https://docs.mongodb.com/manual/tutorial/resync-replica-set-member/
Спасибо. А монга, интересно, планирует в дальнейшем решать этот вопрос? Если так посудить, это явная угроза целостности и доступности данных. Ручками восстановить конечно можно, но почему они не запилят что-то вроде автоматического механизма восстановления в таких случаях? К примеру, вот представим такую схему. У нас отстала реплика, безнадежно, оплог улетел вперед. Вместо того, чтобы перекачивать сразу все начисто, мы можем сравнить контрольные суммы чанков на первичной реплике и контрольные суммы чанков на отставшей вторичной реплике. И при восстановлении реплики задействуются только те чанки, которые изменились (контрольные суммы не совпадут).
Ну, или что-то подобное. Скажу сразу, во внутреннем устройстве хранения в монге слабо разбираюсь, возможно это наивный взгляд.
 Ilya
Ilya


 yopp
yopp
Диффы не помогут
yopp
Хранилище это деталь реализации, так что диффать нечего, потому что на репликах данные будут иметь совершенно иное физическое расположение
yopp
И это не бага, это очень полезная фича, благодаря которой в реплике могут быть ноды с разными хранилищами или разными конфигурациями хранилища (mmap и wt со snappy и со zlib)
yopp
Понял откуда у меня ощущение что монга рестинкалась автоматом: она действительно перезапускает ресинк, если initial sync не успел завершится и нода выпала за оплог. Но это только при initial sync, как механизм retry
 Vlad
Vlad
вашего кейса не знаю, чисто предположил, что может этого хватит
Anonymous
Подскажите, в чем разница полнотекстового поиска и поиска по регекспу /.*search query.*/ ? Какие плюсы и минусы?
Пока что вижу, что полнотекстовый поиск выдаёт поле $score и можно отсортировать по релевантности. Может еще в чем-то разница?
 Nick
Nick
Подскажите, в чем разница полнотекстового поиска и поиска по регекспу /.*search query.*/ ? Какие плюсы и минусы?
Пока что вижу, что полнотекстовый поиск выдаёт поле $score и можно отсортировать по релевантности. Может еще в чем-то разница?
полнотекстовый поиск в монге - это разделение строки на слова, исключая стоп-слова в виде предлогов, и поиск идет уже по полным словам. вроде как есть преобразование слова к начальному виду (убираются окончания). Как следствие вы не можете делать произволдьный поиск по части слова, только по целым словам.
регексп же позволяет задать конкртеную регулярку для поиска
yopp
Подскажите, в чем разница полнотекстового поиска и поиска по регекспу /.*search query.*/ ? Какие плюсы и минусы?
Пока что вижу, что полнотекстовый поиск выдаёт поле $score и можно отсортировать по релевантности. Может еще в чем-то разница?
Такая регулярка не будет использовать индексы, про словоформы уже написали.
 Denis
Kozimjon
Denis
Kozimjon
 Ilya
Ilya
Помогите разобраться с Replica Set. Вот вроде бы это асинхронный тип репликации. Однако, если настроить write concern: w = количество реплик в кластере, то вроде бы получается синхронная репликация (ждет подтверждения от всех, что записалось), и еще поставить j=true, чтобы в журнал на диске писал. Это уже какой-то кастомно-смешанный настраиваемый тип репликации. И синхронной может быть, и асинхронной. Или я чет не так понимаю?
yopp
Помогите разобраться с Replica Set. Вот вроде бы это асинхронный тип репликации. Однако, если настроить write concern: w = количество реплик в кластере, то вроде бы получается синхронная репликация (ждет подтверждения от всех, что записалось), и еще поставить j=true, чтобы в журнал на диске писал. Это уже какой-то кастомно-смешанный настраиваемый тип репликации. И синхронной может быть, и асинхронной. Или я чет не так понимаю?
репликация всегда «асинхронная», write concern определяет условия ACK операции записи
yopp
w: X говорит о том, что ACK будет получен когда операция будет реплицирована на X реплик
Ilya
репликация всегда «асинхронная», write concern определяет условия ACK операции записи
Прошу прощения, а что такое АСК?)
yopp
acknowledgement, ответ клиенту что операция завершилась успешно
yopp
т.е. репликация работа вне зависимости от указанных флагов. если журнал включен то опеация попадёт в журнал даже без j: t, а если не указан write concern то опеация всё равно рано или поздно реплицируется на все ноды
Ilya
acknowledgement, ответ клиенту что операция завершилась успешно
Хммм, а какого рода это подтверждение? Подтверждение, что операция доставлена на реплику и записана в ее оплог, или подтверждение, что операция уже непосредственно выполнилось и в базе данные обновились?
