~418 раз
и это без учёта компрессии :)
 yopp
yopp

 yopp
yopp
1 678 байт
yopp
ну тогда ещё лучше будет :)
 Anonymous
Anonymous
да
Anonymous
Anonymous
 Anonymous
Anonymous
если сделать экспорт - пустой массив
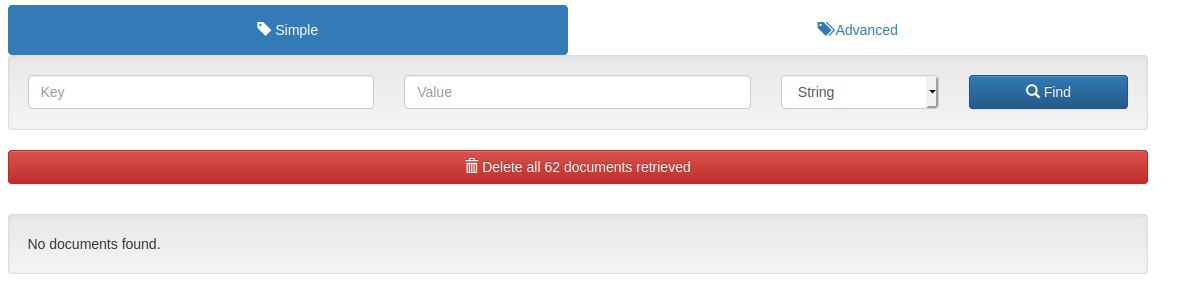
Collection Stats
Documents 62
но документов нет
yopp
если сделать экспорт - пустой массив
Collection Stats
Documents 62
но документов нет
Collection Stats может показывать устаревшие данные
Anonymous
Collection Stats может показывать устаревшие данные
спасибо, поищу как их мануально обновлять
yopp
Не использовать их
yopp
Это неточная метрика
yopp
Она показывает приблизительное число документов. Оно может совпадать с реальным числом, но это не гарантируется
yopp
Если вы хотите точно посчитать документы, используйте count
Anonymous
вот я count и использую, мне точное число не нужно, нужно грубо понимать, есть ли допустим не истекшие сессии, а он мне возвращает 62, а в коллекции документов(сессий) нет
yopp
Какая у вас версия монги?
yopp
Count вы где используете?
Anonymous
4.2.5
Anonymous
в логике приложения, python
yopp
Попробуйте вместо count использовать AF + $count
yopp
Возможно у вас драйвер вместо подсчета документов использует метаданные коллекции
Anonymous
спасибо, попробую
yopp
В новых драйверах по хорошему должно быть два метода countDocuments и estimatedDocuementsCount
yopp
Первый дергает агрегацию, второй читает метаданные
Anonymous
уже увидел, что count deprecated в пользу countDocuments, но драйвер не поддерживает countDocuments увы, так что попробую AF, спасибо
yopp
👌
Sam
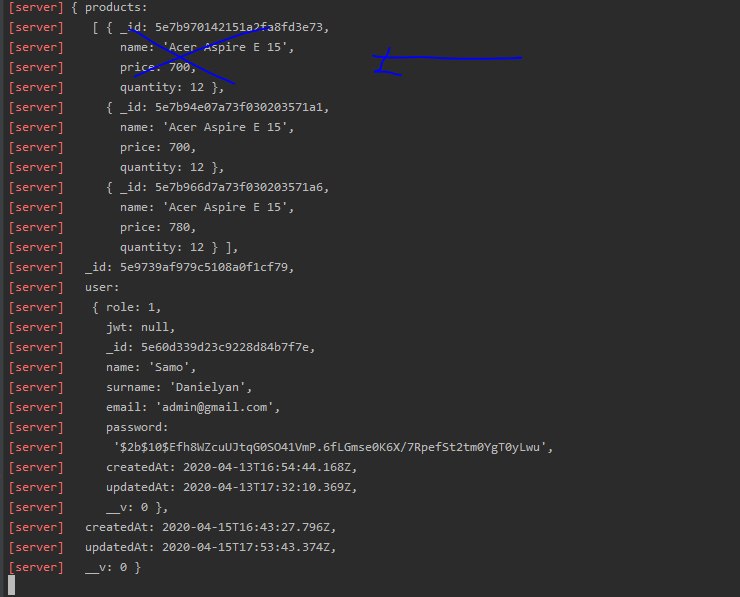
Wishlist.findOne().populate({path:'user',match: {_id:req.body.user_id}}).populate({path:'products',select:'name price quantity'})
Sam
 Sam
Sam
С этим запросом я вывожу это, но мне нужно чтоб я мог удалить один из продуктов, и так update базе как можно ?
