.
Roman
Так же пример кейса где это может быть важно - бесплатные 500мб на атласе.
yopp
yopp
Так же пример кейса где это может быть важно - бесплатные 500мб на атласе.
Время разработчика дороже чем атлас
Roman
К - Категоричность
yopp
Второй момент, разница в два раза вызывает вопросы
Или это какой-то специфический случай или ошибка дизайна эксперимента
Roman
Второй момент, разница в два раза вызывает вопросы
Или это какой-то специфический случай или ошибка дизайна эксперимента
Документы весьма большие и ключи часто повторяются во вложенных массивах
yopp
Если ключи часто повторяются, то тем более
Roman
Это реальный случай
yopp
Повторение сегментов это и есть основа почти всех алгоритмов сжатия
Roman
Я в курсе
yopp
Т.е участок данных заменяется на обратную ссылку
Roman
К тому же надо еще вспомнить про оперативную память и ее размер, если вдруг захочется держать весь датасет в памяти
yopp
К тому же надо еще вспомнить про оперативную память и ее размер, если вдруг захочется держать весь датасет в памяти
Время разработчика все ещё дороже чем всё остальное
Roman
Докинем еще размер на передачу по сети
Roman
Я не понимаю причем здесь время разработчика
yopp
Часть данных хранится в дисковом кеше
Roman
ROI как раз вышел годным, это все делается очень просто на самом деле
Roman
В паре мест добавить пару мапперов
Roman
И плюс кейс когда что то пишется с нуля - имеет смысл держать в голове этот факт при проектировании схем документов
Roman
Я ж не говорю о том, чтобы всем бежать срочно что то менять в работающем коде. Это просто факт, который как минимум интересно знать. А кому то еще и полезно.
yopp
И плюс кейс когда что то пишется с нуля - имеет смысл держать в голове этот факт при проектировании схем документов
Я все ещё сомневаюсь в корректности измерений. Слишком большая разница. 15-20% ещё реально, больше — уже вызывает вопросы. Не исключаю специфики, но сомневаюсь.
Вероятно вы сравнивали существующую коллекцию, в которой могло образоваться много вакантных страниц, с новой коллекцией, в которую вы залили модифицированные данные.
yopp
Я ж не говорю о том, чтобы всем бежать срочно что то менять в работающем коде. Это просто факт, который как минимум интересно знать. А кому то еще и полезно.
Предварительная оптимизация это ужасный совет
yopp
Решать несуществующие проблемы очень дорого
Roman
Это не имеет отношения к предварительной оптимизации, речь скорее про именование переменных
Roman
Если с нуля пишется - имена переменных
Roman
Если работающий код - уже оптимизация при необходимости (не предварительная)
yopp
Это и есть предварительная оптимизация. Вы хотите изменить какой-то один подход, в пользу другого подхода, руководствуясь одним случаем.
Да, уменьшение длинны ключа в ряде случаев может иметь положительный эффект. Но для того чтоб понять какой конкретно эффект и стоит ли в него инвестировать, нужно иметь перед глазами реальную проблему.
В общем случае изменение не будет существенным, так как проблема очень редко в размере документа. Проблемы в основном в том, что нет индекса, или слишком много индексов или слишком большая вариативность значений индекса.
yopp
И попытка решить эту проблему размером документа — неэффективна.
yopp
Оптимизации это десятки и сотни человеко-часов. Чтоб это имело хоть какой-то экономический смысл, подобные изменения должны экономить тысячи долларов
Nick
а пример документа до и после можно?
Nick
куданить на пастбин
yopp
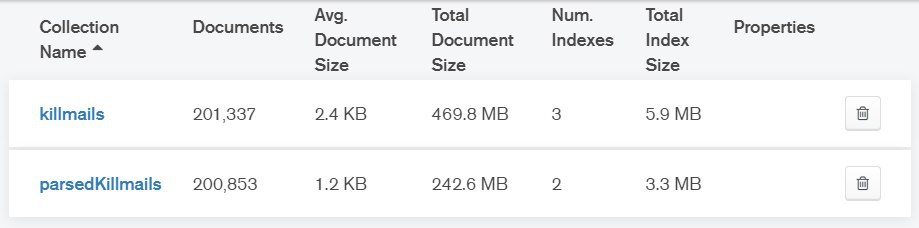 Roman
Roman
в первой еще uniq автоматический
Roman
во второй в качестве уника уже имеющееся поле
yopp
Второй момент: для корректного сравнения размера необходимо сделать дамп обеих коллекций и восстановить их с новыми именами или дропнуть и создать по новой
yopp
И сравнивать можно только в том случае если схемы вообще не менялись. Если схема поменялась или подменялся порядок ключей, то сравнение уже не будет корректным.
Roman
документы в этих коллекциях служат как статичные данные, не подразумевающие никаких правок
Roman
оригинальный
https://hastebin.com/gizubowujo.json
Roman
модифицированный
https://hastebin.com/duhutudidu.json
Roman
справедливости ради, 2 общих поля в документе были убраны и плюс один из массивов обьектов стал массивом массивов
Roman
плюс пара дат из строк переведены в таймштамп
Roman
нисколько не претендую на истину и совсем не хочу советовать кому либо, что либо.
предлагаю к этому относиться просто как к интересному факту.
и мой кейс был весьма специфичный и это не коммерческий проект.
в нормальном продакшене я в целом соглашусь с коллегой - овчинка выделки скорее всего не будет стоить.
yopp
нисколько не претендую на истину и совсем не хочу советовать кому либо, что либо.
предлагаю к этому относиться просто как к интересному факту.
и мой кейс был весьма специфичный и это не коммерческий проект.
в нормальном продакшене я в целом соглашусь с коллегой - овчинка выделки скорее всего не будет стоить.
По ссылке две разные схемы. Вывод о том, что длинна ключа является причиной наблюдаемых изменений — некорректен.
yopp
Второй момент, вы сравниваете размер документа, а не размер хранилища
yopp
Для корректного сравнения необходимо сравнить collStat в частности storageSize