Lucky
Lucky


ну, они делают то же самое, да
Lucky
воспринимают одномерную проекцию двумерногог мира и достраивают в уме.
Lucky
но концепция высоты им недоступна
 Snusmumriken
Snusmumriken
 Lucky
Lucky
ещё анимацию добавь
Snusmumriken
В пейнте, да
Lucky
тыж программист
Snusmumriken
 Lucky
Lucky
напомните, завтра продолжим.
Snusmumriken
А мне внезапно стало очень интересно, как циклопы из heroes of might and magic кидают свои булыжники.
Lucky
тема интересная
Snusmumriken

 Валентин
Snusmumriken
Валентин
Snusmumriken
А потом прилетела толпа фей и заколбасила его без ответного удара.
Валентин
глаз выбила
 Anonymous
Anonymous
Движок 2д игра 3д😂
Snusmumriken
Ну тот же doom вполне имел карту высот. Можно было запрыгнуть на препятствие и расстреливать тех кто за ним.
Anonymous
Ну тот же doom вполне имел карту высот. Можно было запрыгнуть на препятствие и расстреливать тех кто за ним.
А вот это просто создатели дума всё продумали вроде
Anonymous
Движок вроде не позволял, а они с телепортами как-то сделали
fgntfg
Кармак гений
 🐅🤦♂️
🐅🤦♂️
я понимаю это, но не понял как это сделать. вот и пришлось думать через хттп
Кстати в исходниках luasocket в папочке etc есть пример forward.lua, который делает примерно то, что тебе нужно.
Snusmumriken
Но оно там длинное и не очень понятное, надо разбирать
Snusmumriken
А при стрёмной обработке может произойти что-то страшное.
Например, ты такой вызываешь луёвые функции пакетом, с разными аргументами. Часть аргументов может недоочищаться, и стек оказывается под угрозой переполнения.
Snusmumriken
Ну, я как раз про колбеки, когда ты такой:
for (int i = 0; i < сcallback; i++){
struct foo * = callback[i];
lua_getglobal(L, foo->funcname);
lua_pushstring(L, foo->a);
lua_pushstring(L, foo->b);
lua_call(L, 2, 1);
if(lua_isboolean(L, -1)) do_something();
}
Если тут ещё и количество аргументов разное, а при некоторых условиях мы заполняем стек аргументами но не вызываем функцию (например, её не существует, или при каких-то обстоятельствах нужно подставить вместо неё другую функцию с чуть другими аргументами) — ваще треш, со стеком начинает твориться куча странного.
Snusmumriken
Тут бывают очень, очень разные ситуации : )
Snusmumriken
Ну, с такими условиями норм.
Snusmumriken
 Anonymous
Anonymous
Знаешь в чем отличие группы по питону в телеге и этой?
Anonymous
В комьюнити*
Snusmumriken
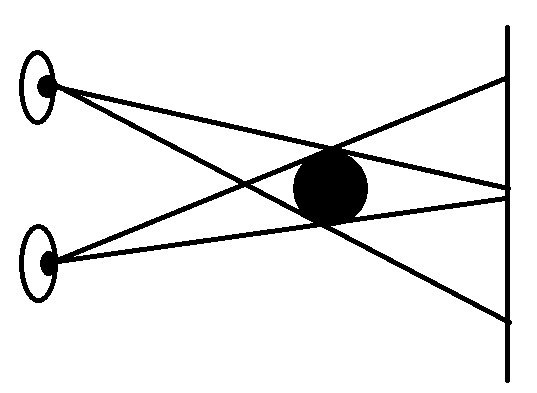
this->CallCallback — вызывает конкретный пользовательский колбек, именно для данного вызова
Friend:getAvatar('large', callback_func). И он проверяет, если эта функция вернула true — оставляет её на будущее. Но этого колбека может не быть.
this->CallUserFunction — вызов общеиспользуемого "глобального" колбека типа
steam.callback.avatarImageLoaded(friend, something)
Тут уже не надо ничего проверять, и в целом вызов другой.
И вот эти функции перетасовывают стек довольно активно.
Snusmumriken
Ну например?
Anonymous
Здесь душевно что-ли
Snusmumriken
Всё правильно, тут есть снус, который бьёт всех злых пока те не станут добрыми ))
Anonymous
Там шаг влево шаг вправо и варн
Snusmumriken
В англо-международном чате по lua было примерно то же самое, пока на днях, местного главадмина не затыкали палками за самоуправство и узколобие (кикнул крутого чела за обсуждение луажыта, потому что "луажыт — не луа", и за косвенное обвинение в узкомыслии).
