 Igor
Igor


нам нужна асимптотический выигрыш те в разы а не на доли секунды
Igor
если мы стром дерево то скорость будет логарифмическая на смом деле 2* ln(n) в худшем случае
т е для подмассива длинной 1200 мы получим всего около 20 операций для длинны 65000 всего в районе 30 и так далее я не считаю точные числа потому что это не имеет смысла
Igor
а если у нас корневая декомпозиция то для миллиона операций у нас будет всего 2000 операций что как бы тоже не плохо хотя и хуже чем логарифм
Igor
Для понимания подобных вещей и нужны алгоритмы и теория сложности
Igor
Вообще все это можно прочитать в книжках :) и нахера я занимаюсь этой писаниной не ясно :)
 Виталик Голоенко
Виталик Голоенко
Вообще все это можно прочитать в книжках :) и нахера я занимаюсь этой писаниной не ясно :)
я сделал из [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]
потом все суммы: [6 15 34]
как опять разбить массив?
надо разбивать через цикл while?
Igor
тебе нужно сделать предподсчет этих значений а потом идти по каждому запросу и составлять его из этих кусков
 Дима
Дима
Почитал последние 30 сообщений, стал умным
 Vladislav shvets
Vladislav shvets
 Choir
Choir
может кто-нибудь объяснить разницу между с/с++/с#
 Andrii
Andrii
может кто-нибудь объяснить разницу между с/с++/с#
С: язык который используется или там, где с него переходить не хотят, или там, где этого сделать не могут.
С++: более продвинутая версия С с ООП и вообще ещё миллиардом разных фишек, из-за чего это один из самых (если не самый) мощный инструмент, но так же и очень сложный в освоении.
С#: самый простой из представленных, так как находится на более высоком уровне, похож на Java.
Использование:
С - embedded (в основном)
С++ - embedded, микроконтроллеры, разработка игр (ААА, Unreal Engine), всякие там Oculus'ы и тому подобные устройства
С# - бэкэнд сайтов, разработка приложений под Десктоп (в основном), разработка игр (инди или небольшие проекты, Unity), автоматизация тестирования и вроде бы ещё на нем умудряются под Андроид писать, но это костыли
Andrii
Поправьте, если где то ошибся
Choir
о
Choir
спасибо
Choir
ещё хотел спросить, стоит ли переходить на линукс, или разницы нет?
Andrii
Если незачем то лучше не стоит xd
Choir
для быстродействия наверное, если оно вообще будет при переустановке
Choir
плюс, как мне кажется майнер словил, либо слишком много хлама который лень удалять
Andrii
плюс, как мне кажется майнер словил, либо слишком много хлама который лень удалять
Ну так можно просто Шиндовс переустановить
Andrii
Ну вообще, если чего то новенького хочется, то можно и попробовать
 Oskar
Oskar
лично мне удобнее работать под линуксом, нежели под виндой, может сугубо субъективщина, но система поприятнее устроена
если комп нормальный, возможно будет проще wsl2 накатить
Choir
вот кстати да, новенькое и хочется
Igor
я сделал из [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]
потом все суммы: [6 15 34]
как опять разбить массив?
надо разбивать через цикл while?
Ну кстати мемоизация пишется легче чем рассказывается :) и заходит так что ограничения там не жесткие.
