 hlomzik
hlomzik


и моя пашет, но твоя лучше и полнее :)
 Serhii
Serhii
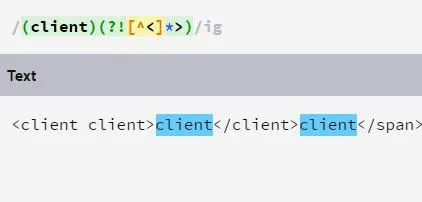
я не понимаю почему не выделено клиента который в теге
Serhii
в лукапе негативном написано />
Serhii
но зачем негативно искать если слово уже вне < >
hlomzik
так стоп. что тебе нужно? для меня на скрине именно то, что ты просил. или нужно, чтобы это не было частью самого тега?
hlomzik
у тебя второй клиент подпадает под вторую часть лукапа
hlomzik
"после слова не должно быть закрывающегося тега"
 Anonymous
Anonymous
регулярки шатаете?
Serhii
так стоп. что тебе нужно? для меня на скрине именно то, что ты просил. или нужно, чтобы это не было частью самого тега?
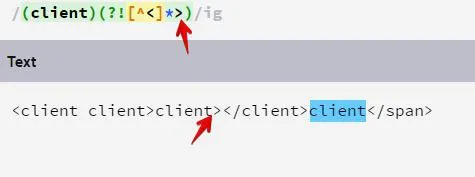
выбрать все слова вне тега, не название тега, не атрибут, но как текст в контенте тега
hlomzik
ну так ты добился своего. пруф на скрине
Serhii
именно это напрягает <\/
hlomzik
текст в контенте тега норм?
Serhii
 Serhii
Serhii
ладно, я плохо сформулировал
Serhii
слово не есть частью тега
Serhii
но может быть в контейнере
Serhii
выходит да
Serhii
 Serhii
Serhii
но и теперь говнецо
Serhii
 Дима
Дима
Регуляркой парсить грамматику html это весело
Ярослав
А разве подобные символы не рекомендуется заменять мнемониками?))
Serhii
слишком весело
Дима
Столько всего интересного узнаёшь
Дима
Приятно проводишь время
Дима
В выходные
Anonymous
а либы для ноды нет, по парсингу?
Дима
Короче, советую на этом этапе уже остановиться с регулярками 😄
Serhii
не верю что заескейпить слова меджу < /> так сложно
Serhii
точ, двойная группа
Anonymous
ты кстати я надеюсь, на 101 сайте?
Anonymous
ибо там есть второй, он фигню выдает порой
Serhii
мой любимый http://regexr.com/
Anonymous
да, лучше на 101 иди
Anonymous
первая страница гугла
hlomzik
Serhii
хм, в принципе можно разделить контент где я точно знаю что будет хтмл и где его не будет
Serhii
тоесть две регулярки отдельно на хтмл и контент обычный
Дима
Ты уже близок к определению нормальной токенизации))
Serhii
блииин, ебучий реплейс в жс реплейсит весь регекс, курва еще нужно отдельную группу для сохранения верстки
Serhii
пздц
Serhii
што за жизнь
Serhii
new RegExp((<.*>.*)(${word})(.*<\/.*>)
Serhii
не регекс а мичта
Anonymous
вот, это в парсинге регэкспами и геморрой
Serhii
переводится регекс - мне на все посрать сохрани мне ебучий ворд
Anonymous
нужно попробовать свой стак сделать с проверками, как @ZeroBias сделал. будет удобнее справляться с любым парсингом
Serhii
не люблю я регулярки в жс... читая доки по с# и пыхе, в жс они вообще кастраты
Anonymous
ну учитывая, что у нас методы ещё распилины на строки и регекспы
Anonymous
кривовато выглядит
Anonymous
ну хоть литералы есть
Anonymous
уже хорошо
Дима
В идеале нормальный токенизатор работает в потоке, то есть регэксп вообще не нужен, просто продвинутая функция-генератор, никогда не пробегающая по одному символу больше одного раза
Дима
Но тут уже конечный автомат состояний надо, это не сложно, но только когда делаешь это во второй раз 😄
Serhii
регекс не сможет - иф есл нам поможет
Дима
Конечный автомат — это обобщение if else в удобной форме
Если у тебя встретился символ <, значит всё последующее — название тэга, так и запишем, состояние "название тега", если дальше опять встречаем < то это фигня какая-то, так и запишем, состояние "синтаксическая ошибка", если же встретим /> то значит тег закрылся и мы опять в исходном состоянии
Вот обобщая эти переходы, получаем тупо функцию-switch case для одного (текущего) символа, список состояний, и квадратную матрицу, по которой эта функция переходит из одного состояния в другое
Дима
Выглядит и программируется это правда проще, чем описывается)
 Oleg
Oleg
Нужно только не забыть что внутри строк могут быть любые символы
Дима
Это просто ещё одно состояние
Oleg
А стейт-машины вообще торт
Oleg
Очень сильно упрощают код там где они применимы
Oleg
Вместо 100500 ифов у тебя простой плоский свитч
Oleg
Добавлю - 100500 вложенных в том числе ифов
Дима
Я как-то с помощью них в универе just for lulz сделал интерпретатор паскаля на паскале))
Serhii
Нужно только не забыть что внутри строк могут быть любые символы
потому в строке у меня нету проверок кроме /${word}/ а при наличии хтмл <.*>.*(${word}).*</.*>
Serhii
одни точки и звезды
Serhii
хотя, а что если написать найти все что вне скобок и все что внутри скобок
Serhii
а в реплейсе просто передать функцию вместо сабстринг с заменой если есть $1 или $2
Oleg
Надо будет как-нибудь что-нибудь такое большое написать на голых стейт-машинах
Serhii
короч получилось без иф есл
Oleg
👍
Serhii
если это строка не хтмл то замена по первому если хтмл тогда замена по второму
Serhii
reg = new RegExp((${word})|(<.*>.*)(${word})(.*<\/.*>), 'gi');
text = text.replace(reg, (match, w1 = '', html1 = '', w2 = '', html2 = '') => ${html1}<span class="highlighted">${w1 || w2}</span>${html2});
Serhii
давай признавайся кто ты #whois
 Daniil
Daniil
американский идиот, очевидно же
Alexander
почитать зашел