а если в бд несколько коллекций. Не легче считать размер всей бд?
Вы же знаете к какой коллекции вы запрос делаете
 Nick
Nick


 Гена
Гена
Задача в следующем - создать алёрт, который будет предупреждать если бд разрослась почти до лимита.
Nick
Получается это задача для администрирования места в папке а не в базы, т.е просто берете df -h парсите скока мкста занято и скока всего, там вроде и процентаж был гдето
Nick
Если у вас какаято облачная монга, то берите просто стату бд, там есть скока места она занимает и мониторьте это значение
Гена
Nick
монга не в облаке
Тогда я не понимаю почему надо мониторить через запрос к морге, а не мониторинг самого сервера
Гена
Тогда я не понимаю почему надо мониторить через запрос к морге, а не мониторинг самого сервера
не думаю что сработает. Бд находится не в отдельной директории а в общем дататопе, и запарсить не получится
Nick
У монги есть вполне фиксииованный путь где лежат данные, там тот же 'du -sh .' покажет сколько места занимает папка
Гена
я к тому, что в реплика сете находится несколько БД, и так как в дататопе они находят в виде collection-4-4137684697285707732.wt и тд то думаю невожножно вычесть где там что
Nick
Тоода через стату бд
Гена
ну вот) получается надо запарсить стату, чтоб оно показывало размер в ГБ и потом дальше думать
Nick
Просто в чем сама бизнес задача? Что случится после 10гб, почему только 10гб?
Nick
Просто нужно не забывать, что монга жмпт данные по дефолту и размер бд и размер занимаемых файлов это немного разные вещи, плюс не забываем про индексы
Гена
Просто в чем сама бизнес задача? Что случится после 10гб, почему только 10гб?
так попросил клиент
смысл в том, что когда она разрастётся до определённого размера, базу вынесут в отдельный репликасет
Гена
Nick
Max
Вам или через системные утилиты взвешивать директорию с монгой (du), либо берите db.stats() с включенным indexDetails, и смотрите на размер данных.
там будет и размер файлов на диске, и размер непосредственно данных, которые там лежат для понимания фрагментации.
Max
плюс вы сможете разделить размер самих данных и индексов.
там, по сути, содержится _вся_ необходимая вам информация.
ну а как ее обрабатывать - то уже решать согласно вашей бизнес-задачи
Nick
только думаю вот какое значение брать. сжатое чи нет
Любое, под вашу задачу как я понял юзеру важно примерно понять что база разрослась
Kenan
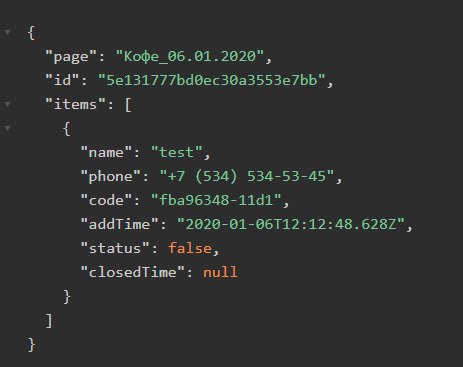 Kenan
Kenan
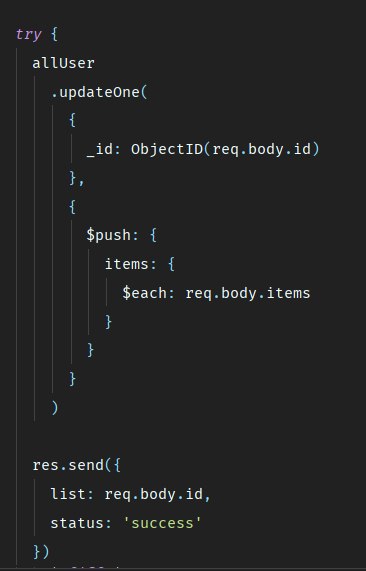 Kenan
Kenan
( мб и по скрину второму скажет кто-то что-то ( мб есть лучше решения ) )
Dima
нашествие ботов
Artemy
Вот зашли они в чат, а дальше что?
Dima
Твой вопрос похож на утверждение что за этим стою я, но это не так
Artemy
Нет, никаких подозрений там между строчек не было)
Artemy
Действительно интересно, зачем это делается
madspectator
Посидят день, неделю, месяц в чате молча. Потом запостят спам.
madspectator
Если на сервере три одинаковых SSD диска, что будет быстрее работать:
1) журнал на одном диске, данные на втором, индексы на третьем
2) raid5 на трёх дисках, ну и журнал + данные + индексы на одном логическом разделе в raid5
?
 Aleksandr
Aleksandr
 Alexander
Alexander
Если на сервере три одинаковых SSD диска, что будет быстрее работать:
1) журнал на одном диске, данные на втором, индексы на третьем
2) raid5 на трёх дисках, ну и журнал + данные + индексы на одном логическом разделе в raid5
?