Anonymous
А в чем бонус bulkWrite ?
Stepan
А в чем бонус bulkWrite ?
Ну допустим ты можешь заинсертить 100к документов одним запросом, а не делая 100к инсертов.
Anonymous
Ну допустим ты можешь заинсертить 100к документов одним запросом, а не делая 100к инсертов.
а если говорить про апдейт ?
Anonymous
создать 10 операций на апдейт:
этому документу поле А, этому - поле Б
в чем перформанс будет, если все равно нужно найти конкретный документ и обновить поле, в один запрос это не сложить
Stepan
А в том, что каждый запрос на апдейт это сетевое взаимодействие - послать запрос, получить результат. Для 10 операций перфоманса не будет, а вот для 100к уже ощутимо
Anonymous
а, про сеть не подумал, спасибо, выручаете уже в который раз
спасибо!
yopp
это может иметь какой-то эффект когда у вас большая частота запросов и сетевые задержки начинают быть заметны на фоне времени необходимого на выполнения запроса
yopp
А в том, что каждый запрос на апдейт это сетевое взаимодействие - послать запрос, получить результат. Для 10 операций перфоманса не будет, а вот для 100к уже ощутимо
вопрос скорее не в количестве операций, а во времени выполнения операций
yopp
если время запроса примерно одного порядка с сетевыми задержками, там есть какой-то смысл
Stepan
вопрос скорее не в количестве операций, а во времени выполнения операций
Я думаю, что оба фактора значимы. У меня есть кейсы когда надо обновить 300-400к объектов за раз. Сомневаюсь что bulkWrite не даст преимущества, даже если это мелкие апдейты
yopp
это сетевая оптимизация
yopp
т.е. приемущество будет зависеть исключительно от RTT
Stepan
Ну 300к запросов по сети, даже если они по 1мс, вроде как не кисло выходит)
Anonymous
Я думаю, что оба фактора значимы. У меня есть кейсы когда надо обновить 300-400к объектов за раз. Сомневаюсь что bulkWrite не даст преимущества, даже если это мелкие апдейты
я думаю, что устноавить коннекшн и сказать монге сделать что-то 400к раз будет немного хуже, чем отправить его 1
а еще ответ получить
Anonymous
но это не точно
yopp
«мало» это не абсолютная величина
yopp
если запрос по секунде, то это погрешность измерения
Stepan
«мало» это не абсолютная величина
С этим согласен. Но в данном случае 30 секунд весьма неприятны, и запросы намного быстрее секунды)
 Maka
Maka
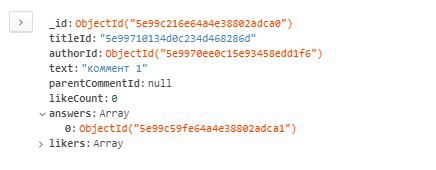
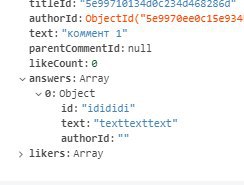
Привет всем, подскажите пожалуйста, у меня есть коллекция "комментарии" в ней хранятся документы типа: {_id, text, answers:[]}, где answers: массив id-шников комментариев-ответов, при этом все документы этих ответов лежат на том же уровне что и обычные комментарии, как можно получать вместо массива id-шников сразу массив объектов комментариев?
