 Alexander
Alexander

 Alexander
Alexander
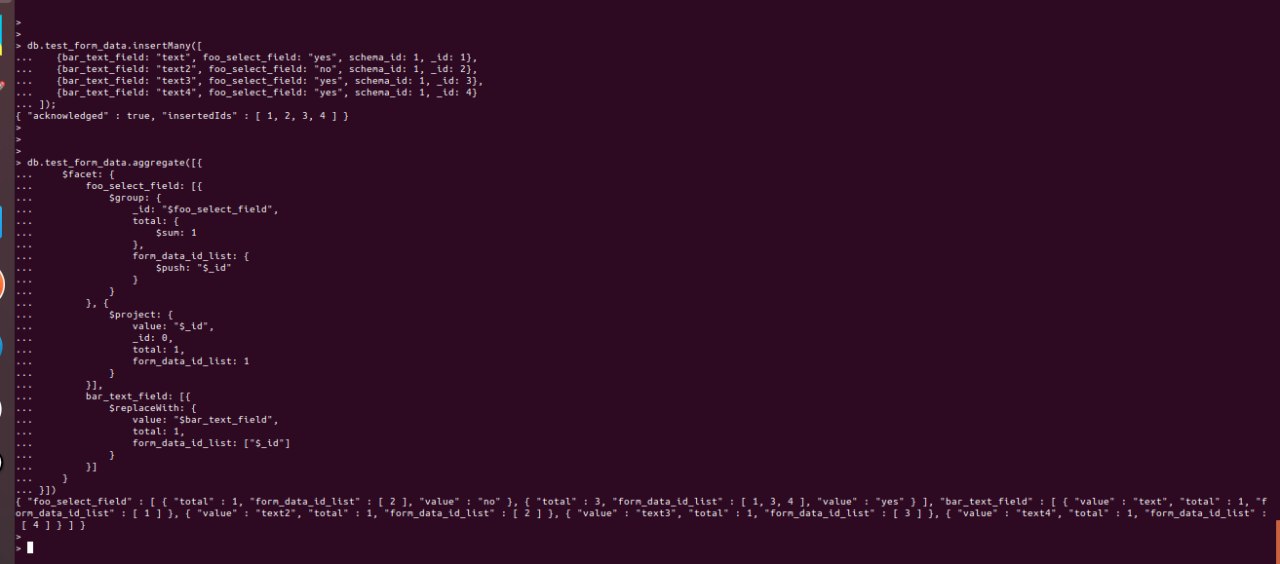
Нагуглил, что $group не использует индексы
https://stackoverflow.com/questions/20455752/mongodb-aggregation-framework-does-group-use-index
Видимо, индекс по каждому полю заполнения бесполезен в моем случае
Alexander
 Sergey
Sergey
У меня схожий проект. Нужно собирать данные с разных форм в MongoDB.
Был выбор — собирать в одну коллекцию (для того MongoDB и был выбран, что он позволяет разноструктурные данные хранить в одной коллекции),
или хранить данные каждой формы в отдельной коллекции. Выбрал второй вариант.
Сейчас имею порядка 50 коллекций с похожими структурами документов, но в каждой коллекции структкра строгая.
Из плюсов — индексация, поиск, автономия (отключили источник — удалил коллекцию).
Из минусов — когда просят сделать общую аналитику — приходится «джойнить» коллекции.
 Serzhi
Serzhi
Всем привет!
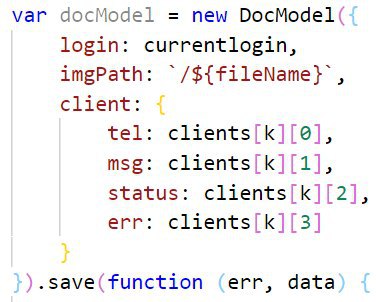
Может кто-нибудь приблизительно сказать на сколько ускорится запись в mongodb, если её делать напрямую, а не через модель в mongoose? Где-то можно прочитать инфу на эту тему?