def compute_ranges(arr, op, rs):
memoization = {}
def query(a, b, s=1 << 16):
if a == b:
return arr[a]
if (a, b) in memoization:
return memoization[(a, b)]
while (a | (s - 1)) >= b:
s >>= 1
m = a | (s - 1)
r = op(query(a, m, s // 2), query(m + 1, b, s // 2)) if b > m else query(a, m, s // 2)
memoization[(a,b)] = r
return r
return [query(a, b-1) for a, b in rs]
 Alexander
Alexander
Мой опыт обучения на курсах DevOps компании GeekBrains / Хабр
https://habr.com/ru/post/573994/
Alexander
Это не мое, есичо
Igor
@nuu44a :) задача тебе на вечер
https://www.codewars.com/kata/608cc9666513cc00192a67a9
Виталик Голоенко
Виталик Голоенко
хотя все по дереву сделал
Igor
Нет ты не по дереву сделал
Igor
ты сделал sqrt декомпозицию
Igor
она быстрее но не достаточно быстрая значит
Виталик Голоенко
так оно все разбивается, как в дереве
Igor
нужно писать дерево те не один уровень а несколько
Igor
ну во первых предподсчет делается один раз на весь массив и он зависит от длинны arr а не от длинны ranges
Igor
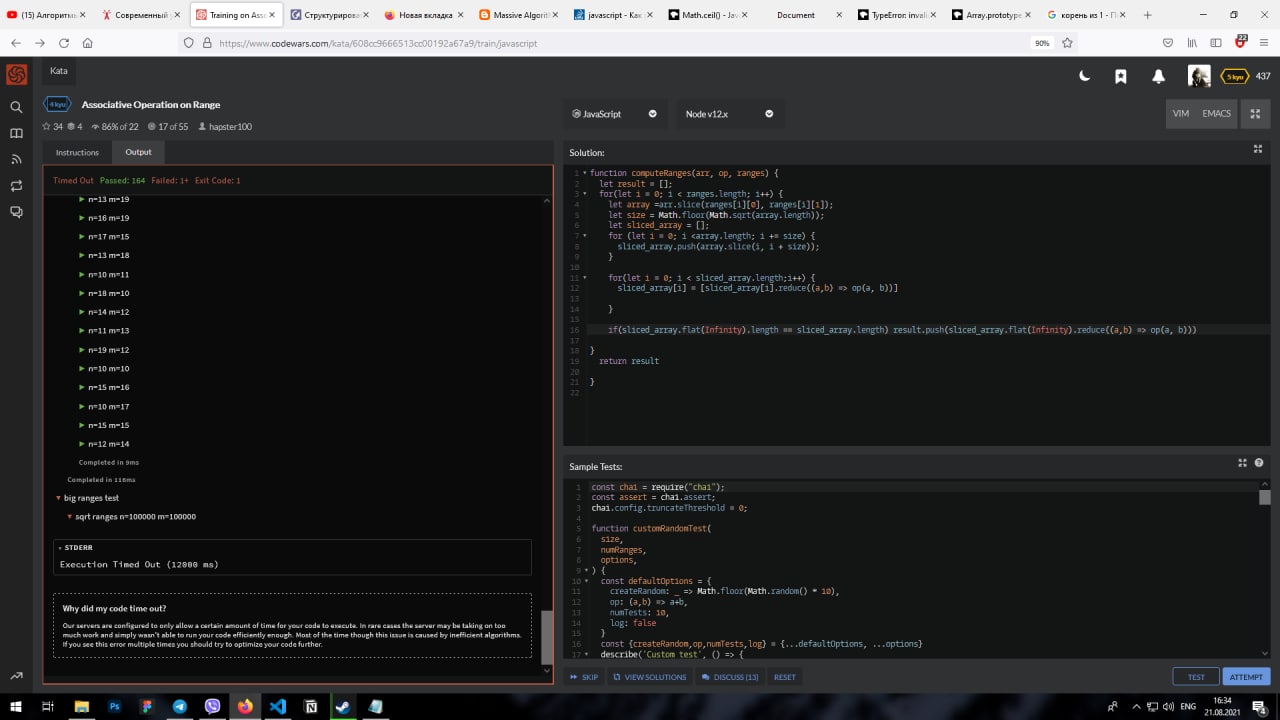
я в твоем коде честно говоря вообще с трудом понимаю что ты делаешь. зачем какой то флэт
Виталик Голоенко
flat() рекурсивно поднимает массив как flatten в пайтон
Igor
это я понимаю я не понимаю зачем
Igor
то что ты просто нарежешь это ничего не даст
Igor
ты должен посчитать диапазоны заранее например с [1024..2047] и везде куда он входит добавлять его
Igor
а у тебя просто разваливается в дерево и потом ты каждый раз считаешь конечно это ничего не ускорит
Igor
мы выше обсуждали что должно прокатить :) и сложность там указанна в условии что вообще редкость.
Igor
через while?
