 Yuriy
Yuriy


Аха
Кстати функция обязательно анонимная должна быть?
Yuriy
Или я могу подпихнуть свою с ее какими либо входными параметрами?
 Snusmumriken
Snusmumriken
Свою. Только первый аргумент - строка (собсно, то что выдралось из оригинала по шаблону), и выходная фигня тоже должна быть строкой.
Yuriy
оке
То есть 2,3,4 она сожрет как ни в чем не бывало
Это хорошо. спасибо.
Snusmumriken
Но сам gsub будет пихать только одно значение. Или, кстати, может быть несколько (допустим, ещё порядковый номер замены или сдвиг позиции текущей замены), я не помню точно.
Yuriy
ок. спасбо. Буду делать .В обещм понятно
Пробежаться по таблице
Получить путь до переменной
Сравнить со строкой
Заменить
Snusmumriken
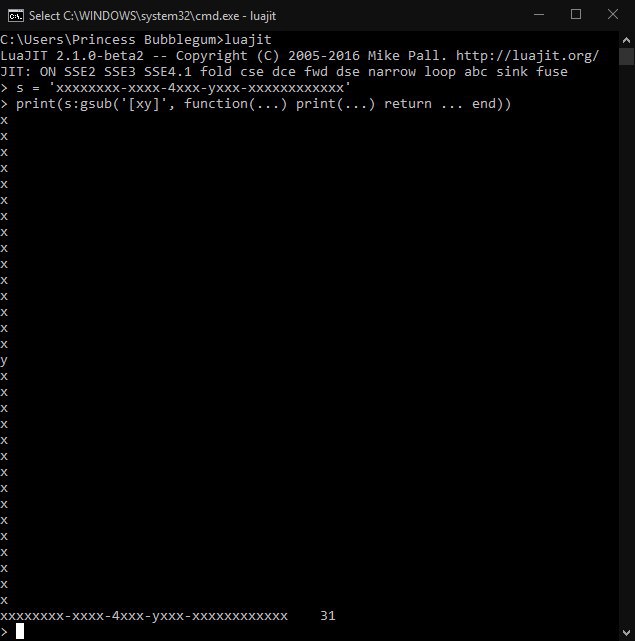 Snusmumriken
Snusmumriken
В луа, без анонимных функций нельзя сделать разве что итераторы. И то, кстати, можно, но это будет извращение.
Всё остальное может быть произвольным, хотя с лямбдами бывает удобнее. Я, вон, вообще мутил генератор лямбд.
Snusmumriken
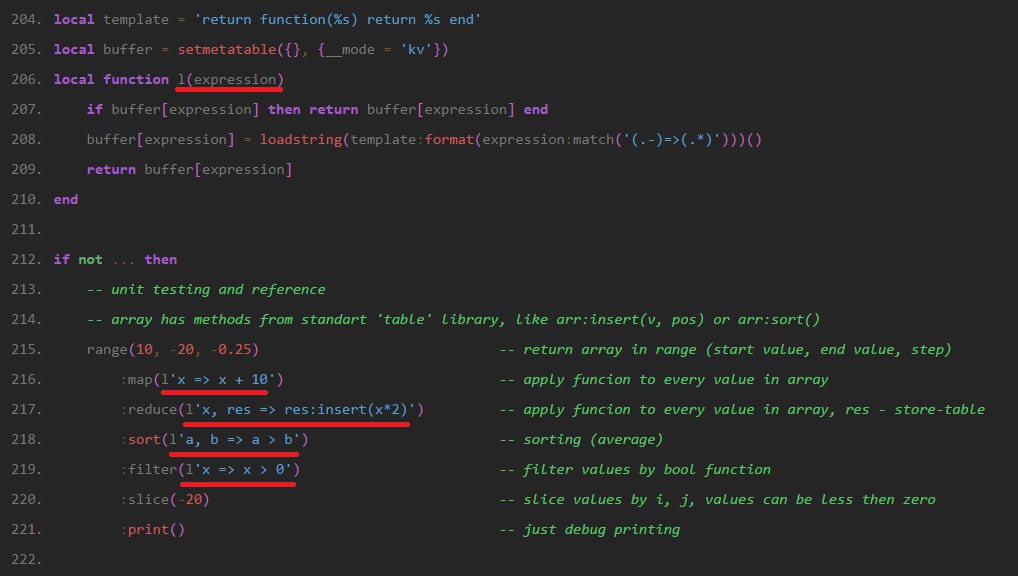 Snusmumriken
Snusmumriken
Преобразует 'x => x + 10' в function(x) return x + 10 end
Зачем? Потому что мне лень писать кучу длинных слов. Сама концепция стрелочных функций сворована из жаваскрипта. Если код перед запуском пихать в препроцессор, то можно нехило расширять синтаксис без подобных манипуляций со строками, но такое тоже ничего так.