Модель простенькая :
Serzhi
 Sergey
Sergey
Привет. Не проще это проверить самостоятельно? Возможно, ваше окружение даст иные результаты, чем те, которые вы найдёте где-то?
Serzhi
Привет. Не проще это проверить самостоятельно? Возможно, ваше окружение даст иные результаты, чем те, которые вы найдёте где-то?
С монго знаком очень мало, потому не проще. Предположил, что может кто-то уже рассматривал подобный вопрос пусть даже с другой моделью. .
 Josh
Josh
на 0.243% примерно
 Dmitriy
Dmitriy
- штурман приборы
- 660
- что 660?
- а что приборы?
напомнило)
Sergey
С монго знаком очень мало, потому не проще. Предположил, что может кто-то уже рассматривал подобный вопрос пусть даже с другой моделью. .
Тут знания MongoDB сильно не нужны.
Раз вы заговорили про ORM Mongoose, значит в состоянии создать одну простую модель (вы её уже создали (на снимке экрана)).
Напишите в отдельном файле кусок кода, который через эту модель «насуёт» 100500 документов в MongoDB. Замерьте время, нагрузку, память и т. д.
После этого в другом файле сделайте прямое подключение к MongoDB и загрузите эти 100500 документов в соседнюю коллекцию. Сравните время.
Если в процессе возникнут вопросы — смело задавайте здесь. Опосля будет круто, если на Хабре появится статья от вас по производительности записи ORM vs Direct.
 Alexander
Alexander
привет. Подскажите пожалуйста, MongoDB Enterprise Server возможно вообще установить на не LTS версии Ubuntu? А именно на Ubuntu 19.10 x64?
 Иван
Иван
 Vova
Иван
Vova
Иван
Пишу запрос из приложения, а query для бд. Чтобы запрос отработал на стороне бд
Vova
Пишу запрос из приложения, а query для бд. Чтобы запрос отработал на стороне бд
Сделай чтобы поле было чисельное, а не строка
Vova
Всё просто
Иван
Если бы). По Это поле вводит пользователь и оно может быть либо числовым либо строковым, т.е. "10" ли "десять"(
Иван
В сети есть такой запрос на шарпах
db.MyCollection.find({ $where: "parseInt(this.Price) <= 1000" })
но, как его применить к query не знаю
Vova
Если бы). По Это поле вводит пользователь и оно может быть либо числовым либо строковым, т.е. "10" ли "десять"(
Ты "десять" в число как переводить собрался?
Vova
Тут нужно машинное обучение чтобы число в любом виде принять
Vova
Или сервис какой-то
Иван
Не буду переводить это для отображения
Vova
Так а ты не сможешь число к строке приравнять
Vova
Оно тебе ошибку выкинет
Vova
К строке имею ввиду к нечисельным символам
Dmitriy
Иван
что вам требуется в конечном счете сделать, сделать выборку по базе по равенству числа из приложения?
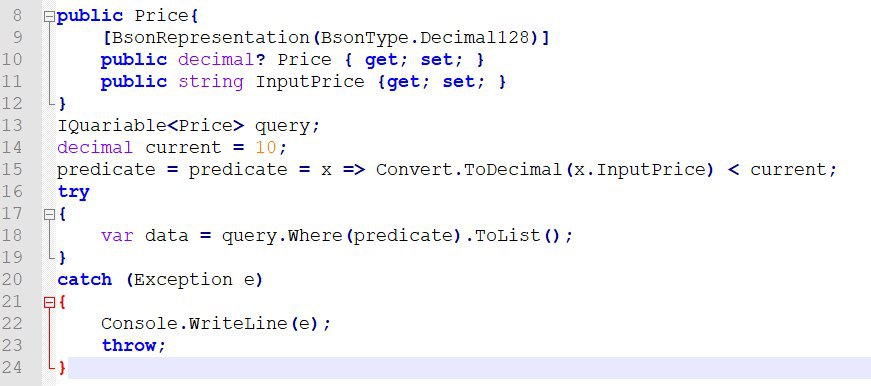
Да, нужно на стороне бд преобразовать строку к числу и если это число по условию вытащить модель. Есть возможность TryParce на стороне монги?