 Igor
Igor
и чем больше будет изначальный массив тем выгода будет больше
Igor
ну или чем сложнее операции вместо чисел могут быть матрицы например там в тестах
Виталик Голоенко
 Виталик Голоенко
Виталик Голоенко
ну или чем сложнее операции вместо чисел могут быть матрицы например там в тестах
У меня кста матрица тож не проходит, хз почему
Igor
Твой код не понятно что делает он сперва должен построить верхние массивы а потом ходить по массиву ranges у тебя же все на изнанку.
Плюс в результате предподсчета у тебя должен получиться двумерный массив я его не вижу в коде. да его можно впихнуть в одномерный но это будет еще одна задача поэтому проще делать двумерный.
Igor
и массивы должны строиться каждый на основе предыдущего а не все на основе первого
Igor
тогда на постройку массивов ты потратишь всего N операций
Anonymous
ВСЕ СЛУШАЕМ ИГОРЯ!!!
Anonymous
Игорь кстати, привет) как жизнь?)
Igor
Если сейчас это сложно может и не стоит себя мучать. Вообще это называется Segment Tree или дерево отрезков можешь посмотреть видео или почитать может я рассказываю криво. Если всеравно сложно попробуй темы попроще по типу RMQ и т п идеи. Нужно покодить алгоритмы чтобы привыкнуть к подобным реализациям.
Igor
Игорь кстати, привет) как жизнь?)
Нармальна сегодня валю к родокам в село :) Всетаки день независимости на носу :) буду независимым от жены
Anonymous
Igor
Тихо ты я еще не свалил :) ща жена спалит и мне пизда :)
Anonymous
Я притворюсь что нечего не говорил и вообще меня тут нет)
Anonymous
 Anonymous
Anonymous
Чем больше я начал кодить, тем больше стал походить на бомжа. Я это замечать стать
Anonymous
Стал*
В последнее время много бессонных ночей, вчера вообще с сеньором до 11 мои ошибки разбирали
Alexander
@nuu44a :) задача тебе на вечер
https://www.codewars.com/kata/608cc9666513cc00192a67a9
Я, видимо, не совсем понял задание.
Ассоциативных оператора у нас два + и *.
Нужно просто найти сумму или произведение всех чисел в выборке из массива?
Igor
Чем больше я начал кодить, тем больше стал походить на бомжа. Я это замечать стать
сегодня выяснили что терминальная стадия это покупка пакета нивея
 Igor
Igor
Я, видимо, не совсем понял задание.
Ассоциативных оператора у нас два + и *.
Нужно просто найти сумму или произведение всех чисел в выборке из массива?
нет ассоциативные операции это умножение матриц, конкатенация строк, gcd да море их и некоторые очень дорогие поэтому нужен алгоритм который сможет на пересекающихся подотрезках более оптимально посчитать чем каждый подотрезок отдельно.
Igor
Класическая задача на https://e-maxx.ru/algo/segment_tree
Alexander
 Vladislav
Vladislav
 Баба Яга
Баба Яга
Парни, парсер нашёл 2 одиновых объекта и выдаёт ошибку, как выбрать один из них
Igor
у тебя есть массив длинной 1 000 000 и есть миллион запросов найти сумму ячеек с по нужно на все запросы ответить и ответы вывалить опять в массив
Alexander
Нет ограничения по видам операций, кроме ассоциативности, нет ограничения по типу данных...
Igor
Нет ограничения по видам операций, кроме ассоциативности, нет ограничения по типу данных...
тебе передают операцию как функцию ты просто ее применяешь
Alexander
Надо подумать... Над условием 😂
Виталик Голоенко
Если сейчас это сложно может и не стоит себя мучать. Вообще это называется Segment Tree или дерево отрезков можешь посмотреть видео или почитать может я рассказываю криво. Если всеравно сложно попробуй темы попроще по типу RMQ и т п идеи. Нужно покодить алгоритмы чтобы привыкнуть к подобным реализациям.
Да это сложно, но я хочу до конца решить ее, хоть мой код убогий, там чуть чуть доделать переделать и готово, так шо до затвра я скину решение:)