 Kirill
Kirill


большое спасибо, видимо пришло время и с докером познакомиться
 Vlad
Vlad
а можно прервать запрос в mongo shell, чтобы при этом она не закрылась? раздражает постоянно логинится потом
Kirill
не совсем понимаю как запустить percona на удаленной от БД машине, ведь она запускается посредством команды service mongod start, а при запуске pmm с —uri требуется запуск конфига, который в свою очередь невозмжен без указания сервера. не пойму где я ошибаюсь
Kirill
@dd_bb не подскажите?
Kirill
со всем что написал выше - успешно справился. сейчас проблема на финальном шаге где нужно добавить --uri. выдает:
Error adding MongoDB metrics: cannot verify MongoDB connection with /usr/local/percona/pmm-client/mongodb_exporter --test: exit status 1:
Пробовал по всякому, с паролем и без. Порт на машине с монгой указан верный
tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN 7887/mongod
на 27017 и пробую. докерЮ как минимумЮ хост видит, но пробится к монге не выходит. может нужны какие то особенные настройки?
Kirill

 yopp
yopp
со всем что написал выше - успешно справился. сейчас проблема на финальном шаге где нужно добавить --uri. выдает:
Error adding MongoDB metrics: cannot verify MongoDB connection with /usr/local/percona/pmm-client/mongodb_exporter --test: exit status 1:
Пробовал по всякому, с паролем и без. Порт на машине с монгой указан верный
tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN 7887/mongod
на 27017 и пробую. докерЮ как минимумЮ хост видит, но пробится к монге не выходит. может нужны какие то особенные настройки?
проверьте что вы с этого хоста можете через mongo-shell подключится
Kirill
с хоста где монго или с которого коннект делаю?
yopp
с которого пытаетесь подключится к кластеру
Kirill
можете дать наводку на то как подключаться через монго шел?
Kirill
а, похоже я понял. через "mongo"
yopp
https://docs.mongodb.com/manual/mongo/#mongodb-instance-on-a-remote-host
yopp
убедитесь что монга слушает на 0.0.0.0 интерфейсе
yopp
и что у хоста есть адрес, по которому он доступен из сети докера
Kirill
и что у хоста есть адрес, по которому он доступен из сети докера
в этом убедился - курл по хосту прошел
Kirill
через шел тоже не вышло
Kirill
 Kirill
Kirill
честно говоря не очень знаю, слушает она или нет - думаю проверять порты
Kirill
да действительно на 22 порт есть телнет на 27017 нет
Kirill
вроде всё получилось - большое спасибо. включил мониторинг, подскажите - где я теперь могу наблюдать результаты
 Даниил (Onix)
Даниил (Onix)
 Даниил (Onix)
Даниил (Onix)
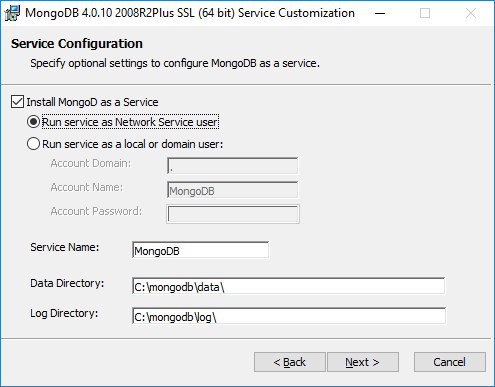
чем локал от нетворка отличаются? Я устаналиваю первый раз для того чтобы попробовать (т.е. сервер на локалке крутится)
Даниил (Onix)
в первом случае (as network) к монге можно будет извне обратиться как к настоящей базе?
Kirill
вроде всё получилось - большое спасибо. включил мониторинг, подскажите - где я теперь могу наблюдать результаты
видимо какие то махинации нужны с докером)
Даниил (Onix)
Товарищи, неужели никто не может ответить на мой вопрос?
Anonymous
в первом случае (as network) к монге можно будет извне обратиться как к настоящей базе?
Нет, это виндовые приколы с правами
Даниил (Onix)
ну я говорю, мне сервис для локальной разработки надо
Anonymous
Ну т.е. будет она наружу торчать или нет зависит не от этого
 Nick
Nick
Nick
Nick
В общем случае по второму пункту указывается юзер заведенный в системе актив директор , где админы могут централизованно назначать ему всякие разрешения и квоты
Vlad
есть такой индекс
db.tenders.createIndex({is_missed:1,"data.contracts.dateSigned":1},{partialFilterExpression:{is_missed:true}})
почему он не используется в таком запросе?
db.coll.find({is_missed:true, 'data.contracts.dateSigned':{$gte:'2019-01-01',$lte:'2019-03-31'}}).sort({'data.contracts.dateSigned':-1})
насколько я понимаю и согласно документации монги, должен использоваться
 Николай
Николай
Всем привет, подскажите, пожалуйста.