Не надо raid5. Он хорош для чтений, но плох для записей и очень плох при отказах одного из дисков. Традиционно в базах данных используется raid10.
madspectator
У меня там нет такого варианта, есть noraid, raid0, raid1, raid5.
Alexander
У меня там нет такого варианта, есть noraid, raid0, raid1, raid5.
Если Вам хоть сколь-нибудь дороги данные, то используйте зеркало.
madspectator
Зеркало это raid1 и raid5 из вышеперечисленных? Так то у меня репликация ещё будет.
Alexander
Зеркало это raid1 и raid5 из вышеперечисленных? Так то у меня репликация ещё будет.
Википедию, что ли, откройте..
В целом, у каждого вида raid есть свои собственные, особые свойства при операциях чтения, записи и при отказах дисков, участвующих в raid. И Вы должны выбирать тот из них, что в большей степени подходит в Вашей ситуации.
madspectator
Открывал. Разве я неправильно выше написал?
madspectator
Т.к. я ничего не понимаю в рейдах, я выбрал тот, который максимально мне подходит: noraid :)
madspectator
Просто вынесу collection директорию на второй диск, а index директорию на третий.
Alexander
Просто вынесу collection директорию на второй диск, а index директорию на третий.
Это будет хорошо работать. До тех пор, пока данные помещаются на диске. И пока диск не откажет. Что Вы будете делать тогда?
madspectator
Если диск крякнется, то данные останутся на secondary сервере реплики.
Alexander
Если диск крякнется, то данные останутся на secondary сервере реплики.
Ок, это Ваш план восстановления после сбоя (полагаю, Вы слышали о протоколе выборов и его деталях в части честного числа участников).
Как на счёт расширения дисковой ёмкости?
madspectator
Например, вводим дополнительные secondary, синхронизируем. Стопаем "мелкие" сервера. А при чём тут RAID? :)
Alexander
Например, вводим дополнительные secondary, синхронизируем. Стопаем "мелкие" сервера. А при чём тут RAID? :)
Дополнительные "секондари" не помогут, потому что они держат те же самые данные, и они ровно также не поместятся.
Дело в том, что это одна из трудностей, которые возникают регулярно, и которую нужно уметь преодолевать. А raid здесь при том, что позволяет это эффективно сделать.
madspectator
Почему, не понимаю. Вот запускаю я новый secondary, у него диск не 100 гигабайт, а один терабайт, синхронизирую туда primary, потом отключаю primary.
madspectator
Если вы имеете в виду, что в raid каких-то уровней можно на лету подмешивать новые диски, то это не мой случай, те серверы, что я использую не подразумевают добавление дисков. Так что это возможно лишь в некотором будущем, если я захочу сделать всё супер-мега-надёжно.
Alexander
Почему, не понимаю. Вот запускаю я новый secondary, у него диск не 100 гигабайт, а один терабайт, синхронизирую туда primary, потом отключаю primary.
Поясню: то, что Вы написали, будет работать до тех пор, пока есть промышленные диски размера большего, чем Ваши данные. Что, если в один прекрасный день таких дисков на найдётся? Если сейчас, положим для примера, максимальный размер ssd-диска 4Тб, и данные перестали в него "вписываться" - что тогда?
Alexander
Если вы имеете в виду, что в raid каких-то уровней можно на лету подмешивать новые диски, то это не мой случай, те серверы, что я использую не подразумевают добавление дисков. Так что это возможно лишь в некотором будущем, если я захочу сделать всё супер-мега-надёжно.
Дело в том, что Вы не объяснили, что у Вас за система, но спрашиваете, как лучше поступить. По этой причине Вы не получите конкретного ответа (никто не знает, как будет лучше в данной ситуации с непонятными критериями лучшести). Я задаю важные для принятия решения вопросы, не более того.
madspectator
Это, конечно, интересная теоритическая проблема, но у меня есть много практических проблем. Так что мой ответ: я без понятия и меня это пока мало волнует.
madspectator
Я не спорю, вопрос так себе у меня.
Alexander
 Alex
Alex
Может быть кто-то подскажет... Мне нужно организовать поиск только по 2м полям. Первое на русском, второе на английском.
Пытался так:
db.roots.createIndex(
{ "translations.translateRu": "text" },
{ name : "RuIndex"},
{ collation: { locale: "ru" } },
{default_language: "russian"} )
db.roots.createIndex(
{ "translations.translateEN": "text" },
{ name : "EnIndex"},
{ collation: { locale: "en" } },
{default_language: "english"} )
Alex
запрос на поиск:
dbo.collection("roots").find({
$text:
{
$search: searchtext,
$caseSensitive: false,
$diacriticSensitive: true
}
})
.project({ score: { $meta: "textScore" } })
.sort({score:{$meta:"textScore"}})
Kenan
Kenan
мне до этого советовали искать с помощью регулярки
Kenan
 Alex
Alex
одновременно индексацию на русском и английском мне добавить не даёт и если добавил индекс на русском - то поиск на английским выдаёт пустую строку, что ожидаемо...
