 Nick
Nick


Тогда два решения, попроще -док содержит в себе поле с ид листа и массив объектов, каждый из которых это ваши даные в одной строке, поля у объекта должны будут иметь нормальные имена, чтобы по ним искать. Второй вариант - каждая строка отдельный док в коллекции, с уеазанием листа и позиции в листе
Nick
т.к формат строки фиксирован, то надо этим пользоваться, отсюда и вылезают объекты. Так же можно сделать нормальный импортер данных с валидацией на стадии загрузки
 Kenan
Kenan
@yatoba спасибо за хелпу и уделённое время :)
Nick
Незачто, пишите еще если вопросы будут
 madspectator
madspectator
Подскажите, у меня руки кривые или это нормально? Есть коллекция на 500млн записей. Просто тупо {_id: "<[string{5-30}>"}. Если начинаю делать bulk write из множества потоков (ну, например, суммарно, 20млн upsert в час т.е. 5000 в секунду, большинство upsert уже есть в базе), то всё начинает дико тупить, в db.currentOp() видно множество висящих операций. Индексы в память помещаются. Диск (один) SSD.
Nick
Подскажите, у меня руки кривые или это нормально? Есть коллекция на 500млн записей. Просто тупо {_id: "<[string{5-30}>"}. Если начинаю делать bulk write из множества потоков (ну, например, суммарно, 20млн upsert в час т.е. 5000 в секунду, большинство upsert уже есть в базе), то всё начинает дико тупить, в db.currentOp() видно множество висящих операций. Индексы в память помещаются. Диск (один) SSD.
Зачем апсерт? Вы обновляете значение других полей?
madspectator
Зачем апсерт? Вы обновляете значение других полей?
Мой веб-краулер скачивает множество объектов из сети. Среди них только малое количество объектов, которых ещё нет в базе. Вот для этого и использую upsert + $setOnInsert, чтобы вставлять новые ID в коллекцию.
Nick
Мой веб-краулер скачивает множество объектов из сети. Среди них только малое количество объектов, которых ещё нет в базе. Вот для этого и использую upsert + $setOnInsert, чтобы вставлять новые ID в коллекцию.
В таком случае лучше делать просто инсерты и игнорировать ошибку дубликации записи, оно будет лишь дергать индекс, вместо переписывания всего дока
madspectator
Так у меня вся дока это и есть {_id: 'что-нибудь'}.
Nick
Стата по дискам есть? Скока там операций записи?
madspectator
Изначально я писал в главную коллекцию, там много разных индексов и оно стало дико тормозить при достижении размера коллекции 500млн записей. Тогда я продублировал _id в отдельную коллекцию и решил писать основной поток в эту коллекцию, а уже действительно новые _id писать в главную коллекцию. Но вот пока не могу даже эту промежуточную коллекцию настроить.
madspectator
Стата по дискам есть? Скока там операций записи?
Попозже скину, сегодня-завтра. Надо заново запустить это всё, я там эксперементировал и сейчас нету потока данных.
madspectator
А, ну вообще, всё в диск упиралось по какой-то причине. В top все ядра в %wait висели.
Nick
А что мешает сначала сделать поиск по ид а потом уже решать вставлять или нет, вместо постоянного обновления данных?
madspectator
Так я монгу, по сути, использую для поиска дубликатов. А как я поиск сделаю? Не буду же я в монге искать. Вы имеет в виду кэшировать ID в памяти, в веб-краулере или в redis?
Nick
Именно что искать в монге и избавиться от балков
Nick
На то она и бд))
madspectator
Не очень понимаю, у меня 5000 операций в секунду. Запускать 5000 операций find в секунду?
madspectator
Это дико затормозит краулер за счёт времени выполнения операции, передачи данных по сети и т.д.
Nick
5000 поисков по индексу намного дешевле чем 5000 чтений и записей доков на диск
madspectator
В том то и дело, что нету 5000 записей на диск. И чтения не дожно быть. Ну как я это представлял себе, индексы висят в памяти, я делаю upsert, те немногие upsert, что содержат новые данные пишутся на диск.
madspectator
Но на практике почему-то тормозит.
Nick
Апсерт делает полное чтение дока с диска и потом запись новой версии в случает апдейта, и просто запись нового дока в случае инсерта. Отсюда и нагрузка нв диск
madspectator
Так не дожно быть update! Я же использую $setOnInsert, там нет $set.