Ситуация такая есть монга с 60+ миллионами записей(к-ство растет) и примерно 10 полей по которым идут разные вариации выборок и группировок
Хочу узнать каким образом лучше ускроить скорость отдачи, а то сейчас она совсем не ахти.
yopp
есть такой индекс
db.tenders.createIndex({is_missed:1,"data.contracts.dateSigned":1},{partialFilterExpression:{is_missed:true}})
почему он не используется в таком запросе?
db.coll.find({is_missed:true, 'data.contracts.dateSigned':{$gte:'2019-01-01',$lte:'2019-03-31'}}).sort({'data.contracts.dateSigned':-1})
насколько я понимаю и согласно документации монги, должен использоваться
потому что сортировка по 'data.contracts.dateSigned’:-1, а индекс по "data.contracts.dateSigned":1
yopp
yopp
которая покрывает целевые запросы
Николай
Ну все возможные комбинации я не смогу покрыть
Николай
И количество индексов никак не влияет?
Vlad
И количество индексов никак не влияет?
чем больше индексов, тем медленее вставка и апдейт данных. ну и места на диске больше занимает база в целом
Vlad
потому что сортировка по 'data.contracts.dateSigned’:-1, а индекс по "data.contracts.dateSigned":1
да он и по :1 ищет долго. вообще же направление сортировки не важно для одиночного индекса, тут по первому полю прямое сравнение, значит по второму поиск должен идти, как по одиночному, разве нет?
Vlad
Ну все возможные комбинации я не смогу покрыть
думать надо, explain смотреть, вообще, чем больше вариативносность поля или комбинации полей для индекса, тем быстрее поиск+погуглите mongo tune+возможно разбить базу на разные части есть смысл. да и вообще может вам не монга нужна, а реляционная БД? постгрес хорошо с индексами работает
yopp
yopp
думать надо, explain смотреть, вообще, чем больше вариативносность поля или комбинации полей для индекса, тем быстрее поиск+погуглите mongo tune+возможно разбить базу на разные части есть смысл. да и вообще может вам не монга нужна, а реляционная БД? постгрес хорошо с индексами работает
если вы будете советовать пойти в гугл и рекомендавать другие хранилища без веской аргументации, я вас в read only отправлю
Vlad
если вы будете советовать пойти в гугл и рекомендавать другие хранилища без веской аргументации, я вас в read only отправлю
насколько детально задан вопрос, настолько детальный и ответ и это может и банальные вещи, но я сам это все проходил. а так хозяин барин, пока мне тут ничем тоже не помогли, explain посмотреть я и сам догадался, на прошлые вопросы вообще никто не отреагировал
yopp
насколько детально задан вопрос, настолько детальный и ответ и это может и банальные вещи, но я сам это все проходил. а так хозяин барин, пока мне тут ничем тоже не помогли, explain посмотреть я и сам догадался, на прошлые вопросы вообще никто не отреагировал
Ещё раз: если вы хотите дать ссылку на документ или статью, вы даёте ссылку на документ или статью. Отправлять в гугл с ничего не значащим запросом это неуважительное отношение к человеку с проблемой. Это касается и совета «бери постгрес», который ничем не обоснован.
Если «explain посмотреть я и сам догадался» то поделитесь своими находками. Ответ на вопрос «почему выборка происходит медленно» именно в explain.
Хотите гарантированных ответов то купите поддержку у монги или у сторонних косультантов. Это сообщество, а не служба поддержки.
yopp
Ну все возможные комбинации я не смогу покрыть
Всегда стоит начинать с индексов. Если у вас запросы не используют индекс, то для поиска совпадений монга каждый раз читает и сравнивает все 60+ млн документов. Это очень неэффективно и дорого масштабировать
Составьте карту запросов, выделите самые частые и с них начните. Веротянее у вас есть несколько полей которые используются в большинстве запросов и это хорошие кандидаты на индекс.
Даже если у вас в итоге будет по индексу на каждое поле в этом ничего особо страшного нет.
Vlad
Ещё раз: если вы хотите дать ссылку на документ или статью, вы даёте ссылку на документ или статью. Отправлять в гугл с ничего не значащим запросом это неуважительное отношение к человеку с проблемой. Это касается и совета «бери постгрес», который ничем не обоснован.
Если «explain посмотреть я и сам догадался» то поделитесь своими находками. Ответ на вопрос «почему выборка происходит медленно» именно в explain.
Хотите гарантированных ответов то купите поддержку у монги или у сторонних косультантов. Это сообщество, а не служба поддержки.