Кстати, вот тебе пример loadstring'а.
 Roman
Roman
А я нашел математическую задачку в книге "Хайнойская башня", и захотелось бенчмарки сделать на moonscript, coffee и ruby, сахарки чтобы объем кода тоже был критерием, кому любопытно что за сколько?
 void *
void *
Мне
Roman
Итак, lua: 1.24сек, js: 5.43сек, ruby: 43.9сек
Snusmumriken
Хех, победит moonscript, если luajit в качестве виртуалки. Проиграет руби потому что нет jit.
void *
Неудивительно)
Snusmumriken
А, ну типа того.
Snusmumriken
У тебя v8 в качестве двигла js?
 🦥Alex Fails
🦥Alex Fails
На си++ написать, и у него время выполнения будет 0
🦥Alex Fails
(Потому что автор упоролся, и решил задачу на этапе компиляции)
Snusmumriken
Смотря как. Истинные гуру с++ могут написать так, что бесконечности будет мало.
Snusmumriken
Рекурсивные функции нельзя решить на этапе компиляции, вроде. Хоть template и работает на этапе компиляции, но при рекурсии и время исполнения будет не 0.
Roman
код на мунскрипте самый компактный, на coffee самый длинный, потому что там нет параллельного присваивания
Roman
код полностью идентичнен
Roman
это 26 дисков, в оригинале 64 диска, и когда все передвинутся - будет конец света, но конца света очень долго ждать
Roman
модуль вайфая в линухе просто жесть, вырубается когда хочет
Roman
эм, c++ что-то решает на этапе компиляции? в него хаскел добавили в новых версиях разве?
void *
эм, c++ что-то решает на этапе компиляции? в него хаскел добавили в новых версиях разве?
Шаблоны, constexpr, ...
Snusmumriken
> код на мунскрипте самый компактный
Трансформируй код мунскрипта в луа, и ты увидишь самый длинный в мире код. Там реально - очень, очень много замен.
Меня слегка раздражает куча препроцессоров перед исполнением. Это как less над css, которое не делает ничего кроме парсинга и автозамен, каждый раз когда исполняется код (хотя мб можно закешировать).
Это как будто мы транслируем цепочку из десяти языков, один в другой. Нехило замедляет, кстати, и требует встраивания кучи препроцессоров.