Ilya
Kozimjon
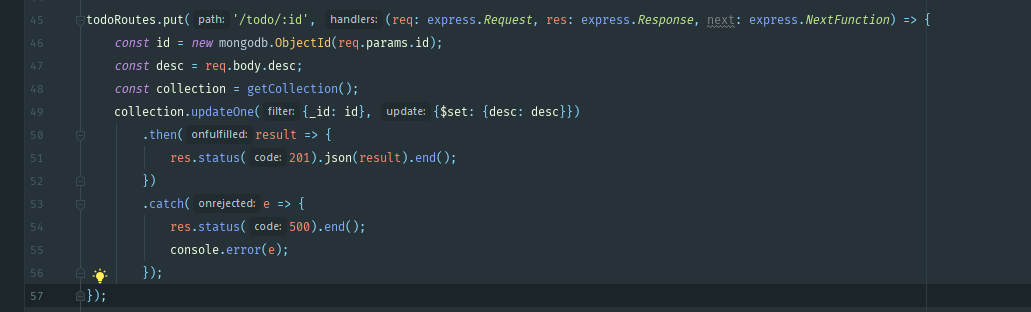
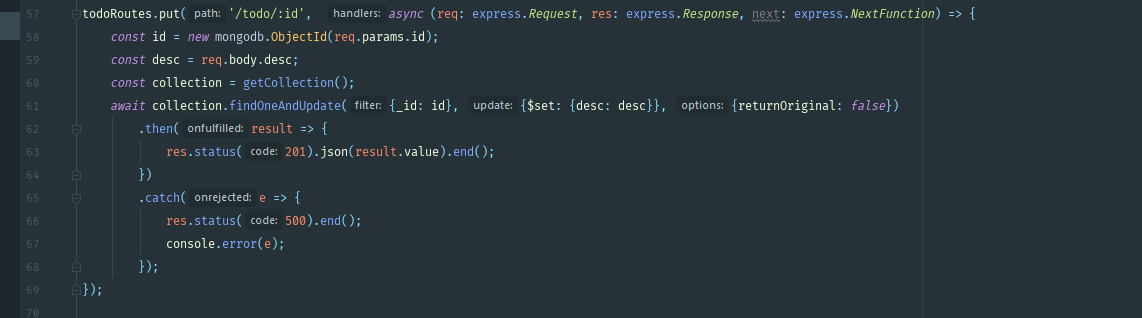
Чтобы получить изменить документ и вернуть обновленную версию без мангуса, используйте функцию findOneAndUpdate с параметром returnNewDocument: true. Кстати, если не хотите погрузиться в callback hell, советую юзать async-await вместо колбэков, если пишите на NodeJS.
 yopp
yopp
Хммм, а какого рода это подтверждение? Подтверждение, что операция доставлена на реплику и записана в ее оплог, или подтверждение, что операция уже непосредственно выполнилось и в базе данные обновились?
https://docs.mongodb.com/manual/reference/write-concern/#acknowledgment-behavior
yopp
https://www.percona.com/software/database-tools/percona-monitoring-and-management
 Joseph
Joseph
Ребята, а можно как то при populate отбросить все idшники которые распопулейтить не удалось , то есть они вернули null
Joseph
Желательно без использования агрегатных функций
 antofa
antofa
Привет. Есть такой массив http://dpaste.com/3T9S8N8
Как добавить в запрос ($project) новое поле product_ids = [1, 2, 3, ...] ? Только через $reduce или есть другой способ?
yopp
Привет. Есть такой массив http://dpaste.com/3T9S8N8
Как добавить в запрос ($project) новое поле product_ids = [1, 2, 3, ...] ? Только через $reduce или есть другой способ?