Nick
Вот поэтому я и просил стату по дисковым операциям, могу ошибаться
madspectator
Ну да, сейчас нет смысла это обсуждать. Скину попоже статистику.
Nick
В доке ничего не говорится про отдельный случай когда $setOnInsert единственное действие, эт в кишки надо лезть разбираться, но думвю там именно как я выше описал
Кылыч
всем привет ребята. при апдейте документа выкидывается E11000 duplicate key error collection. поле вот такое {field_1: [ { field_2: Date, unique } ] }. прикол в том что я не пытаюсь сохранять дупликаты. на локалке вроде все норм, на серваке ругается.
Nick
всем привет ребята. при апдейте документа выкидывается E11000 duplicate key error collection. поле вот такое {field_1: [ { field_2: Date, unique } ] }. прикол в том что я не пытаюсь сохранять дупликаты. на локалке вроде все норм, на серваке ругается.
в базе уже есть дубликаты, проверяйте что там лежит сейчас, если надо чистите
Кылыч
в базе уже есть дубликаты, проверяйте что там лежит сейчас, если надо чистите
Я полностью перезаписываю массив
Nick
а не по массиву внутри одного документа
Кылыч
То есть смысла делать поле объекта в массиве не варик?
madspectator
Так, ну что же, запустил 10 процессов краулера. Если глянуть top, то куча ядер висит в iowait. Мониториг показывает, что диск работает на чтение.
madspectator
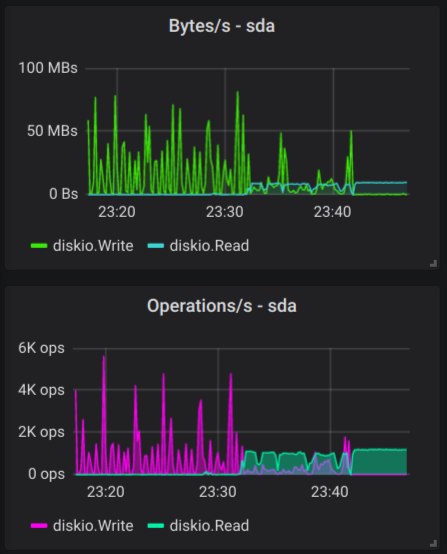 madspectator
madspectator
Вот минут 20 назад я остановил все процессы, использующие монгу, и запустил этот самый краулер, который пишет bulk-upsert-setOnInsert в коллекцию монги
Kenan
Тогда два решения, попроще -док содержит в себе поле с ид листа и массив объектов, каждый из которых это ваши даные в одной строке, поля у объекта должны будут иметь нормальные имена, чтобы по ним искать. Второй вариант - каждая строка отдельный док в коллекции, с уеазанием листа и позиции в листе
Правильно ли я понял, что в коллекции объект страницы должен выглядеть примерно так:
{
list: 'listName',
items: [...]
}
?
madspectator
Все монго треды в основном читают
madspectator
madspectator
Мongotop:
ns total read write
twitter.user_new 31095ms 0ms 31095ms
...
Nick
Все монго треды в основном читают
О спасибо, получается запись не происходит, видать док не изменился, а вот чтение остается
madspectator
> db.stats(1024*1024*1024)
{
"db" : "twitter",
"collections" : 18,
"views" : 0,
"objects" : 1188317420,
"avgObjSize" : 326.60623454463877,
"dataSize" : 361.45735344849527,
"storageSize" : 175.80627059936523,
"numExtents" : 0,
"indexes" : 23,
"indexSize" : 49.5521240234375,
"scaleFactor" : 1073741824,
"fsUsedSize" : 329.46751403808594,
"fsTotalSize" : 935.848072052002,
"ok" : 1
}
Вообще, конечно, индексов многовато что-то, 50гб
madspectator
На сервера 94гб памяти, монге половина отведена.
Nick
> db.stats(1024*1024*1024)
{
"db" : "twitter",
"collections" : 18,
"views" : 0,
"objects" : 1188317420,
"avgObjSize" : 326.60623454463877,
"dataSize" : 361.45735344849527,
"storageSize" : 175.80627059936523,
"numExtents" : 0,
"indexes" : 23,
"indexSize" : 49.5521240234375,
"scaleFactor" : 1073741824,
"fsUsedSize" : 329.46751403808594,
"fsTotalSize" : 935.848072052002,
"ok" : 1
}
Вообще, конечно, индексов многовато что-то, 50гб
Не много, на каждую коллекцию по одному индексу на поле _id всегда.
madspectator
Конкретно в user_new только один индекс сейчас, этот самый _id
madspectator
Никто, под монгу взял сервер.