Roman
зря ты так
Roman
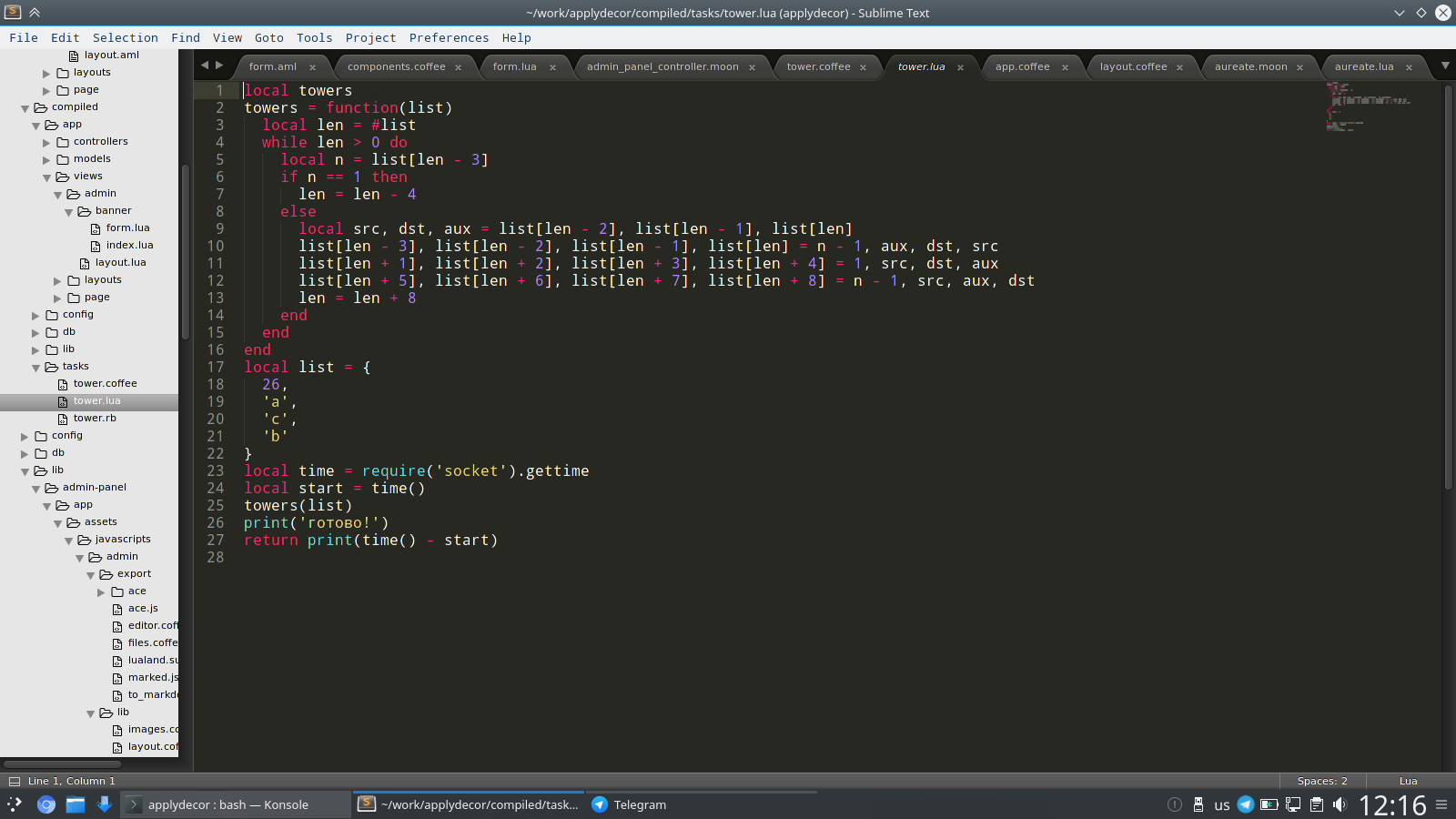 Roman
Roman
нормальный код
Snusmumriken
Да, с++ умеет многое вычислять на этапе компиляции, и использовать результаты. Скомпилированный код занимает чуть больше пространства, но какое-нибудь вычисление занимающее 100500 суток начинает занимать близкое к нулю значение.
Roman
да, именно он
Snusmumriken
А, ну тут может быть, потому что нет ООП/лямбд и прочего синтаксиса. Обычные функции занимают почти столько же пространства.