Maka
 Maka
Maka
 Maka
Maka
я знаю что можно просто хранить комментарии вложенно(хоть это и усложнит код), но с авторами так не получится, их имена тоже хотелось бы линковать с комментариями через id-шки
Maka
я нашел решение, спасибо
Anonymous
о всего доллар
Anonymous
коллеги, подскажите плиз более продвинутый способ бекапа без остановки, кроме дампа. если есть
 Vladimir
Vladimir
fsyncLock + rsync (хотя это не совсем без остановки)
или снэпшоты файловой системы
Anonymous
и бесплатных)
Anonymous
спасибо
Vladimir
https://github.com/wal-g/wal-g/ - тут вот потихоньку пилится более лучшая утилита для бэкапов, в том числе монги
Anonymous
yopp
коллеги, подскажите плиз более продвинутый способ бекапа без остановки, кроме дампа. если есть
hidden replica + fs snapshot
yopp
с журналом и wt
yopp
при условии что dbPath на одном разделе
 Andrey
Andrey
ребят, а find({_id: {$in: ids}}) производительней чем Promise.all(ids.map(id => findOne({_id: id}))) ?
Anonymous
 Anonymous
Anonymous
делать просто поле id, или это нарушает философию монги?)
Daniil
Daniil
ребят, а find({_id: {$in: ids}}) производительней чем Promise.all(ids.map(id => findOne({_id: id}))) ?
Т.к. findOne это find с limit = 1
Daniil
делать просто поле id, или это нарушает философию монги?)
Тут столько копий сломано про инкрементальные счетчики в монге в качестве идентификатора, можете поиском по чату почитать)
 Anton
Anton
Я понимаю, что вопрос глупый, но может ли между $or и $and кто-то быть быстрее?
Andrey
Т.к. findOne это find с limit = 1
понял, спасибо
я просто подумал, что мало ли тут история как с балками
yopp
ребят, а find({_id: {$in: ids}}) производительней чем Promise.all(ids.map(id => findOne({_id: id}))) ?
Разница только в количестве запросов и затрат на их сериализацию.
$in это синтаксический сахар к $or. В итоге у вас в запросе с $in[a, ... N] будет N обращений к хранилищу
yopp
Я понимаю, что вопрос глупый, но может ли между $or и $and кто-то быть быстрее?
Это логические условия сами по себе. В случае увеличения числа условий $and в уменьшает поле выбора а $or расширяет
yopp
 Slava
Slava
Доброго времени суток! Нужна помощь, пытаюсь с ноды подключиться к монго - коннекшн проходит (использовал урлу вида “mongodb://host:port/database”), но при записи выдает ошибку монго, что нужна аутентификация - начал авторизованно подключаться (mongodb://login:password@host:port/database), но нода перестала вообще подключаться к монго, пишет, что аутентификация не пройдена, хотя все верно.
Стартую монго через docker-compose:
mongo:
restart: always
container_name: musician-database
image: mongo:latest
environment:
MONGO_INITDB_ROOT_USERNAME: admin
MONGO_INITDB_ROOT_PASSWORD: password
volumes:
- ./data/:/data/db
Чтобы решить проблему, пробовал добавить следующий volume к образу (совет с гитлаба):
- ./data/mongo/001_users.js:/docker-entrypoint-initdb.d/001_users.js:ro
В нем создовал юзера с аксессом на readWrite и аналогичными логин-пароль.
Подключаюсь через mongoose, делаю это так:
mongoose
.connect(
`mongodb://admin:password@${process.env.MONGO_HOST}:${process.env.MONGO_PORT}/${process.env.MONGO_DATABASE}`,
{
useNewUrlParser: true,
useUnifiedTopology: true,
bufferMaxEntries: 0,
}
)
.catch(err => {
isError = true;
console.error(`Error connecting to mongodb, ${err}`);
});
Без аутентификации подключение устанавливалось успешно (понимал я это из then вернувшего промиса от mongoose), с аутентификацией then в промисе не отрабатывает, а вот error’ка с радостью
Помогите, пожалуйста, опытные люди, сам не знаю как дальше. Заранее спасибо!
 Sardor
Sardor
Всем привет! Православных с Пасхой:)
Имевшие дело с LifeRay, подскажите, пожалуйста, возможно ли его совместить с Монгой? Если да, как это сделать? Можете статью или какой-нибудь материал подкинуть?
На всех мануалах юзается mysql, а я бы хотел Монгу подцепить)