 Andrey
Andrey


Вот на эту тему толк кстати — https://channel9.msdn.com/Blogs/Seth-Juarez/Anders-Hejlsberg-on-Modern-Compiler-Construction
 A64m
A64m
да в ghc можно как библиотеку использовать и языковые сервисы ей и пользуются. Просто для нормальной иде мало доступа к парсеру и прочему, для иде нужен в принципе другой парсер чем для компилятора, который максимум из недописанного, т.е. непарсящегося компилятором вытащить может
 Dmitry
Dmitry
Кажется, что авторам языка надо бы давать доступ лексеру/парсеру наружу, как например в шарпе сделано с roslyn
а вот точно нет доступного парсера хаскелла?
 Mikhail
Mikhail
а вот точно нет доступного парсера хаскелла?
Честно говоря, не интересовался, но вангую на кофейной гуще, что каждый костылит кто как может или на крайняк использует добытые реверс инжинирингом кусочки GHC
Dmitry
https://hackage.haskell.org/package/haskell-src-exts плох?
Dmitry
я просто не пользовался - с ним всё плохо?
A64m
но это не ХСЕ
A64m
вот какой-нибудь ghc-exactprint парсит хаскель, использует парсер из ghc
 Зигохистоморфный
Зигохистоморфный
не плохо
https://hackage.haskell.org/package/control-iso-0.1.0.0/docs/Control-Isomorphic.html#v:to
jm
Mikhail Levchenko:
Честно говоря, не интересовался, но вангую на кофейной гуще, что каждый костылит кто как может или на крайняк использует добытые реверс инжинирингом кусочки GHC
--
Мы столкнулись с этим при написании importify. В итоге, один из наших приоритетов в работе с компилятором (которую мы скоро аннонсируем) — упростить использование GHC-как-библиотеки, чтобы людям, которые хотят что-то захачить проще хачилось.
Андрей
https://www.reddit.com/r/haskell/comments/7zti25/junior_haskell_developer_in_singapore/?st=je1mabz3&sh=02c1ce5d
лол, хаскель джун )
Андрей
джун с бородой)
Denis
требования более чем либеральные
М
джунов не возят так далеко
М
в бангалоре найдут
 Alexander
Alexander
Подтверждаю, в Бангалоре Хаскель прет, и джунов там обучают успешно.
Anonymous
https://hackage.haskell.org/package/haskell-src-exts плох?
Парсер пробегает весь файл при каждом изменении текста: enter, paste, пробел и т.д.
Допустим, редактор пишется не на Ха.
Как прикрутить haskell-src-exts? Достаточно ли эта либа быстра для редактирования файлов?
Anonymous
Кметт тыкал палочкой в monoidal parsing, но там приходится накладывать капитальные ограничения на язык.
Dmitry
Imants ну, каким-нить образом 1) написать дамп во что-то еще - json, хаха. 2) прицепить через ffi
Dmitry
а на чём вообще должен быть написан парсер языка, что бы афтарам IDE было удобно?
Dmitry
на си?
Dmitry
джависты проклянут же
A64m
не надо прикручивать haskell-src-exts
Anonymous
а на чём вообще должен быть написан парсер языка, что бы афтарам IDE было удобно?
Для редактора удобнее писать парсер на том же языке, что и сам редактор.
Или изолентой - через tcp
Anonymous
скорость парсера очень важна.
Dmitry
ну т.е получается, что есть пожелание к авторам языка, что бы сделали парсер на том языке, на котором X пишет IDE
Dmitry
черт его знает, почему vim + hasktags не тормозят, а остаьным "скорость парсера очень важна"
Dmitry
ну т.е понятно, что это покрывает процентов 70% только
Dmitry
но в основном хватает.
Anonymous
Да, большинство пользуется быстрыми редакторами:
https://insights.stackoverflow.com/survey/2017#technology-most-popular-developer-environments-by-occupation
Andrei
ну т.е получается, что есть пожелание к авторам языка, что бы сделали парсер на том языке, на котором X пишет IDE
Ну зачем, хаскель можно и Etaой парсить
A64m
хаскельный парсер или уже не компилируется этой или в ближайшее время не будет
Andrei
хаскельный парсер или уже не компилируется этой или в ближайшее время не будет
парсер из GHC для IDE, видимо, не годится, т.к. встаёт колом по любому поводу, да? Поэтому для IDEA всё равно надо писать кастомный, который вполне себе можно запилить и на Eta. Если я всё правильно понимаю.
A64m
теоретически можно, практически нельзя
A64m
не говоря уже про то, что надо и типы получать, иначе от такой иде никакого толку
Andrei
ну да, заниматься этим будет чуть менее, чем никто
 Евгений
Евгений
А есть где-нибудь информация о том, что требуется от парсера для IDE? Какая-нибудь теория под это?
Евгений
Это какая-то версия фаззификации?
A64m
не знаю, ничего такого не видел
 Слава
Слава
а на чём вообще должен быть написан парсер языка, что бы афтарам IDE было удобно?
На немерле. Уже есть инфраструктура, создающая парсеры для языков, с восстановлением при ошибках. Nitra, написанная на Nemerle, автор Владислав Чистяков, бывший сотрудник JetBrains
Оно как раз юниксвейное, работает в отдельном процессе
Евгений
Там ничего не написано же
Евгений
Может я не очень внимательный или может недалёкий, но я там не вижу ни капли информации приближающей к ответу на вопрос "что особенного требуется от парсера для IDE?"
Anonymous
В смысле: особенного?
Почему трудно прикрутить haskell-src-ext к idee?
Слава
Парсер не должен переразбирать все с нуля, когда изменилась одна строчка.