про тюнить параметры - любую статью брать можно и читать, о чем вы? это просто указание в расчете на то, что может человек об этом не подумал. про постгрес так же - это гипотеза, а основана она на том, что если структура линейна и нужно большие агрегации и сортировки делать, то постгрес лучше сработает, т.к. заточен под это изначально больше, что основано на личном опите и здравом смысле (возможно я тут не прав и монга и в этом плане лучше).
explain идет так медленно, что пока нечем делится.
ну да, видимо надо дорого заплатить, чтобы узнать, как банально прерывать запрос и не вываливатся из монговской консоли, я уж не говорю про более сложные вопросы
Николай
думать надо, explain смотреть, вообще, чем больше вариативносность поля или комбинации полей для индекса, тем быстрее поиск+погуглите mongo tune+возможно разбить базу на разные части есть смысл. да и вообще может вам не монга нужна, а реляционная БД? постгрес хорошо с индексами работает
я по профайлеру ставил индексы и выполнения сильно упало.
Как пример выборка за 5 дней с индексом по дате и с группировкой(считается сумма 7-10 полей) сейчас занимает 5 секунд.
yopp
Николай
замечательно
yopp
yopp
5 дней это примерно какое количество документов, какой объём?
yopp
какие индексы у вас есть?
Николай
yopp
_id.date это почти всегда фатальная ошибка
yopp
в проектировании схемы
yopp
2.2кк документов за 5с это очень неплохо, это 440к документов в секунду
yopp
у вас документы под килобайт, да?
yopp
я так понимаю вы делаете аналитику над данными от какой-то трекалки событий? у вас 60 млн событий и аналитка строится из набора из 10 различных свойств событий?
Николай
> Object.bsonsize(db.statisticGeneral.findOne())
514
Николай
_id.date это почти всегда фатальная ошибка
а в чем минус?
Скорость записи/выборки или это просто так делать некрасиво?
Al
Всем привет!
Мы допилили проект файлового хостинга. И хотим начать наполнять БД реальными данными.
Сейчас у нас node express, mongo 4, mongoose..
Всё работает без миграций и с дефолтными настройками.
В какую сторону копать и что почитать? Что делать кроме отключения auto index?
yopp
да
судя по цифрам вы уперлись в производительность вашего кластера. у вас есть несколько вариантов как быть дальше:
0) 440k * 512 = ~220Мб/с, что очень неплохо. не уверен что можно выжать больше, но стоит попробовать. на тестовом столе взять срез данных, который гарантированно влазит в память, сделать агрегацию несколько десятков раз, убедиться что монга почти не ходит на диск и посмотреть сколько документов в секунду получится. Если цифра будет существенно отличатся, то стоит добавить памяти. Если не существенно, то повторить всё тоже самое, но уже на более производительном дисковом хранилище, например nvme.
1) оптимизировать схему чтоб сократить объём данных. без данных и понимания нюансов как у вас данные пишутся трудно что-то рекомендовать, но вероятно тут может помочь собрать события в бакеты по паре сотен штук, по какому-то признаку
2) посмотреть возможно ли делать преагрегацию по всем измерениям при вставке
3) вписываться в шардинг. это сходу увеличит ваши издержки на монгу почти на порядок, но даст множество инструментов чтоб увеличить скорость
4) посмотреть в сторону колончатых хранилищ, но это может оказаться сложнее или дороже чем 0-3
yopp
и главное: убедится что вам нужны агрегации в реальном времени. если есть возможность сделать «генератор отчётов», то это может оказаться дешевле чем п. 1-3
yopp
т.е. по запросу ставить в очередь сборку агрегатов, результат агрегации сохранять во временной колекции из которой уже и показывать данные пользователю
yopp
да
ну и конечно воткнуть https://www.percona.com/doc/percona-monitoring-and-management/index.html
чтоб были объективные данные что в кластере происходит
yopp
а в чем минус?
Скорость записи/выборки или это просто так делать некрасиво?
дублируются данные в _id и _id.date, которые там по сути лежат мертвым грузом
yopp
если _id состоит из документа, но для поиска планируется использовать только часть ключей, а не все сразу, то почти всегда стоит вынести эти поля в документ а _id оставить как objectid
yopp
Всем привет!
Мы допилили проект файлового хостинга. И хотим начать наполнять БД реальными данными.
Сейчас у нас node express, mongo 4, mongoose..
Всё работает без миграций и с дефолтными настройками.
В какую сторону копать и что почитать? Что делать кроме отключения auto index?
поставить https://www.percona.com/doc/percona-monitoring-and-management/index.html и по действовать по ситуации
Al
поставить https://www.percona.com/doc/percona-monitoring-and-management/index.html и по действовать по ситуации
Про миграций мы решили отказаться. А данная приблуда, для мониторинга производительности итп?
Al
Или и для управления данными
 Roman
Roman
Ого
Roman
@lynxed
 Zlata
Zlata