Alex
Для меня сработал вариант регулярного выражения вида:
{"translations.translateRu":{$regex:new RegExp('(^|\\s)' + search + '(?=\\s|$)', 'i') }},
{ "translations.translateEn": { $regex:new RegExp('(^|\\s)' + search + '(?=\\s|$)', 'i') } }
Совместно с добавлением индекса:
db.roots.createIndex(
{ "translations.translateRu": "text" },
{ collation: { locale: "ru" },
{default_language: "english"},
{ name : "RuIndex"} )
поиском по тексту...
Евгений
Народ, есть проблема в запросе, если у меня есть входящий набор идшников допустим 1,2,3 и есть хранилище документов, где хранятся документы в которых есть массив из этих ид, так вот, мне надо выбрать все документы в которых все элементы массива входят в этот набор идшников, то есть беру я допустим набор 1,2,3 а у меня есть документы в которых есть 1,2 1,3 и 1,4 так вот, должны выбраться только 1,3 и 1,2 т.к. все элементы массива этих документов входят в мой предоставленный набор 1,2,3 при этом 1,4 должен исключиться, всю бошку сломал, плиз хелп
Евгений
Есть кто шарящий?
Евгений
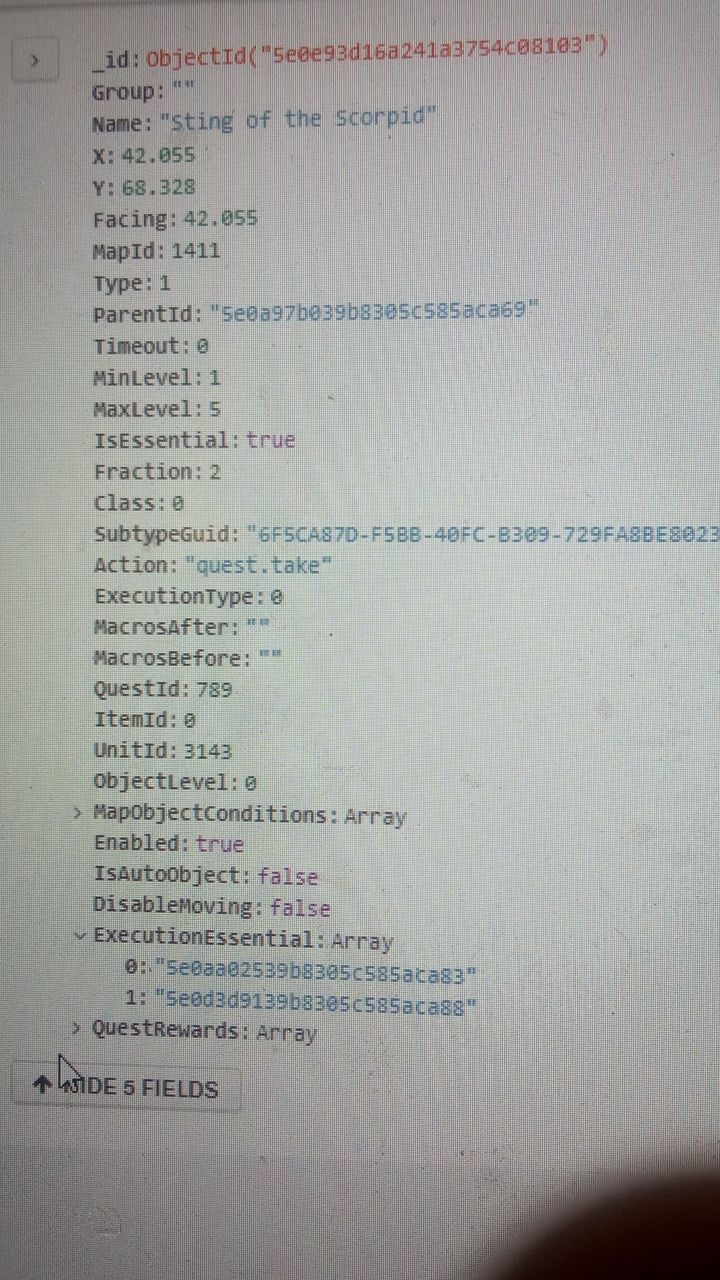 Евгений
Евгений
Есть типа вот такой документ с полем ExecutionEssential, там хранятся ID требующиеся для выбора этого документа
Евгений
Так вот мой набор может состоять из этих ИД плюс ещё несколько типа вот так
Евгений
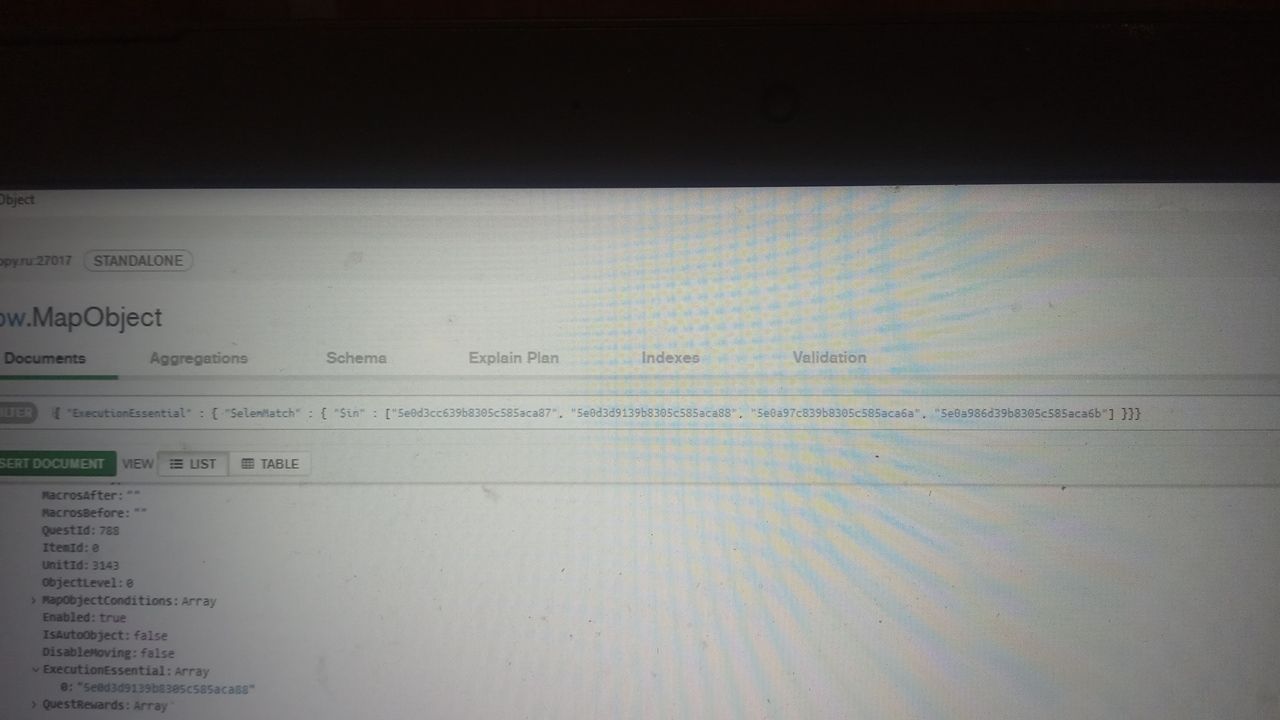 Евгений
Евгений
Но через elemMatch он выбирает даже если один ИД входит в этот массив
