Не понял что нужно
Если по другому сказать, то если $lookup дал результат по критериям, то документ верхнего уровня оставить, если нет - убрать
 Illia
Illia


 Nick
Nick
Если правильно понял, то вам еще стейдж проджект нужен чтобы вытащить первый док
Illia
https://share.getcloudapp.com/12u1q5Ev
Illia
но я не совсем понимаю, как применить фильтраци ко всей выборкепо значению поля events.
Oleksandr
Здравствуйте,
Подскажите, пожалуйста, как правильно делать бекапы баз в MongoDB, при использовании ReplicaSet?
В моем случае есть 3 MongoDB сервера, MongoDB 4.2. Размер баз 40 ГБ.
Я поискал информацию в интернете, увидел что есть разные варианты, в частности один из самых простых: добавить в crontab строки (ниже) и запускать по расписанию в самое ненагруженное время (условно ночью).
sudo mongodump --db newdb --gzip --archive=/var/backups/mongobackups/date +"%m-%d-%y"
find /var/backups/mongobackups/ -mtime +7 -exec rm -rf {} \;
Запускать его на Primary?
———————-
Вариант с LVM снапшотами я не рассматривал, так как LVM сейчас не настроен, и я ещё не разу не пробовал делать снапшоты LVM. Вариант с копированием файлов (и использованием > db.fsyncLock() и > db.fsyncUnlock() не совсем понял как использовать, и есть ли плюсы в моем случае. Копирование файлов быстрее, но так как в моем случае размер баз маленький, mongodump будет проще?
Гена
Так вы добьётесь консистентности дампа
Oleksandr
Спасибо 😉
Гена
Смотрите, когда выгорите лок, то он ноде даёт значение 1, а когда вы сделаете анлок - то 0. Но, если вдруг у вас был рестарт сервера или по каким-то другим причинам пофейлился бекап, и значение лока осталось 1, то после следующего рана если пробежит снова до, то значение будет уже 2. Поэтому в скрипт имеет смысл добавить функцию анлока в начале, на всякий случай
Oleksandr
Я нашел скрипт в гугле который проверяет текущий сервер, на предмет Primary, или Secondary. Если Secondary то делает lock, и бекап, а потом unlock. Я его (скрипт) попробую под себя подогнать, надеюсь получиться :-)
 inqfen
inqfen
Какой ужас
 Sergey
Sergey
Всем привет.
Создаю индекс в коллекции через db.collection_name.createIndex().
Внутри индекса перечислен десяток полей.
Такой индекс нужен для определния уникальности добавляемого документа (так повелось).
Сейчас столкнулся с неизвестной для себя ошибкой.
При попытке добавить очередной документ MongoDB выдаёт ошибку:
Mongo::Error::OperationFailure: WiredTigerIndex::insert: key too large to index, failing
Да, при попытке добавить документ, одно из его полей довольно большое (текст в пару килобайт).
Я правильно понимаю, что при таком подходе, весь документ (все его поля, перечисленные в индексе),
не должен превышать 1024 байт?
 yopp
yopp
Всем привет.
Создаю индекс в коллекции через db.collection_name.createIndex().
Внутри индекса перечислен десяток полей.
Такой индекс нужен для определния уникальности добавляемого документа (так повелось).
Сейчас столкнулся с неизвестной для себя ошибкой.
При попытке добавить очередной документ MongoDB выдаёт ошибку:
Mongo::Error::OperationFailure: WiredTigerIndex::insert: key too large to index, failing
Да, при попытке добавить документ, одно из его полей довольно большое (текст в пару килобайт).
Я правильно понимаю, что при таком подходе, весь документ (все его поля, перечисленные в индексе),
не должен превышать 1024 байт?
Да. Но в 4.2 это ограничение убрали, см. врезку
https://docs.mongodb.com/manual/reference/limits/#Index-Key-Limit
Sergey
Да. Но в 4.2 это ограничение убрали, см. врезку
https://docs.mongodb.com/manual/reference/limits/#Index-Key-Limit
Спасибо!