Евгений
Код это не ответ на вопрос. Также как астрономические календари древности не приближают к нас в познании силы тяжести: работает /= даёт воспроизводимую модель
Евгений
Парсер не должен переразбирать все с нуля, когда изменилась одна строчка.
Этого недостаточно. Парсер должен давать какую-то информацию, если парсинг не проходит, как минимум
Евгений
GHC не переразбирает всё с нуля, даже mlton так не делает.
В рамках одного модуля заново выводятся и чекаются типы, максимум
 Artyom
Artyom
> Hello, I work on the C# compiler and we use a handwritten recursive-descent parser. Here are a few of the more important reasons for doing so:
* Incremental re-parsing. If a user in the IDE changes the document, we need to reparse the file, but we want to do this while using as little memory as possible. To this end, we re-use AST nodes from previous parses.
* Better error reporting. Parser generators are known for producing terrible errors. While you can hack around this, by using recursive-descent, you can get information from further "up" the tree to make your more relevant to the context in which the error occurred.
* Resilient parsing. This is the big one! If you give our parser a string that is illegal according to the grammar, our parser will still give you a syntax tree! (We'll also spit errors out). But getting a syntax tree regardless of the actual validity of the program being passed in means that the IDE can give autocomplete and report type-checking error messages. As an example, the code "var x = velocity." is invalid C#. However, in order to give autocomplete on "velocity", that code needs to be parsed into an AST, and then typechecked, and then we can extract the members on the type in order to provide a good user experience.
парсеры для IDE-шек должны обладать кучкой дополнительных свойств
HSE ими не обладает
 Danila Matveev
Danila Matveev
GHC не переразбирает всё с нуля, даже mlton так не делает.
В рамках одного модуля заново выводятся и чекаются типы, максимум
типо-чекалка уже не совсем парсер, не?
Евгений
Тайп-чекинг это совсем не парсер
Danila Matveev
просто разговор не понятно про что
понятия смешиваются
Евгений
Я про фуззификацию парсера спрашивал, а мне почему-то какую-то дичь про пересборку с нуля несут
Danila Matveev
если про идею, то был то ли доклад то ли подкаст на тему как она работает со скалкой
если вспомню, то скину
и реализация весьма извращенная
если так для каждого языка делается, то это ад
Danila Matveev
грубо говоря там свой компилятор
Евгений
В чате по расту сотрудник JB говорил, что они 90 процентов компилятора написалт
A64m
HSE вообще не обладает свойствами парсера хаскеля. Например, не парсит хаскель. Почему тут все продолжают про хсе говорить вообще?
Евгений
если про идею, то был то ли доклад то ли подкаст на тему как она работает со скалкой
если вспомню, то скину
и реализация весьма извращенная
если так для каждого языка делается, то это ад
Но честно говоря всё равно непонятно без пейпера что привело к таким кординальным решениям
Danila Matveev
у оракла есть еще такая (пока исследовательская) штука https://github.com/oracle/graal/tree/master/truffle
Danila Matveev
не очень понятно почему в ридми про динамические языки, в другом месте звучало более обще
Евгений
Полистал jb'шные папиры, ничего не нашёл подходящего: https://research.jetbrains.org/ru/publications
Слава
Здесь посмотрите
https://github.com/JetBrains/Nitra/blob/master/README.md
Зигохистоморфный
кстати у того же jb есть MPS или как-то так
 кана
кана
прелюдии на рекордах вместо тайпклассов еще никто не написал?
Artyom
никогда не видел такой
Зигохистоморфный
прелюдии на рекордах вместо тайпклассов еще никто не написал?
когда-то гонзалес так делал
Artyom
там был пост вроде, а либы не было
кана
я знаю, интересует готовая прелюдия или проектик как пример
мне прям понравилось это, только его подход получения суперклассов из предков не ок, можно же хранить суперкласс в словарике
Зигохистоморфный
Зигохистоморфный
там в апендиксе много чего есть http://www.haskellforall.com/2012/05/scrap-your-type-classes.html
кана
вербозность его подхода можно немного уменьшить RecordWildcard-ом
кана
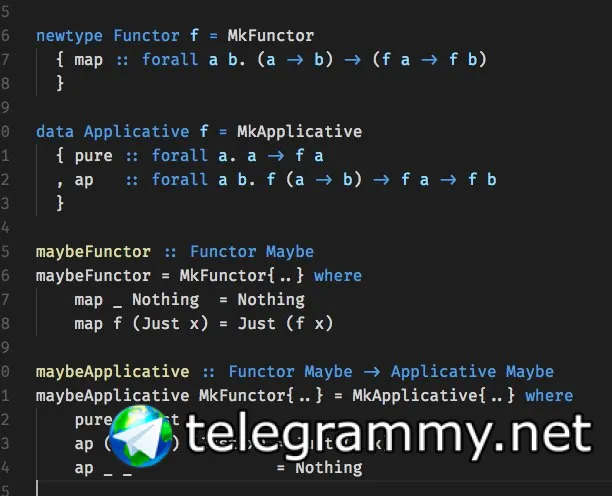 кана
кана
что правда не помогает, когда у нас два функтора
A64m
прелюдии на рекордах вместо тайпклассов еще никто не написал?
http://hackage.haskell.org/package/modular-prelude
 Alexander
Alexander
о бже
Artyom
зачем говорить о дополнительных свойствах, если базовые не поддерживаются?
какие базовые? "должно парсить хаскель"?
 Cheese
Cheese
делать что-то после парсинга, например, запускать компилятор правильной версии
Artyom
стоп, это разве задача парсера?