Roman
тью, конечно если пишешь class в мунскрипте, в lua будет намного больше строчек
Roman
в общем не хочу спорить, лишнего moon не делает, только иногда do end добавляет
🦥Alex Fails
Рекурсивные функции нельзя решить на этапе компиляции, вроде. Хоть template и работает на этапе компиляции, но при рекурсии и время исполнения будет не 0.
Да не, можно. Чувак на хабре даже квиксорт натэтапе компиляции делал.
🦥Alex Fails
Есть же constexpr
Snusmumriken
ООП попробуй замутить, с метаметодами.
В моей жизни, мне действительно понадобился препроцессор в одном месте: либа-надстройка над многопоточностью, где код пихающийся в дочерний поток - строка. В дочерний поток дописывается однострочник с объектом для взаимодействия с родительским и ещё кучей потоков, а так же имя из родительского: между потоками стоит открыть дуплексный именованный канал, который работает по умолчанию и присобачивается к эвент-лупу для взаимодействия потоков, и тут нужно определить имена каналов для входящих-исходящих соединений.
Roman
setmetatable и getmetatable одинаково одна строка
Roman
не понимаю о чем ты
Snusmumriken
Лучше сурц и скомпиленное скинь на pastebin.com.
Roman
он не умеет в подсветку
Snusmumriken
Умеет в подсветку луа, не умеет в мунскрипт. Но это ничего страшного.
Roman
https://pastebin.com/ShKRDLd1
Snusmumriken
А, ну это понятно. Прости, я имел ввиду, замутить что-нибудь сложное в мунскрипте с ООП, перегрузками и лямбдами, а потом трансформировать в луа и посмотреть на разницу.
Roman
пример можешь?
Snusmumriken
На луа?
Сам не пишу на мунскрипте, придётся что-то переписать.
Roman
пример того, о чем говоришь
Roman
пруф слов
Snusmumriken
Пруф чего, прости?
Roman
Так, это не утверждение, что мун лишний код делает, а предположение?
Roman
Не понимаю! Это все равно всеми любимый луа! ООП такой же + class, перегрузка - присвоить переменной другое значение, тут лишний код невообразим, лямбда - это анонимная функция? Эти термины из других языков, мне не очень понятны.
Roman
это синтаксический сахар, делает синтаксис более удобным, end, function и т.д можно опускать, он по задумке своей не должен лишний код генерировать. Там есть специфические фичи, которые можно использовать, а можно и не использовать
Snusmumriken
Смотри. Пример с официального сайта.
class Thing
name: "unknown"
class Person extends Thing
say_name: => print "Hello, I am #{@name}!"
with Person!
.name = "MoonScript"
\say_name!
Превращается в (тут можно посмотреть): https://moonscript.org/
На луа, это можно было бы сделать примерно так же:
Thing = {}
Thing.__index = Thing
setmetatable(Thing, {__index = Thing, __call = function(self, name, ...) return setmetatable({__name = name}, self) end})
Person = {}
Person.__index = Person
setmetatable(Person, {__index = Thing, __call = function(self, name, ...) return setmetatable({__name = name}, {__index = self})
function Person:say_name() print(self.__name) end
Ну, длина увеличилась не сильно. Но в сравнении со сгенерированным кодом, тут значительно меньше пространства.
Да, тут есть проблемы с комфортом, но не вижу проблемы написать либу ООП и подключать её отдельно, хоть и без такого синтаксического сахара, как стрелочные функции, например.
Проблема в другом: мунскрипт генерирует огромную кучу кода в каждом файле. Он мог бы дописывать маленькую либу ООП перед каждым файлом, где используется ООП. Это довольно быстро. Но оно предпочитает генерировать на каждый класс огромную портянку всякой фигни.
И отладка этого счастья превращается в что-то похожее на ад и израиль, особенно когда у тебя что-то сложное, каскадно-рекурсивное. Вместо того чтобы копаться в собственном коде, приходится копаться в сгенерированном, что, согласись, является приличной проблемой: ты не знаешь где точно ошибка, ибо интерпретатор указывает на положение в сгенерированном коде, а в сурцах мунскрипта это совсем в другом месте. Дебаггер тут мало помогает, потому что мунскрипт ещё и пихает кучу своих переменных/функций/данных.