У меня стоит MongoDB server version: 4.0.9.
Буду курить, как обновить версию сервера, чтобы ничего не упало.
yopp
А почему именно такой набор полей?
 Dmitriy
Dmitriy
Всем привет.
Создаю индекс в коллекции через db.collection_name.createIndex().
Внутри индекса перечислен десяток полей.
Такой индекс нужен для определния уникальности добавляемого документа (так повелось).
Сейчас столкнулся с неизвестной для себя ошибкой.
При попытке добавить очередной документ MongoDB выдаёт ошибку:
Mongo::Error::OperationFailure: WiredTigerIndex::insert: key too large to index, failing
Да, при попытке добавить документ, одно из его полей довольно большое (текст в пару килобайт).
Я правильно понимаю, что при таком подходе, весь документ (все его поля, перечисленные в индексе),
не должен превышать 1024 байт?
сделайте новое поле, конкатенируйте поля в одну строку и преобразуйте в md5 и кладите в новое поле, которое создали. на него вешайте индекс и вы получите все тоже самое, но с полем фиксированной длинны
Sergey
сделайте новое поле, конкатенируйте поля в одну строку и преобразуйте в md5 и кладите в новое поле, которое создали. на него вешайте индекс и вы получите все тоже самое, но с полем фиксированной длинны
Это была первая мысль, когда начал изучать MongoDB. Почему-то тогда это показалось каким-то костылём. Потом дочитал до уникальных индексов, показалось, что это то, что мне нужно.
Sergey
А почему именно такой набор полей?
Проект каждые 10 минут опрашивает данные «за сегодня» с источника.
Начинает в 00:00, заканчивает в 23:50.
Иного фильтра, кроме «за сегодня» у источника нет.
Данные полученные и записанные в БД, например, в 08:00 не должны снова туда попасть в 08:10...23:50.
Кроме хранения данных в БД, используется возможность самой БД, как «не записывать дубликаты».
Увы, в данных нет уникальных полей (id, uuid и т. д.).
yopp
В бд хранятся данные только из этого источника?
Sergey
В бд хранятся данные только из этого источника?
Коллекций и источников много.
Но в одной коллекции — данные строго из одного источника.
В целом — да, в БД хранятся данные только из источника.
yopp
Источник всегда отдаёт все данные за этот день?
Sergey
Источник всегда отдаёт все данные за этот день?
Да. Некоторые источники могут отдавать данные за произвольное время (за последний час, минуту).
Но для унификации считаем, что все источники отдают данные за текущий день всегда.
documents = api.get_data(from_time, to_time)
Условно так.
Конечному пользователю нужна относительная оперативность получения новых данных из БД (каждые 10 минут устраивает).
Потому, каждые 10 минут опрашивается источник, забираются данные (за весь день, как мы помним) и новые кладутся в БД.
Новые ли данные или нет — определяю индексом.
Сейчас ещё раз посмотрел код. На самом деле индекс — это последний эшелон контроля уникальности данных в БД.
До него ещё стоит поиск в коллекции.
next unless collection.find(document).count.zero?
collection.insert_one document
Возможно, придётся отказаться от индексов вовсе и полагаться только на поиск документа в коллекции (не найден — добавить).
yopp
Да. Некоторые источники могут отдавать данные за произвольное время (за последний час, минуту).
Но для унификации считаем, что все источники отдают данные за текущий день всегда.
documents = api.get_data(from_time, to_time)
Условно так.
Конечному пользователю нужна относительная оперативность получения новых данных из БД (каждые 10 минут устраивает).
Потому, каждые 10 минут опрашивается источник, забираются данные (за весь день, как мы помним) и новые кладутся в БД.
Новые ли данные или нет — определяю индексом.
Сейчас ещё раз посмотрел код. На самом деле индекс — это последний эшелон контроля уникальности данных в БД.
До него ещё стоит поиск в коллекции.
next unless collection.find(document).count.zero?
collection.insert_one document
Возможно, придётся отказаться от индексов вовсе и полагаться только на поиск документа в коллекции (не найден — добавить).
Если источники возвращают все документы за текущие сутки при каждом опросе, то дешевле всего к каждому документу добавить общую временную отметку с датой и временем выгрузки и по успешному завершению выгрузки в какой-то коллекции обновлять эту отметку. Дальше при поиске использовать её в качестве фильтра
yopp
По завершению суток удалять промежуточные выгрузки и оставлять только последнюю
yopp
Можете ещё hashed index попробовать
yopp
Но там относительно небольшая энтропия хеша, по-моему всего 64 бита
yopp
Не знаю насколько на ваших данных реальны коллизии
Sergey
> hashed index
На StackOverflow тоже писали про hashed index.
Не уверен, что правильно пока понимаю, что это. Но читаю, спасибо!
> Не знаю насколько на ваших данных реальны коллизии
Данные о пользователях. Имя, Фамилия, Телефон, Эл. почта, Некое сообщение.
Не более того. Если среди тысяч документов случайно проскочит дубль, или наоборот, из двух разных документов в БД попадёт только один — не так смертельно.
yopp
> hashed index
На StackOverflow тоже писали про hashed index.
Не уверен, что правильно пока понимаю, что это. Но читаю, спасибо!
> Не знаю насколько на ваших данных реальны коллизии
Данные о пользователях. Имя, Фамилия, Телефон, Эл. почта, Некое сообщение.
Не более того. Если среди тысяч документов случайно проскочит дубль, или наоборот, из двух разных документов в БД попадёт только один — не так смертельно.
Это тоже самое, что предлагал @sidmal несколькими сообщениям выше, только встроенное в монгу и не с md5
yopp
Индекс который не хранит значения, а хранит только хеш-сумму от значения
yopp
А, нет, именно с md5))))
https://github.com/mongodb/mongo/blob/master/src/mongo/db/hasher.cpp#L38
Araik
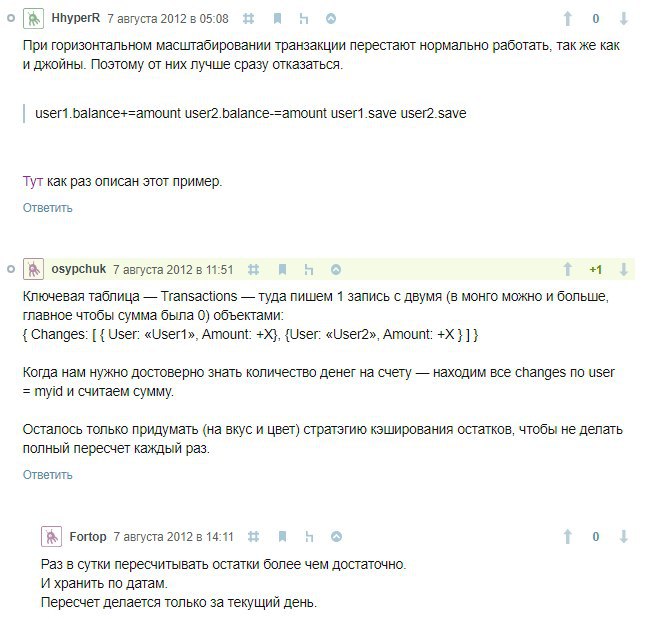
А подскажите пжл, как сохранить консистентность данных при шардировании? Возможно ли это вообще или все таки, если речь о балансе клиента и транзакциях, следует использвать реляционные бд ?
Araik
 Araik
Araik
У меня сейчас база с билингом на отдельном сервере, где хранятся данные о клиентах, балансе, подключенных сайтах; И отдельный кластер, где под каждый сайт клиента отдельная база данных; Жизнеспособная схема?))
Nick
У меня сейчас база с билингом на отдельном сервере, где хранятся данные о клиентах, балансе, подключенных сайтах; И отдельный кластер, где под каждый сайт клиента отдельная база данных; Жизнеспособная схема?))
В 4.+ есть транзакции, так что если не видите вариантов то можете их использлвать. Но будет медленно, особенно на кластере. Лучше по аналогии с вашей картинкой проиаботать схему где у вас не нужно будет использовать явные транзакции
Araik
Да, хотелось бы избежать транзакций, спасибо!
Assylbek
всем привет! вопрос: есть документ с таким полем "someField" : { "$numberInt" : "17"} и запрос db.getCollection('someCollection').find({'someField':17}) не работает(результат выборки не выводит запись с таким полем). подскажите правильно написать запрос для полей с таким типом? версия монгодб 4.2. спасибо
Dmitriy
всем привет! вопрос: есть документ с таким полем "someField" : { "$numberInt" : "17"} и запрос db.getCollection('someCollection').find({'someField':17}) не работает(результат выборки не выводит запись с таким полем). подскажите правильно написать запрос для полей с таким типом? версия монгодб 4.2. спасибо
...find({"someField.$numberInt": 17}) попробуйте так
yopp
Araik
Не все так однозначно
Я с монго работаю не так давно и никогда не использовал транзакции, а все что слышал об этом, что это медленно и есть сложности при горизонтальном масштабировании, в общем, был бы рад узнать о плюсах и минусах от более компетентных коллег
yopp
Потому что в большинстве хранилищ нет поддержки транзакций при шардировании
Araik
не уверен, что правильно понял, что значит "в большинстве хранилищ"
Araik
речь о готовых хранилищах, типа www.mongodb.com ?
Dmitriy
я бы сказал так, в большинстве субд нет шардирования из коробки)))
yopp
Это значит что те базы данных, которы вероятнее всего используют те ваши коллеги, не имеют механизмов контроля целостности шаржированных топологиях
yopp
Из коробки по крайней мере
Araik
а монго при этом имеет?
yopp
С 4.2 — да
Araik
Интересно, спасибо, буду изучать
Александр
 Александр
Александр
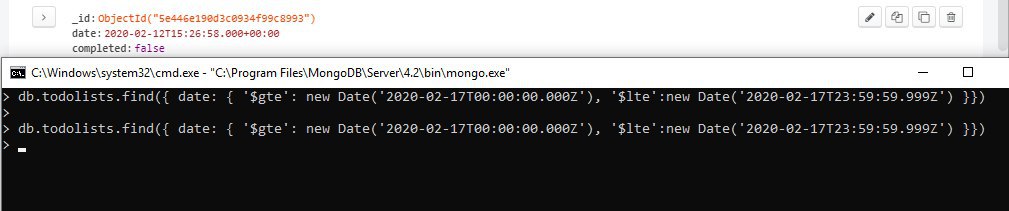
В базе нет 17.02
Александр
Но когда выгружаю весь список через find{}
Александр
17е откуда-то появляется на странице
Александр
Понятно что нихрена не понятно
Александр
Но если вручную исправить в базе через компас день то запрос работает и в вебе выводится
 🦁👉🤛
🦁👉🤛
@dd_bb @yatoba
Anonymous
hello!!! 1384
Евгений
Привет! можно ли средствами монги многомерный массив сделать плоским?