Да, $reduce вполне подходит для задачи. Кроме $project ещё есть $addToFields, если не хочется перечислять все поля которые должны остаться.
antofa
Ну в моем случае меня интересует только новое поле product_ids.
antofa
@yopp А не подскажешь, как конвертировать objectId ($$this.product_id) в строку в этом запросе? http://dpaste.com/3W5QWM0
antofa
can't convert from BSON type objectId to String
yopp
@yopp А не подскажешь, как конвертировать objectId ($$this.product_id) в строку в этом запросе? http://dpaste.com/3W5QWM0
https://docs.mongodb.com/manual/reference/operator/aggregation/toString/
yopp
У нас есть плейграунд для запросов: play.db-ai.co
 Denis
Denis
https://play.db-ai.co
пытаюсь find потестить. 500 server error :(
yopp
А, всё, приехало из роллбара
yopp
Да, это бага с non-ascii символами, у меня записано поправить
Denis
👍
Ilya
Снова возвращаюсь к теме реплика сета. Появился вот какой вопрос. Допустим, есть кластер: первичная + 2 вторичных. На первичную пошел просто дикий поток операций на запись, в следствии чего вторичные стали отставать и пустились вдогонку - но в отказ они еще не уходят (RECOVERING), получается, в роли догоняющих у них будет статус STARTUP2? И вот самое главное - в этот самый момент происходит полноценная транзакция с w:3 и J:true. По идее, транзакция выполниться не должна и будет отменена? Время на транзакцию же 60 секунд по дефолту отводится, и за это время у нас реплики еще не успевают догнать. Как вариант способ совершения что-то вроде DoS атаки на систему)
 h1dw0w
h1dw0w
Снова возвращаюсь к теме реплика сета. Появился вот какой вопрос. Допустим, есть кластер: первичная + 2 вторичных. На первичную пошел просто дикий поток операций на запись, в следствии чего вторичные стали отставать и пустились вдогонку - но в отказ они еще не уходят (RECOVERING), получается, в роли догоняющих у них будет статус STARTUP2? И вот самое главное - в этот самый момент происходит полноценная транзакция с w:3 и J:true. По идее, транзакция выполниться не должна и будет отменена? Время на транзакцию же 60 секунд по дефолту отводится, и за это время у нас реплики еще не успевают догнать. Как вариант способ совершения что-то вроде DoS атаки на систему)
Нет, у них так и останется статус SECONDARY. Просто будет высокий репликейшн лаг, если действительно будут не успевать синкать с праймари по каким либо причинам
h1dw0w
И хорошо бы иметь алерты, если у вас репликейшн лаг высокий длительное время
h1dw0w
В качестве перестраховки, можете в конфигах монги увеличить размер оплога
h1dw0w
Ilya
касательно DoS атаки, наивно что-то говорить без конкретных цифр =)
Конкретных цифр не имею, к сожалению) Единственное, что есть - попробовал поэкспериментировать с оплогом. Так как мой ноут далеко не самая мощная вычислительная машина, поставил себе размер оплога 1гб (с бОльшим бы банально не справился). Развернул реплика сет: праймари + 2 вторичных. Начал нагружать базу простыми инсертами, и таки удалось развалить кластер: оба вторичных сервака рассинхронизировались. Мне скорее интересна теоретическая сторона вопроса, в образовательных целях)
Ilya
В общем, я пришел к тому, что для создания отказоустойчивого high availability кластера реплика сет хорош, и единственное, к чему можно прикопаться - это как раз вот эта рассинхронизация. Но тут скорее проблема в самой природе механизма репликации. Реплика сет это ведь асинхронная pull-based репликация, поэтому без концепции журнала операций обойтись невозможно. А журнал не может расти бесконечно, иначе он всю память сожрет. Поэтому его приходится ограничивать, и поэтому может возникнут десинх. Вообще я думаю, что было бы здорово написать какой-нибудь простой софт, который восстанавливает реплику в результате десинха.
h1dw0w
В общем, я пришел к тому, что для создания отказоустойчивого high availability кластера реплика сет хорош, и единственное, к чему можно прикопаться - это как раз вот эта рассинхронизация. Но тут скорее проблема в самой природе механизма репликации. Реплика сет это ведь асинхронная pull-based репликация, поэтому без концепции журнала операций обойтись невозможно. А журнал не может расти бесконечно, иначе он всю память сожрет. Поэтому его приходится ограничивать, и поэтому может возникнут десинх. Вообще я думаю, что было бы здорово написать какой-нибудь простой софт, который восстанавливает реплику в результате десинха.
Репликасет помимо отказоустойчивости позволяет масштабироваться по чтению.
h1dw0w
Если нужно еще и быстро писать, тогда возможно стоит смотреть в сторону шардед кластера
Ilya
Репликасет помимо отказоустойчивости позволяет масштабироваться по чтению.