Dmitriy
Да, нужно на стороне бд преобразовать строку к числу и если это число по условию вытащить модель. Есть возможность TryParce на стороне монги?
чисто теоретически вы конечно можете сделать это на стороне монги: https://docs.mongodb.com/manual/reference/operator/aggregation/toDecimal/ использовав агрегацию и приобразования типов в ней. но мой вам совет откажитесь сразу от такой идеи, вам проще приобразовать значение к decimal на стороне приложения и сделать простую выборку из базы
Vova
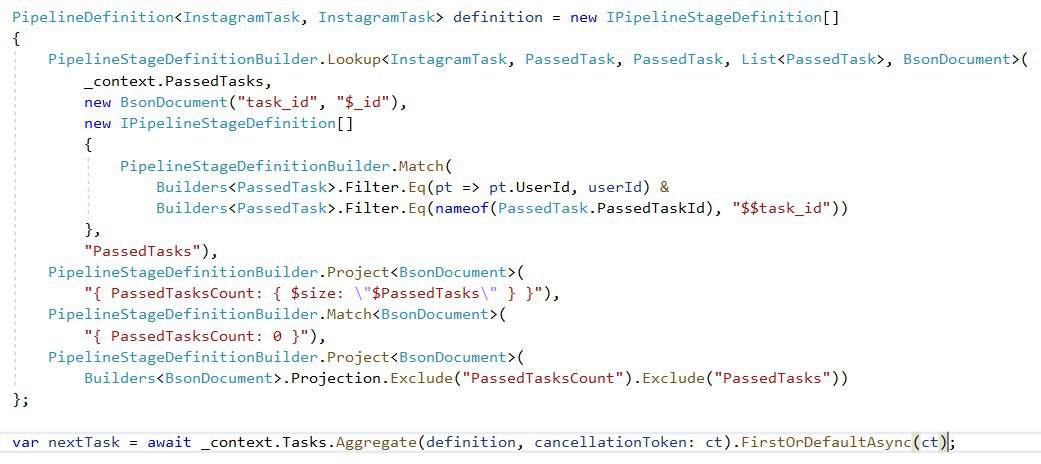
Там есть специальный класс, он ещё не задокументирован
Vova
 Vova
Vova
Это из монги 4.2 фича
Иван
чисто теоретически вы конечно можете сделать это на стороне монги: https://docs.mongodb.com/manual/reference/operator/aggregation/toDecimal/ использовав агрегацию и приобразования типов в ней. но мой вам совет откажитесь сразу от такой идеи, вам проще приобразовать значение к decimal на стороне приложения и сделать простую выборку из базы
Спасибо за статью, изучу!
Уже вытаскивал данные на машине - получил переполнение оперативнной памяти
Иван
Vova
Только вместо вызова Aggregate на создавать ProjectionUpdateDefinition или как он там называется...
Vova
А, забейте, это же выборка, обновлять ничего не надо
 hostmit
hostmit
Я могу увеличить лимит на ?
Pipeline stages have a limit of 100 MiB (100 * 1024 * 1024 bytes) of RAM. If a stage exceeds this limit, MongoDB will produce an error.
 Назар
Назар
Допустим есть документ, которому я хочу задать поле, у элемента массива внутри. Но этого массива и элемента может еще не быть. Как сделать, чтоб если его нет, то создать? Без проверок естественно
 Igor
Igor
всем привет, как делаете транзакцию на монго версией ниже 4 ?
Alex
всем привет, как делаете транзакцию на монго версией ниже 4 ?
А там разве есть транзакции из коробки?
 Дмитрий
Дмитрий
всем привет
может у кого есть достаточно большой опыт работы с aggregation и может ответить на такой вопрос
есть коллекция, в ней 850 тыс документов, по индексу выбирается около 550 тыс, дальше идет степ агрегации
агрегация занимает около 3 секунд (как по мне это долго) можно ли как то разогнать ее? может кто-то тюнил такие запросы
и нормально ли это время для него(aggregation)?
Igor
А там разве есть транзакции из коробки?
