meta_id это «класс» метаданных: страны, возраст или ещё что-то
так а зачем мне это хранить в документе юзера, когда могу хранить fk для юзера в коллекции меты
 Anonymous
Anonymous


 yopp
yopp
он там и так хранится
yopp
но тогда вам надо будет делать пересечение
yopp
а это дорого
yopp
т.е вам надо будет пересечь два множества «пользователи» и «метрики»
Anonymous
а зачем мне это делать, напомни ?)
yopp
если там 500к пользователей это будет 500к*N
Anonymous
если ключ партишна уже максимально разряженный
yopp
абсолютно не важно
yopp
у вас в любом случае будет два огромных множества
yopp
как вы их не нарезайте :)
yopp
«кеширование» метаданных это фишка документных хранилищ, когда вы можете тонко настроить денормализацию под вашу задачу
Anonymous
пока не особо врубаюсь, зачем делать пересечения множество
Anonymous
если у меня будет коллекция с метой, то я могу сразу сматчить документ по нужным мне критериям
yopp
т.е. если хранить метаданных только в пользователе, то у вас получается выборка состоит из двух операций
yopp
выбрать из множества пользователей только тех, у кого есть страна А
yopp
пересечь множество метрик со значением из прошлой операции
yopp
отбросить из получившегося множества значения не удовлетворяющие фильтру
yopp
start_date, user_id, values.value
и meta.meta_id, meta.meta_value, start_date, user_id, values.value
^ а вот это, позволит не пересекать множество
yopp
потому что у нас индекс уже рассекает документы по метаданным
Anonymous
такс, я по ходу понял идею
то есть есть мета - это массив каких-то данных с fk и мета велью, которая является сетом из Set{A,B,C}
Anonymous
праильна ?
yopp
meta_keys:
{
_id: OID(1),
name: "Country",
...
}
{
_id: OID(2),
name: "Age",
...
}
metrics:
{
_id: OID(1),
name: "Running Distance"
}
users:
{
_id: OID(1),
password_kdf_hash: ...
...
meta: [
{
_id: OID(1),
value: "US"
},
{
_id: OID(2),
value: 42
}
]
}
metrics_values:
{
metric_id: OID(1),
user_id: OID(1),
start_date: ISODate("2020-01-01"),
end_date: ISODate("2020-01-31"),
// copy from user
meta: [
{
_id: OID(1),
value: "US"
},
{
_id: OID(2),
value: 42
}
]
values: [
{
date: ISODate("2020-01-01"),
value: 12.5
}
...
]
}
Anonymous
второе - как будет выглядеть запрос ? мне надо будет каждый раз обращаться к metrcs_values.metric.name = ‘Country’ ?
yopp
а зачем копировать meta и в юзера и в meterics_values ?
чтоб когда в выборке есть мета-данные, не надо было пересекать их с пользователями
yopp
второе - как будет выглядеть запрос ? мне надо будет каждый раз обращаться к metrcs_values.metric.name = ‘Country’ ?
да, два запроса, но это абсолютно нерелеватно
yopp
можно и вместо ObjectId строки использовать
yopp
но я за _id в таких случаях
Anonymous
то есть в случае когда мне нужно найти пользователя по стране А, это будет N+1
yopp
почему?
Anonymous
ну мне ведь в другую коллекцию надо сходить и узнать, что за metrcis_id
yopp
это не будет N+1, это будет статически ровно 2 запроса
yopp
там нет N :)
Anonymous
ну в смысле нет ?)
я беру первый документ metrics_values - иду в поле meta, потом по pk иду в коллекцию meta_keys ипроверяю что это == ‘Country’
Anonymous
и так для каждого докоумента
yopp
нет
Сароар🧑🏼🦱
anyone know english group for MongoDB
Сароар🧑🏼🦱
i need some help
yopp
Yep:
yopp
https://t.me/mongo_db
yopp
ну в смысле нет ?)
я беру первый документ metrics_values - иду в поле meta, потом по pk иду в коллекцию meta_keys ипроверяю что это == ‘Country’
вы выбираете meta_keys.name == «Country»
yopp
и следующим запросом в условии используете metric._id == OID
yopp
если у вас нет метаданных с большой вариабильностью, то можно сразу пары хранить
Anonymous
тогда какой смысл от meta_keys если я могу сразу хранить статику ?
Anonymous
и делать 1 запрос вместо 2
Anonymous
что даст мне как минимум простоту написания кода запроса из приложения
yopp
уменьшить размер индекса
yopp
если у вас нет метаданных с большой вариабильностью, то можно сразу пары хранить
^ вот это идеальный вариант
Anonymous
под парой подразумевается { meta_type: ‘kek, value: “shpek” } ?)
Anonymous
без фореинг кеев ?
yopp
тогда вы храните
meta_keys:
{
_id: OID(1),
name: "Country",
value: "US"
}
{
_id: OID(2),
name: "Age",
value: 42
}
users:
{
_id: OID(1),
password_kdf_hash: ...
...
meta: [OID(1), OID(2)]
}
metrics_values:
{
metric_id: OID(1),
user_id: OID(1),
start_date: ISODate("2020-01-01"),
end_date: ISODate("2020-01-31"),
// copy from user
meta: [OID(1), OID(2)]
values: [
{
date: ISODate("2020-01-01"),
value: 12.5
}
...
]
}
yopp
но есть минус
yopp
выборка по диапазону значений мета-данных будет сложнее
yopp
по этому я считаю что meta_id, meta_value самый разумный вариант
Anonymous
meta_keys:
{
_id: OID(1),
name: "Country",
...
}
{
_id: OID(2),
name: "Age",
...
}
metrics:
{
_id: OID(1),
name: "Running Distance"
}
users:
{
_id: OID(1),
password_kdf_hash: ...
...
meta: [
{
_id: OID(1),
value: "US"
},
{
_id: OID(2),
value: 42
}
]
}
metrics_values:
{
metric_id: OID(1),
user_id: OID(1),
start_date: ISODate("2020-01-01"),
end_date: ISODate("2020-01-31"),
// copy from user
meta: [
{
_id: OID(1),
value: "US"
},
{
_id: OID(2),
value: 42
}
]
values: [
{
date: ISODate("2020-01-01"),
value: 12.5
}
...
]
}
а не кажется ли странным хранить при партишне в месяц каждый раз страну/пол и другие статические данные ?
yopp
нет
Anonymous
и второе - есть ли что-то готовое при таком подходе партицирования ?
yopp
и второе - есть ли что-то готовое при таком подходе партицирования ?
смотря что значит «готовое»
yopp
кстати, про странности
Anonymous
смотря что значит «готовое»
ну тип мне нужно будет самому каждый раз создавать такие “партиции” переносят туда поля из основй коллекции
yopp
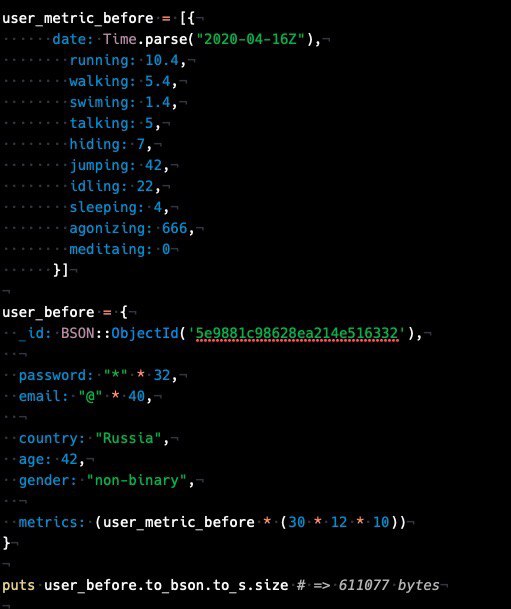
немного математики. у меня модельный пользователь с 10 годами данных получился размером в 611077 байт
yopp
 yopp
yopp
метрика на 30 дней получилась 1361 байт, итого за 10 лет выйдет 163 320 байт
yopp
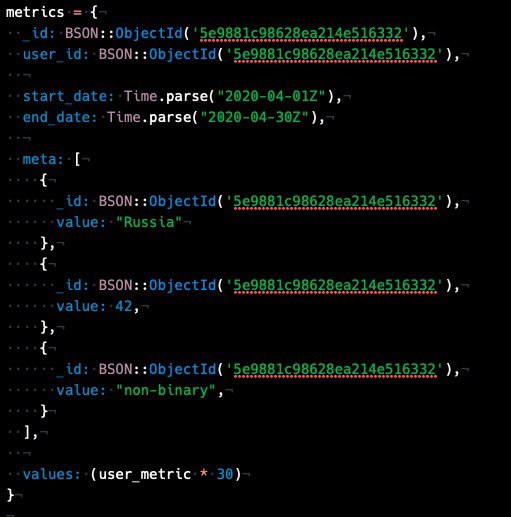 yopp
yopp
ой, забыл _id метрики
yopp
1384 байт
yopp
166 080 или на 10 метрик выходит 1 660 800
yopp
но
yopp
теперь попробуем прикинуть объёмы данных необходимых для построения аналитики
yopp
если надо выбрать данные по 500к пользователям по 1 метрике за 1 месяц, то нам надо будет прочитать и обрабатать 611077*500000 = 291Gb
yopp
в оригинальной схеме
yopp
в новой схеме 1384*500000 = 659Мб
yopp
~418 раз
Anonymous
если надо выбрать данные по 500к пользователям по 1 метрике за 1 месяц, то нам надо будет прочитать и обрабатать 611077*500000 = 291Gb
вот кстати возвращаясь к разговору про селективность
я ведь на уровне индекс скана могу ее уменьшить и вообще не ходить в документ, ведь так ?
Anonymous
в общем, я идею понял, спасибо большое!
сорьки за флуд если что