Ну это же как раз про high availability вроде бы) Делигируем запись праймеру, а чтение - вторичным репликам. Я помню кажется, что там был даже такой параметр, как read preference, который определяет приоритетную реплику на чтение
Ilya
Если нужно еще и быстро писать, тогда возможно стоит смотреть в сторону шардед кластера
Хочу поработать с шардированием, но все руки не доходят. Я все жду, когда транзакции на шарды завезут, вот это будет сильно.
h1dw0w
Ilya
В 4.2 вроде как обещают
А есть какая-нибудь инфа, когда релиз? Любопытно попробовать, пусть хотя бы даже в бета-тестировании, как это было в прошлом году
h1dw0w
А есть какая-нибудь инфа, когда релиз? Любопытно попробовать, пусть хотя бы даже в бета-тестировании, как это было в прошлом году
Я думаю, гугл вам больше инфы даст, чем я😁
yopp
Репликасет помимо отказоустойчивости позволяет масштабироваться по чтению.
В очень узком числе случаев
yopp
И это тоже. Репликация это не механизм масштабирования
 Yurii
Yurii
Добрый день монго самураи, есть такой TODO
// TODO: Need to include all possible schemas
properties: { type: Schema.Types.Mixed, default: {} },есть какой то enum только для схем а не стрингов?
yopp
В общем, я пришел к тому, что для создания отказоустойчивого high availability кластера реплика сет хорош, и единственное, к чему можно прикопаться - это как раз вот эта рассинхронизация. Но тут скорее проблема в самой природе механизма репликации. Реплика сет это ведь асинхронная pull-based репликация, поэтому без концепции журнала операций обойтись невозможно. А журнал не может расти бесконечно, иначе он всю память сожрет. Поэтому его приходится ограничивать, и поэтому может возникнут десинх. Вообще я думаю, что было бы здорово написать какой-нибудь простой софт, который восстанавливает реплику в результате десинха.
Если реплики не успевают выгребать оплог, значит в кластере не хватает ёмкости и есть булочное горлышко. Впавшая за оплог реплика это не штатное поведение, которому предшествует увеличение лага репликации. Если вы не обратили внимания на этот симптом, то это уже ваша проблема.
Наиболее реальная ситуация с выпадением ноды за оплог это когда оплога не хватает на время необходимое для обслуживания.
Ёмкость оплога зависит от трёх факторов: среднего размера изменения, количества изменив и размера оплога. Ориентироваться только на размер не стоит.
Про DoS очень странное высказывание. Любое хранилище можно уложить если у вас есть возможность сгенерировать поток операций который будет превышать пропускную способность хранилища.
yopp
А есть какая-нибудь инфа, когда релиз? Любопытно попробовать, пусть хотя бы даже в бета-тестировании, как это было в прошлом году
В шапке ссылка на 4.1.11, это ветка которая станет 4.2
yopp
Думаю что на mongoworld выпустят rc
yopp
4.0.10 (May 31) ◦ 3.6.12 (Apr 8)
События:
• 06 июня, Мск, Доклад: От мегабайт до петабайт не расплескав смузи (Бесплатно)
• 17–19 июня, Нью-Йорк, Конференция: MongoDB World (900$)
• Плейграунд для запросов
• Документация
• Официальные курсы по MongoDB
Stable: 4.0.10 | Bugfix: 3.6.12 | Legacy: 3.4.20 (Mar 13) | Dev: 4.1.13 (May 30)
End of life: 3.2.21 (Sep ’18), 3.0.15 (Feb ’18)
 Максим
Максим
Здравствуйте. Глупые вопросы тут можно задавать? :)
yopp
Можно конечно
Максим
Предположим, есть коллекция students
[
{ "name": "Пётр", "tags": ['MongoDB', 'NodeJS' , 'PHP'] },
{ "name": "Иван", "tags": ['JavaScript' , 'PHP'] },
{ "name": "Илья", "tags": ['C#' , 'MSSQL'] },
{ "name": "Степан", "tags": ['MongoDB' , 'MSSQL', 'MySQL'] }
]
Как мне выбрать список всех тегов c количеством вхождений каждого из тегов? То есть на выходе надо:
{
"MongoDB": 2,
"NodeJS": 1,
"PHP": 2,
"JavaScript": 1,
"C#": 1,
"MSSQL": 2,
"MySQL": 1
}
yopp
Предположим, есть коллекция students
[
{ "name": "Пётр", "tags": ['MongoDB', 'NodeJS' , 'PHP'] },
{ "name": "Иван", "tags": ['JavaScript' , 'PHP'] },
{ "name": "Илья", "tags": ['C#' , 'MSSQL'] },
{ "name": "Степан", "tags": ['MongoDB' , 'MSSQL', 'MySQL'] }
]
Как мне выбрать список всех тегов c количеством вхождений каждого из тегов? То есть на выходе надо:
{
"MongoDB": 2,
"NodeJS": 1,
"PHP": 2,
"JavaScript": 1,
"C#": 1,
"MSSQL": 2,
"MySQL": 1
}
https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/ по tags
https://docs.mongodb.com/manual/reference/operator/aggregation/group и аккумулятор https://docs.mongodb.com/manual/reference/operator/aggregation/sum/
Максим
 Kirill
Kirill
О величайшие гуру, я уже выбился из сил искать ответы. Поэтому пришел за своетом к вам.