В 4.0 есть, но до этого не было. Вот интересно как решали вопрос
 Slava
Slava
всем привет, как делаете транзакцию на монго версией ниже 4 ?
Привет, можно сделать с помощью двух фазного коммита
Dmitriy
всем привет
может у кого есть достаточно большой опыт работы с aggregation и может ответить на такой вопрос
есть коллекция, в ней 850 тыс документов, по индексу выбирается около 550 тыс, дальше идет степ агрегации
агрегация занимает около 3 секунд (как по мне это долго) можно ли как то разогнать ее? может кто-то тюнил такие запросы
и нормально ли это время для него(aggregation)?
а что эксплейн показывает на эту агрегацию?
Дмитрий
меня смущает часто еще такое что
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "qc-pricing-api.costs",
"indexFilterSet" : false,
"parsedQuery" : {
Дмитрий
почему пишет что не использует индекс, когда он его потом в winning plan показывает
 Nick
Nick
почему пишет что не использует индекс, когда он его потом в winning plan показывает
stage IXSCAN есть значит используется индекс
Sergey
Никто не сталкивался с аналогичной русскоговорящей группой в Телеграм по MySQL?
Дмитрий
stage IXSCAN есть значит используется индекс
пишет уже в winnigPlans а выше, где я приводил пример "indexFilterSet" : false, показывает что не ищет
в общем либо я не понимаю что это значит, либо они что-то намудрили
так же вижу, что по группе не используется индекс, в документации об этом не пишут
Гена
Коллеги добрый день
Кто-нибудь настраивал Mongo Exporter для прометеуса + графана?
Nick
пишет уже в winnigPlans а выше, где я приводил пример "indexFilterSet" : false, показывает что не ищет
в общем либо я не понимаю что это значит, либо они что-то намудрили
так же вижу, что по группе не используется индекс, в документации об этом не пишут
по описанию в доке эта опция просто говорит о наличие хинта, его игнорирования и соответвия запроса имеющему индексу - и все это по сути для копания в планировщике - для вас важно что по индексу у вас 550к доков и их все тащат с диска
Nick
и потом почти на две секунды в группировке
Дмитрий
по идее группировка в памяти идёт и не должна занимать аж 2 секунды
так же пробовал запустить монгу в In-Memory режиме, но прироста почти не получил, порядка 15%
Дмитрий
это так монга работает и с ней ничего не сделать или может есть какие лайфхаки что бы побороть и ускорить ее(монги) работу?
 Алмаз
Алмаз
Всем привет! У меня возник паралелльный вопрос по https://t.me/MongoDBRussian/68162
Если на основе агрегации создать view, то это даст прирост производительности? Или все созданные view это виртуально - при каждом обращении происходит вычисления и потом запрос к ним? Или же реально в БД создается аля такие коллекции и обращения уже идут к ним?
 yopp
yopp
Всем привет! У меня возник паралелльный вопрос по https://t.me/MongoDBRussian/68162
Если на основе агрегации создать view, то это даст прирост производительности? Или все созданные view это виртуально - при каждом обращении происходит вычисления и потом запрос к ним? Или же реально в БД создается аля такие коллекции и обращения уже идут к ним?
Вью эфемерные, это не отдельная коллекция.
Алмаз
Вью эфемерные, это не отдельная коллекция.
Спасибо не знал. Прочитал еще инфу здесь - https://dzone.com/articles/taking-a-look-at-mongodb-views . Теперь буду осторжнее пользоваться этой возможностью. Больше пользы для визуального представления админу, а не приложению.
yopp
у вас агрегациях с allowDiskUsage выполняется?
Дмитрий
нет
Дмитрий
без
Дмитрий
2 степа, match и group
Дмитрий
Для 330мб данных, это в целом неплохой результат
реляционки тут конечно выигрывают, есть повод задуматься, данных будет больше и тогда вообще будет зашкаливать время ответа
yopp
Дмитрий
насколько читал, пока aggregation framework сыроват
yopp
Это недостоверная информация
yopp
Почему эта агрегация для вас является проблемой?