Anonymous
Ты затыкал?😂
Snusmumriken
Не без этого
Anonymous
Хех
 Лепикоршев
Лепикоршев
 Snusmumriken
Snusmumriken
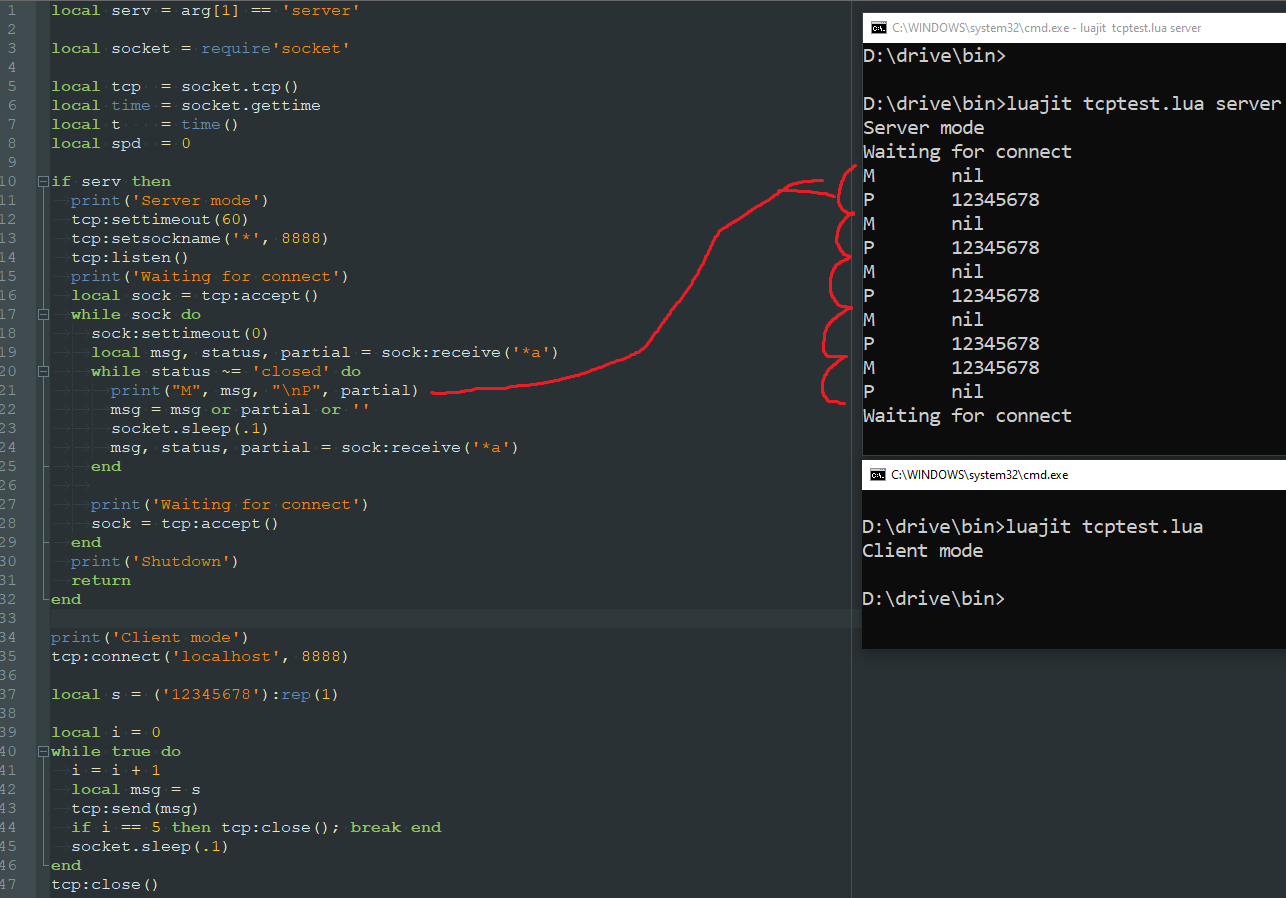
Получается, будет принят поток по кусочкам, а последний кусочек потока будет в data.
Напоминаю, что такая штука как TCP ориентирована не на сообщения, а на потоки. И сами сообщеньки благополучно склеиваются в одно бесконечное (пока соединение не порвут) сообщение. Тут идёт разделение только потому, что отсутствуют блокировки (чтение прерывается на таймауте) и мы смотрим на partial.
Snusmumriken
Вот в UDP — вполне себе сообщения, с началом, телом и концом.
Лепикоршев
Вот в UDP — вполне себе сообщения, с началом, телом и концом.
udp не везде подойдёт - хотя бы просто потому, что не все умеют его слать))
Snusmumriken
Если посмотреть на формат HTTP — там можно заметить такие фигулины как:
1. Разделение заголовков и тела пустой строкой. Это сделано за тем, что бы если послали длинное тело — можно было бы определить его начало.