Евгений
А мне надо чтобы если все ИД входят в этот массив выбирались
Евгений
Проще, у меня есть ключи 1,2,3 и мне надо выбрать двери так вот есть дверь для которой подходят ключи 1,2 и мы ее выбираем, т.к. эти ключи у меня есть а если дверь для которой надо 1,4 мы не выбираем т.к. нет ключа 4
 Avtandil
Avtandil
Привет все. Я недавно начал использовать монго, как понимаете не особо подкован. Не могу понять как построить конструкцию запроса чтобы найти совпадения в коллекции из ключей массива. Это нужно делать запросы в цыкле или есть конструкция где можно получить документы сделав один запрос с массивом ключей?
Подскажите пожалуйста. Спасибо заранее
Евгений
Привет все. Я недавно начал использовать монго, как понимаете не особо подкован. Не могу понять как построить конструкцию запроса чтобы найти совпадения в коллекции из ключей массива. Это нужно делать запросы в цыкле или есть конструкция где можно получить документы сделав один запрос с массивом ключей?
Подскажите пожалуйста. Спасибо заранее
Это вы перевели на русский язык мой вопрос?))
Avtandil
Это вы перевели на русский язык мой вопрос?))
К сожелению я ваш вопрос не читал, но возможно вы получили ответ и знаете как решить
Евгений
Ну я как раз уже часа 2 бьюсь, вам надо чтобы хотя бы один элемент совпадал
Евгений
Или все совпадали?
Avtandil
У меня только такое решение. ["Tokyo","Pekin","Stambul"].forEach( city => { Cities.find({city}) }