Есть бот на nodejs - к нему прикручина сия несравненная базёнка. В опреедленный момент времени, когда количество доков в определенной коллейкции перваливается за ~50 лямов база резко задумывается, когда выполняет регулярную операцию апдейта этих доков (не всех, выборочно и чаще всего в небольшом количетсве). Манипулируя индексами я дошел до определенного уровня удовлетоврения и оставил так на пол годика, потом проблема случилась снова - я подумал, что я пожалуй откажусь от совсем старых данных в пользу скорости и так и сделал, оставил 10 миллионов записей и этого снова хватила на n времени, нынче снова беда пришла в мой и я уже прибег к удалению записей, а проблема не решилась. Пытаюсь теперь максимально точно понять в чем именно проблема и методы её решения. Может есть в монге такое понятие как мониторинг процессов, которые эта божья базёнка исполняет или какой-то максимально удобный мониторинг, который ставиться, как то очень просто)
Версия монги 3.6 (на 4.0 пока сцу обнволять, но уже готовлюсь запасаясь бэкапами)
Kirill
Симпотмы такие - что, в моем понимании, база ловит тяжелый запрос и лочит на это время все остальные, ждет, когда он прососестся и работает как ни в чем не бывало - это не обременено какой-то мощной утилизацией ресурсов или ошибками, вроде.
Kirill
по сути мне и не нужно чтобы этот запрос выполнялся неописуемо быстро, но если бы в параллель могло еще что-то происходить
yopp
О величайшие гуру, я уже выбился из сил искать ответы. Поэтому пришел за своетом к вам.
Есть бот на nodejs - к нему прикручина сия несравненная базёнка. В опреедленный момент времени, когда количество доков в определенной коллейкции перваливается за ~50 лямов база резко задумывается, когда выполняет регулярную операцию апдейта этих доков (не всех, выборочно и чаще всего в небольшом количетсве). Манипулируя индексами я дошел до определенного уровня удовлетоврения и оставил так на пол годика, потом проблема случилась снова - я подумал, что я пожалуй откажусь от совсем старых данных в пользу скорости и так и сделал, оставил 10 миллионов записей и этого снова хватила на n времени, нынче снова беда пришла в мой и я уже прибег к удалению записей, а проблема не решилась. Пытаюсь теперь максимально точно понять в чем именно проблема и методы её решения. Может есть в монге такое понятие как мониторинг процессов, которые эта божья базёнка исполняет или какой-то максимально удобный мониторинг, который ставиться, как то очень просто)
Версия монги 3.6 (на 4.0 пока сцу обнволять, но уже готовлюсь запасаясь бэкапами)
Здравствуйте. Начать стоит со сбора данных о том, что происходит когда запрос выполняется «не быстро».
Например с https://www.percona.com/software/database-tools/percona-monitoring-and-management
yopp
Там есть встроенный профайлер операций, который будет переодически делать currentOp и собирать статистику по тому, какие запросы туда чаще всего попадают
Kirill
спасибо. необходимо ставить на машину с mongo?
yopp
После того как будет видно какие именно запросы вызывают проблемы, по ним можно будет сделать explain и посмотреть какой этап запроса является конрем проблемы и дальше уже искать пути устранения этой проблемы
yopp
к mongod есть смысл только агента поставить, чтоб ещё с хоста собирать информацию
Kirill
прекрасная новость, сейчас разберусь. хоть, помню и пробовал поставить персону
Kirill
а, клиент только под линукс?
yopp
а, клиент только под линукс?
да, но вы можете поднять и агента и сервер в докере/виртуалке и потом руками добавить remote instance
yopp
https://www.percona.com/doc/percona-monitoring-and-management/pmm-admin.html#pmm-admin-add-mongodb-queries
yopp
конкретно вас интересует опция --uri
Specify the MongoDB instance URI with the following format: