 yopp
yopp


В остальном чтение с реплик не самая надёжная история и первый вопрос почему вы хотите с них читатать
 Serg
Serg
ну небольшое отставание в пару минут допустимо
Serg
You have to set "slave okay" mode to let the mongo shell know that you're allowing reads from a secondary. This is to protect you and your applications from performing eventually consistent reads by accident. You can do this in the shell with:
rs.slaveOk()
After that you can query normally from secondaries.
 Dmitriy
yopp
Dmitriy
yopp
You have to set "slave okay" mode to let the mongo shell know that you're allowing reads from a secondary. This is to protect you and your applications from performing eventually consistent reads by accident. You can do this in the shell with:
rs.slaveOk()
After that you can query normally from secondaries.
В запросе лучше установить readPreferrence
Alexander
построение индексов не меняет данные
а это долгая операция? 2M+ делаю индекс из 3 полей с весами, жду уже прилично))
Daniil
а это долгая операция? 2M+ делаю индекс из 3 полей с весами, жду уже прилично))
Зависит от кол-ва документов и железа, при вашем объеме довольно долгая)
Daniil
background: true есть для создания индексов
Alexander
эх, спасибо, жду....)
 Semyon V
Semyon V
Ни с того ни с сего, $match по регулярке стал занимать несусветное количество времени (0.8-1.5 секунды для 100000 документов). индесы на месте, перестроил их даже. на реплике тот же запрос выполняется моментально. в чём может быть дело?
yopp
Ни с того ни с сего, $match по регулярке стал занимать несусветное количество времени (0.8-1.5 секунды для 100000 документов). индесы на месте, перестроил их даже. на реплике тот же запрос выполняется моментально. в чём может быть дело?
См. explain(executionStats: 1), возможно планировщик изменил план. И проверьте что регулярное выражение начинается с «префиксного» якоря ^ или \A
 Max
Max
Всем доброго, пытаюсь использовать ID пользователя от Firebase как ключ документа, но пишет следущее, какие варианты решения есть у этой проблемы?
Identifier: ffUKlP2cQMX0dHYQwSW0TVv9VFk1
(node:27) UnhandledPromiseRejectionWarning: Error: Argument passed in must be a single String of 12 bytes or a string of 24 hex characters
Daniil
Всем доброго, пытаюсь использовать ID пользователя от Firebase как ключ документа, но пишет следущее, какие варианты решения есть у этой проблемы?
Identifier: ffUKlP2cQMX0dHYQwSW0TVv9VFk1
(node:27) UnhandledPromiseRejectionWarning: Error: Argument passed in must be a single String of 12 bytes or a string of 24 hex characters
Стоит хранить айдишник firebase отдельным строковым полем, например firebaseId
Max
Стоит хранить айдишник firebase отдельным строковым полем, например firebaseId
О, спасибо большое)
Alexander
Зависит от кол-ва документов и железа, при вашем объеме довольно долгая)
Ближе к ночи завершилась индексация, начал пробовать поиск, докер рестартится, в логах хоста Out of memory: Kill process
Alexander
Daniil
Ближе к ночи завершилась индексация, начал пробовать поиск, докер рестартится, в логах хоста Out of memory: Kill process
а сколько памяти доступно для монги?
Alexander
4.915GiB / 11.58GiB
Alexander
Думаю индексацию переделать с 3 полей до 2...)
Alexander
Но опять на полдня работа встанет...
Alexander
4.915GiB / 11.58GiB
это вывод docker ps -q | xargs docker stats --no-stream, надеюсь туда смотрю..
yopp
Ближе к ночи завершилась индексация, начал пробовать поиск, докер рестартится, в логах хоста Out of memory: Kill process
Если монга в контейнере укажите ей максимальный объём памяти под кэш
https://docs.mongodb.com/manual/core/wiredtiger/#memory-use
https://docs.mongodb.com/manual/reference/configuration-options/#storage.wiredTiger.engineConfig.cacheSizeGB
Alexander
О, ща посмотрим
Alexander
спасибо
Alexander
типа рестартануть контейнер с --wiredTigerCacheSizeGB=<?>
Serg
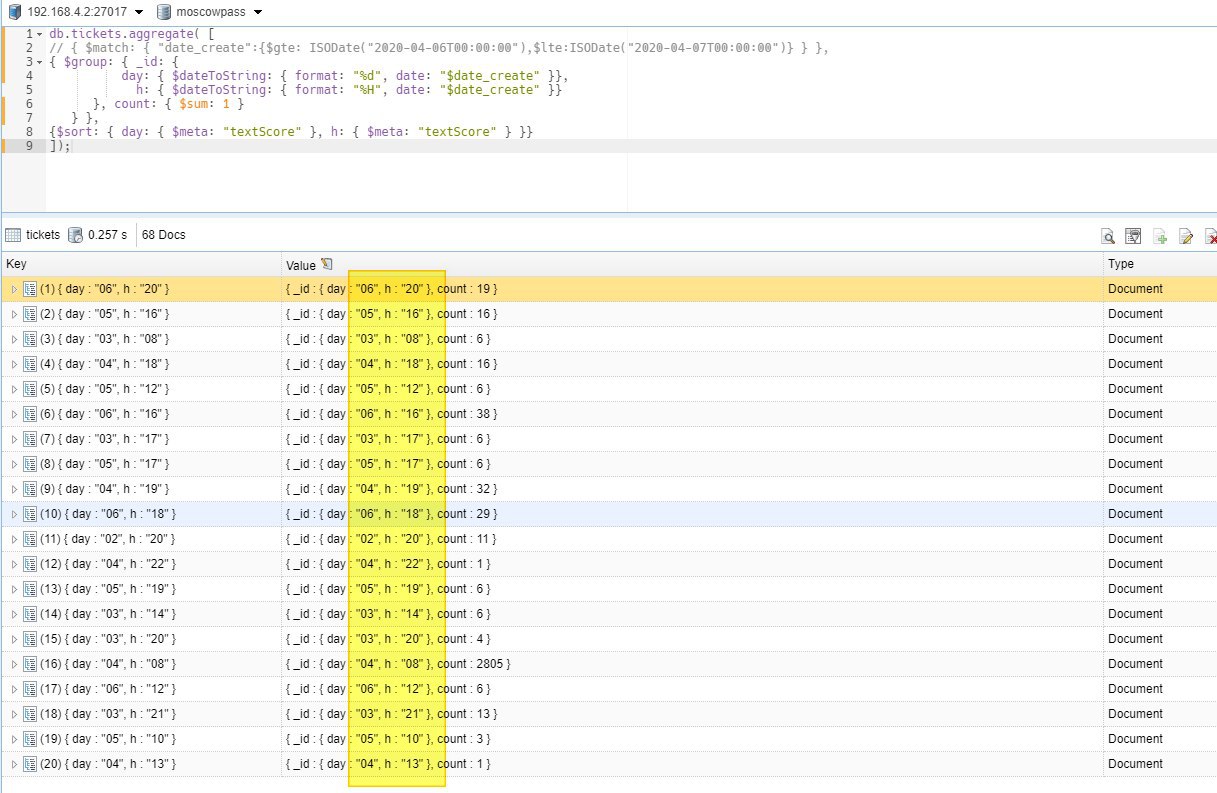
db.tickets.aggregate( [
// { $match: { "date_create":{$gte: ISODate("2020-04-06T00:00:00"),$lte:ISODate("2020-04-07T00:00:00")} } },
{ $group: { _id: {
day: { $dateToString: { format: "%d", date: "$date_create" }},
h: { $dateToString: { format: "%H", date: "$date_create" }}
}, count: { $sum: 1 }
} },
{$sort: { day: { $meta: "textScore" }, h: { $meta: "textScore" } }}
]);
подскажите плиз, как отсортировать агрегированный набор по атрибутам день, час. ? нужно посчитать количество документов созданных за час в указанном периоде
Serg
сортировака выглядит как-то не отсортированой
Serg
 yopp
yopp
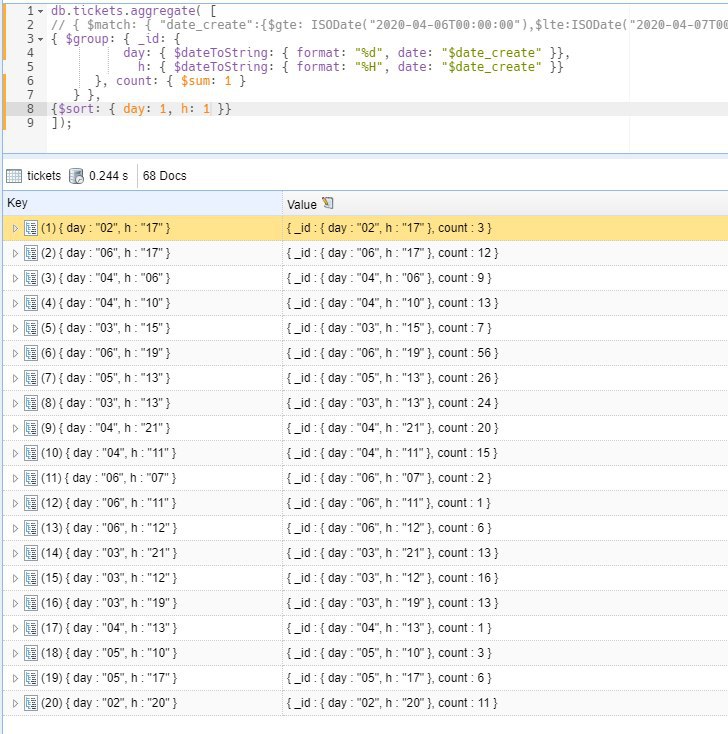
А, а зачем у вас там в правилах сортировки $meta? Укажите day: 1, h: 1
Serg
 yopp
Serg
yopp
Serg
да, теперь правильно сортирует. спасибо
Serg
и ведь я пробовал так написать но в кавычки обернуть не догадался
 Albert
Albert
Приветствую. Имеется две коллекции, схема первой известна, схема второй - нет. Возможно ли каким-либо образом из функции aggregate первой коллекции вытащить данные второй коллекции?
Что-либо по типу операции UNION из SQL
yopp
Приветствую. Имеется две коллекции, схема первой известна, схема второй - нет. Возможно ли каким-либо образом из функции aggregate первой коллекции вытащить данные второй коллекции?
Что-либо по типу операции UNION из SQL
https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/
Albert
{
"$lookup": {
"from": "second",
"let": {},
"pipeline": [{
"$match": {}
}],
"as": "second"
}
}
Ну вот я написал lookup на вторую коллекцию, но тем не менее, у меня во второй раз дублируется содержимое первой коллекции. ЧЯДНТ?
yopp
{
"$lookup": {
"from": "second",
"let": {},
"pipeline": [{
"$match": {}
}],
"as": "second"
}
}
Ну вот я написал lookup на вторую коллекцию, но тем не менее, у меня во второй раз дублируется содержимое первой коллекции. ЧЯДНТ?
Вы не указали условие в $match по которому объединять первую коллекцию со второй
Albert
Я могу сделать так, чтобы оно в это поле загружало просто все, что возможно?
yopp
Не очень понимаю какой результат вы хотите получить. Можете показать короткий пример по 3 документа в каждой коллекции и желаемый результат?
Albert
В каждом элементе первой коллекции, в отдельном поле, находится все содержимое второй коллекции, грубо говоря
Albert
Сейчс попробую что-нибудь наваять
Artem
есть параметр --logpath <path>, запуска монги
в каких случаях в лог записываются запросы которые выполняються
Artem
?
Artem
не кто не подскажет
Daniil
есть параметр --logpath <path>, запуска монги
в каких случаях в лог записываются запросы которые выполняються
https://docs.mongodb.com/manual/reference/configuration-options/#systemLog.component.query.verbosity
yopp
есть параметр --logpath <path>, запуска монги
в каких случаях в лог записываются запросы которые выполняються
Там несколько параметров. По-моему есть ручка которая крутит уровни логгирования для компонентов, потом есть slowLog
Daniil
есть параметр --logpath <path>, запуска монги
в каких случаях в лог записываются запросы которые выполняються
https://docs.mongodb.com/manual/reference/log-messages/#components
Artem
Я поставил уровень лога 0 http://i.imgur.com/sg98Cex.png
Artem
http://i.imgur.com/eGnlvqM.png
Artem
но по прежнему получаю сообщения в лог
yopp
но по прежнему получаю сообщения в лог
https://docs.mongodb.com/manual/reference/log-messages/#logging-slow-operations
 Artem
Artem
Всем привет. Такой вопрос, есть убогая структура, где в списке документа хранятся словари. Вопрос, как можно обновить значение этого словаря?
Artem
Искал в интернете, но ничего подходящего не нашёл.
 Nick
Nick
Всем привет. Такой вопрос, есть убогая структура, где в списке документа хранятся словари. Вопрос, как можно обновить значение этого словаря?
нужен схематичный пример, а то не ясно какая структура
 Aleksey
Aleksey
Нужна пагинация по _id сортировка с конца и включая запрос (фильтр), как оптимально сделать ? Отлично если есть пример на pymongo, или просто описание подхода.
Artem
такой вопрос, mongodb сильно использует диск на чтение а оператива практически гуляет
Artem
как можно подтюнить монгу
Artem
?
 Amirbek
Amirbek
 Amirbek
Amirbek
вечер добрый всем
Amirbek
вот такой ошибка
Amirbek
как решить можете помочь
Amirbek
такой вопрос, mongodb сильно использует диск на чтение а оператива практически гуляет
у вас тоже та проблема ?
Artem
У меня проблема заключается в том что частые запросы на индекс на выборку по диапазону, в коллекцие много данных, из за этого на серваке проц по нулях, оперативы полно но диск в утиль, может есть какие либо параметры настройки монги что бы уакзать типо юзай больше оперативы для кеша или того типо
Amirbek
мммм в моем случии че делать знайте ?
Artem
Не понял?
Amirbek
Artem
Я тут не помогу, я за Windows последний раз седел года 4 тому
 Nikita
Nikita
Всем привет
Код на Kotlin, используется KMongo
Есть простая схема
class User (
@BsonId
val _id: Id<User> = newId(),
val name: String
)
Записываю в базу и хочу получить id через users.insertOne(User(name = "name1")).insertedId
но оно null, хотя запись создана
 Hellomik
Hellomik
хай в чем разница запуска mongo через
systemctl start mongodb(скачан через apt) и
systemctl start mongod (как в доке)
yopp
Всем привет
Код на Kotlin, используется KMongo
Есть простая схема
class User (
@BsonId
val _id: Id<User> = newId(),
val name: String
)
Записываю в базу и хочу получить id через users.insertOne(User(name = "name1")).insertedId
но оно null, хотя запись создана
Можете _id на стороне клиента генерировать
yopp
У меня проблема заключается в том что частые запросы на индекс на выборку по диапазону, в коллекцие много данных, из за этого на серваке проц по нулях, оперативы полно но диск в утиль, может есть какие либо параметры настройки монги что бы уакзать типо юзай больше оперативы для кеша или того типо
Зависит от ситуации.
Отдавать под кеш больше чем половина доступной памяти особого смысла нет. Так как в памяти страницы хранятся без сжатия, и сжимаются только при сбросе на диск. Так как стиснув сначала ещё и в дисковый кеш попадают, то увеличив размер кеша, объём документов который помещается в памяти наоборот уменьшится.
В случае если компрессия не используется разницы
Albert
Господа, имеется две коллекции:
Коллекция 1:
[{ "_id": <id>, "name": <name>}, ...}]
Коллекция 2:
[{"_id": <id>, "login": <login>, ...}]
Вопрос такой, как мне корректно сделать так, чтобы в новом поле каждого элемента коллекции 1 была вся коллекция 2? Т.е.:
[{
"_id": <id>,
"name": <name>,
"collection2": [{"_id": <id>, "login": <login>}, ..]
}, ...]
yopp
Господа, имеется две коллекции:
Коллекция 1:
[{ "_id": <id>, "name": <name>}, ...}]
Коллекция 2:
[{"_id": <id>, "login": <login>, ...}]
Вопрос такой, как мне корректно сделать так, чтобы в новом поле каждого элемента коллекции 1 была вся коллекция 2? Т.е.:
[{
"_id": <id>,
"name": <name>,
"collection2": [{"_id": <id>, "login": <login>}, ..]
}, ...]
То что вы выше предлагали должно работать. А что у вас в результате получается?
Albert
То что вы выше предлагали должно работать. А что у вас в результате получается?
Пардон, забыл отписать, запрос нормально отработал, проблема не корректного результата была в базе
yopp
Попробуйте сначала сложить в поле в корне документа, а потом если потребуется в проекции сложите их а подокумент