Nick
madspectator
Т.е. монга читает индекс с диска? Других вариантов я чё-то даже не могу представить.
Kenan
По первому варианту да
Тогда вопрос хороший возникает: как пушить в массив в при таком раскладе? Делать find, toArray и оттуда push?
Nick
Т.е. монга читает индекс с диска? Других вариантов я чё-то даже не могу представить.
Да она выгружает неиспользуемое, включая ненужные части индексов
Kenan
Ибо insert в коллекцию делает
Nick
Тогда вопрос хороший возникает: как пушить в массив в при таком раскладе? Делать find, toArray и оттуда push?
В вашем случае советую вытаскивать полностью док, его редактировать, потом сохранять. С пушами запутаетесь и слтжно получится, здесь уже будет иметь смысл использовать второй вариант
Kenan
В вашем случае советую вытаскивать полностью док, его редактировать, потом сохранять. С пушами запутаетесь и слтжно получится, здесь уже будет иметь смысл использовать второй вариант
При втором варианте при гете данных мне нужно будет собирать все данные с коллекций, собирать их в json и отдавать?
Kenan
Nick
При втором варианте при гете данных мне нужно будет собирать все данные с коллекций, собирать их в json и отдавать?
Да просто все собирать и отсылать на клиент, вплоть до возможно не все сразу если будут проблемы с отрисовеой, то сразу и эту проблему решите
madspectator
Сейчас попробую так сделать: db.user_new.findOne({_id: /жжж/}) - оно должно прогрузить весь _id индекс в память, по идее. И потом ещё раз запущу краулер.
madspectator
Ну, не знаю. Запустил ещё раз краулер. Всё также куча потоков что-то читающих с диска.
madspectator
Хотя я только что индекс прогрузил в память.
Kenan
Обычный find
А findAndModify не подойдёт? Или можно find'ом найти и полученные данные изменить? ( db.collection.find().exec(....))
Nick
А findAndModify не подойдёт? Или можно find'ом найти и полученные данные изменить? ( db.collection.find().exec(....))
Предполагалось, что вы в приложении держите копию дока и его сохраняете, для это нужен первый файнд. А дальше сохранпние да через обычный апдейт
Kenan
Предполагалось, что вы в приложении держите копию дока и его сохраняете, для это нужен первый файнд. А дальше сохранпние да через обычный апдейт
На клиент отдаю только активную страницу
Kenan
Остальные по запросу, само собой
 Alisher
Alisher
А можно восстановить базу имея только образ диска? Есть все файлы из /var/lib/mongodb/ старой машинки, нужно перенести документы оттуда в новую БД.
Sebor▂▅▇█▓▒░
Alisher
А так запустить не пробовал?
И правда, скопировал файлы и указал в конфиге dbPath до них, работает. Спасибо 👍
Гена
Коллеги, подскажите, есть ли способ как-то посчитать размер БД, чтоб вывод был в процентах?
Я как-то запутался в аггригациях
 Alexander
Гена
Alexander
Гена
от определённого размера. Есть условно лимит, 10гб. надо чтоб селект показывал, что по отношению к 10гб столько процентов осталось
Гена
10гб = 100%
Гена
я вижу это так, что мы через переменную задаем лимит, 10гб=100%
после чего гоним селект, который показывает в гигах сколько весит бд
после чего вывод сравнивается с значением переменной и выдает процент
Roman
У монги в один док не больше 16мб данных можно запихнуть. Поэтому это нужно заранее чекнуть
Это не совсем так. Хранение документов(элементов коллекции) размером более 16mb в mongodb обеспечивается посредством GridFS
Nick
я вижу это так, что мы через переменную задаем лимит, 10гб=100%
после чего гоним селект, который показывает в гигах сколько весит бд
после чего вывод сравнивается с значением переменной и выдает процент
Можете для коллекции стату взять и ее размер использовать, тамже есть средний размер одной записи, можно просто количественно считать
Гена
а если в бд несколько коллекций. Не легче считать размер всей бд?
Nick
Это не совсем так. Хранение документов(элементов коллекции) размером более 16mb в mongodb обеспечивается посредством GridFS
Нет, гридфс для бинарных больших файлов, по ним по внутренностям поиск недоступен