`
server_1 | !!-!!-!! res {200219114112}
server_1 | [
server_1 | {
server_1 | _id: null,
server_1 | protocols: [
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ], [ 'UDP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP', 'UDP' ], [ 'TCP' ], [ 'TCP' ], [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP', 'UDP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'UDP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ],
server_1 | [ [ 'TCP' ] ]
server_1 | ]
server_1 | }
server_1 | ]
`
Евгений
имею в виду по простому чтобы
Nick
имею в виду по простому чтобы
Только если знаете сколько у него измерений https://docs.mongodb.com/manual/reference/operator/aggregation/concatArrays/ и там по идее с фмлттрами и условиями по граться, чтоьы каскад получить, может даже через о дельные стейджи. Но если это не принципиалтно, то лучше на стороне клиента уже сделатт
Евгений
Только если знаете сколько у него измерений https://docs.mongodb.com/manual/reference/operator/aggregation/concatArrays/ и там по идее с фмлттрами и условиями по граться, чтоьы каскад получить, может даже через о дельные стейджи. Но если это не принципиалтно, то лучше на стороне клиента уже сделатт
сделал вот так https://mongoplayground.net/p/WF7f9-1kvcy , не сказать чтобы просто получилось. Теперь ещё задача, в итоговом массиве подсчитать сколько каких элементов, типа [{name: 'TCP', count: 2}, {name: 'UDP', count: 3}] - если кто знает, подскажите решение (недавно решал такую задачу но там чуть по другому было, а тут по другому малость)
hostmit
Подскажите webUI (докер) для монгоБД? mongo-express не хватает возможности квери полноценной и статистики
hostmit
Пока посмотрел mongo-express + mrvautin/adminmongo
yopp
https://www.nosqlclient.com
Ivan
Подскажите можно ли менять местами обьекты внутри коллекции, перемещать как нибудь, либо создавать новые обьекты не в конец или начало коллекции, а в указанный индекс
Nick
Подскажите можно ли менять местами обьекты внутри коллекции, перемещать как нибудь, либо создавать новые обьекты не в конец или начало коллекции, а в указанный индекс
Нельзя, понятие позиции в коллекции не постоянно. Если вам нужен порядок, то выберите поле в документе и делайте сортировку по нему. И вот через него можете играться с позицией
 Ярослав
Ярослав
root@vh3757:~# mongod
2020-02-20T00:48:40.570+0300 I CONTROL [initandlisten] MongoDB starting : pid=664 port=27017 dbpath=/data/db 64-bit host=vh3757
2020-02-20T00:48:40.571+0300 I CONTROL [initandlisten] db version v3.6.3
2020-02-20T00:48:40.571+0300 I CONTROL [initandlisten] git version: 9586e557d54ef70f9ca4b43c26892cd55257e1a5
2020-02-20T00:48:40.571+0300 I CONTROL [initandlisten] OpenSSL version: OpenSSL 1.1.1 11 Sep 2018
2020-02-20T00:48:40.571+0300 I CONTROL [initandlisten] allocator: tcmalloc
2020-02-20T00:48:40.572+0300 I CONTROL [initandlisten] modules: none
2020-02-20T00:48:40.572+0300 I CONTROL [initandlisten] build environment:
2020-02-20T00:48:40.572+0300 I CONTROL [initandlisten] distarch: x86_64
2020-02-20T00:48:40.572+0300 I CONTROL [initandlisten] target_arch: x86_64
2020-02-20T00:48:40.572+0300 I CONTROL [initandlisten] options: {}
2020-02-20T00:48:40.573+0300 I STORAGE [initandlisten] exception in initAndListen: NonExistentPath: Data directory /data/db not found., terminating
2020-02-20T00:48:40.573+0300 I CONTROL [initandlisten] now exiting
2020-02-20T00:48:40.573+0300 I CONTROL [initandlisten] shutting down with code:100
Ярослав
Что делать?
Ярослав
Не знаю как это понимать.. Я взял свою старую бд, решил перенести на сервер с Ubuntu 18.04 встала, импортировал. Перезагрузил машину и все упало.
yopp
По какой-то причине монга не может найти директорию с данными. Проверьте что ининт/systems скрипты используют тот-же конфиг что вы использовали для переноса
Ярослав
При переносе с windows я только json файл выкачал, не более.
 Alexander
Alexander
Привет!
Делаю бэкенд для сервиса типа "гугл-форм".
Нужно хранить описание формы и заполнения формы.
У заполнений разных форм разный набор полей
Нормально ли создавать для каждой формы отдельную коллекцию в монгодб?
Alex
Привет!
Делаю бэкенд для сервиса типа "гугл-форм".
Нужно хранить описание формы и заполнения формы.
У заполнений разных форм разный набор полей
Нормально ли создавать для каждой формы отдельную коллекцию в монгодб?
Можно все в одной хранить, просто на бекеенде описать интерфейсы для работы с разными входными данными и написать соответствующие стратегии, это все)