Snusmumriken
И поддерживать сгенерированный мунскриптом код, если нет сурцов, довольно стрёмно.
Roman
Да, эту проблему подтвержаю, с отладкой, но! Делал отладчик, давно делал, он уже сломался, но починю как будет время. Суть отладчика: с помощью debug библиотеки он собирает всю инфу о файлах и строчках кода и выдает то же самое, но с указателями на мун файлы с мун строчками кода, эта проблема решаема
Snusmumriken
А если нет мун-файлов? Ты уже всё упаковал, скинул в проект пол года назад, благополучно профукал сурцы мунскрипта и вот, у тебя вылезла ошибка. Тебе придётся разбирать проект полностью заново.
Нет, мне нравится синтаксис и количество сокращений кучи слов.
Я искренне ненавижу писать большое количество слов, для того чтобы делать простые вещи. Да и сложные тоже.
Но я пишу сахарные библиотеки, и это оказывается эффективнее препроцессоров.
Roman
классы никто не запрещает делать как ты хочешь, можешь свою реализацию сделать и грузить реквайром
Roman
а исходники конечно нужно хранить, на то они и исходники
Roman
что если ты скомпилируешь си проект и благополучно выкинешь весь си код? то же самое
Snusmumriken
А я не люблю хранить лишние исходники. Скрипты - на то и скрипты, что в них всегда можно залезть и поправить.
Поэтому я не очень люблю компилируемые языки.
Можно, конечно, подключать свои либы ООП. Но тем не менее, тут же появляется куча "если". Я могу заменить почти весь сахар мунскрипта библиотеками, и получить крайне читаемую штуку.
Roman
Гитхаб вовсе не запрещает хранить все хоть пол года, хоть 10 лет
Snusmumriken
Хех, тем не менее.
А теперь смотри, что мне нужно сделать для проверки кода на мунскрипте:
1. Пересобрать сурцы
2. Запустить проект
Это ровно в два раза больше действий чем в луях.
Скрипты на то и скрипты, что их можно запускать прям сразу.
Ну блин, мунскрипт хорош, но он убирает почти все плюшки скриптов, за которые лично я их люблю.
Snusmumriken
Это хорошая штука для крошечных проектов, но для крупных - фигня.
Roman
Я как веб разработчик в этом ничего плохого не вижу. Там тебе и coffee, и stylus, и ещё куча всякой фигни, которую прекомпилировать надо, сейчас странные нехорошие веяния ещё кучу страшных вещей насаждают, вроде бабеля
Snusmumriken
Крошечные проекты, чувак. Но и в крошечных - лень.
Попробуй прочитать стактрейс глубины 20 луа-кода, скомпилированного в мунскрипт.
Roman
А тут в дело вступает jit
Snusmumriken
Стактрейс.
Ты знаешь что это?
Его надо читать, при падениях.
Roman
На руби стактрейс раз в 50 больше, чем в самом сложном проекте на луях
 Tverd
Tverd
Да ладно, не все так страшно, как Снус описывает, с удовольствием пользуюсь мунскриптом, когда надо побыстрому
Snusmumriken
Там он за счёт рельсов, которые делают 100500 оболочек над базовыми вещами.
Roman
Да, руби == рельсы же
Snusmumriken
Да ладно, не все так страшно, как Снус описывает, с удовольствием пользуюсь мунскриптом, когда надо побыстрому
Вот, Крошечные Проекты По Быстрому.
И я сказал что тут это неплохо.
Tverd
Неа, целая игра
Snusmumriken
Боюсь что в твоём варианте, это всё равно крошечный проект.
Сколько файлов используется? Какой уровень абстракции?