2. Наличие в заголовках "длины тела сообщения". Это сделано для того, чтобы можно было понять, когда тело вообще закончилось, и начался следующий запрос (запросы можно объединять тупым склеиванием, но с приёмом придётся заморочиться)
Поэтому самый короткий формат сообщений на TCP —
[несколько фиксированных символов длины сообщения][тело]
Лепикоршев
"1. Разделение заголовков и тела пустой строкой. Это сделано за тем, что бы если послали длинное тело — можно было бы определить его начало."
Я бы поспорил. Что один пробел, что два - разницы для парсера не будет при прочих равных.
Это хорошо только как спецсимвол - в заголовках два переноса строки не встретятся по определению, а в тексте пользовательского запроса - могут. Значит, каждый блок пользовательского запроса просто логичнее начинать с комбинации, которая никогда не встретится в заголовках =)
Лепикоршев
"Поэтому самый короткий формат сообщений на TCP —
[несколько фиксированных символов длины сообщения][тело]" - это в идеальном мире.
В реальном клали разрабы на длину вначале строки - парси как хочешь, хоть по кофейной гуще.
Лепикоршев
Мне просто интересно сделать схему приёма-отправки, которая бы позволила выбрать протокол как опцию - хочешь, tcp, хочешь - udp.
И при этому если приём tcp задать в режиме *l, то отличий от udp для пользователя не будет.
Лепикоршев
Аналогично с отправкой - хочешь, по udp, хочешь, по tcp.
Понятно, что будут вещи, которые в принципе не будут одинаковыми для протоколов - то, что в tcp будет бесконечным бинарным потоком, по udp придётся так или иначе делать большим набором датаграмм. Но это граничные условия, где один из двух неприменим, и на нём нужно изворачиваться.
Лепикоршев
Получается, будет принят поток по кусочкам, а последний кусочек потока будет в data.
Напоминаю, что такая штука как TCP ориентирована не на сообщения, а на потоки. И сами сообщеньки благополучно склеиваются в одно бесконечное (пока соединение не порвут) сообщение. Тут идёт разделение только потому, что отсутствуют блокировки (чтение прерывается на таймауте) и мы смотрим на partial.
Я просто за что зацепился - если мы на каждом шаге приёма кусочка по tcp будем его считать равным сообщению (и пересылать дальше), не получится ли, что мы заспамим получателя кучей повторяющихся "кусочков"? "1", потом "12", и "123" и т.д. до полной строки "12345678"?
Логичнее ведь тогда сразу создать буфер фиксированного размера - и заполнять его или до предела или до конца входящей строки. И пересылать дальше такими "пачками".
На конечном приёмнике если печать получаемого потока включить, "кусочки"-повторы не приходят?
Лепикоршев
Я, как будет время, попробую тест провести на многих подключениях - если подтвердится, сформулирую, что не так на мой взгляд.
Пока это только подозрения)
Snusmumriken
Нет, не получится "12 123 12345".
Snusmumriken
Можно заметить в примере, что мы N раз отправляем 12345678, и количество отправок равно количеству кусочков.
Snusmumriken
receive очищает буфер partial'а при каждом вызове.
Snusmumriken
"1. Разделение заголовков и тела пустой строкой. Это сделано за тем, что бы если послали длинное тело — можно было бы определить его начало."
Я бы поспорил. Что один пробел, что два - разницы для парсера не будет при прочих равных.
Это хорошо только как спецсимвол - в заголовках два переноса строки не встретятся по определению, а в тексте пользовательского запроса - могут. Значит, каждый блок пользовательского запроса просто логичнее начинать с комбинации, которая никогда не встретится в заголовках =)
Пустая строка — это и есть спецсимвол. И нужен для разделения. Разницы никакой, но оно служит именно спецсимволом разделения и ничем больше. Я про это и написал.
"самый короткий формат" — он самый короткий потому, что в принципе позволяет надёжно разделять сообщения. В противном случае, мы, кто бы мог подумать, не можем разделять сообщения, потому что их нет. Приходить будет всё что нам прислали в склеенном виде, и нам или регулярками вытаскивать волшебные сигнатуры конца сообщения (что грубо и стрёмно, и может присутстовать в теле, что ломает систему), или кодировать и разделять чем-то типа \n.
TCP — это про потоки байтов, там всё склеивается.
Лепикоршев
receive очищает буфер partial'а при каждом вызове.
Тогда почему каждый раз из partial высылается вся строка?
Лепикоршев
Пустая строка — это и есть спецсимвол. И нужен для разделения. Разницы никакой, но оно служит именно спецсимволом разделения и ничем больше. Я про это и написал.
"самый короткий формат" — он самый короткий потому, что в принципе позволяет надёжно разделять сообщения. В противном случае, мы, кто бы мог подумать, не можем разделять сообщения, потому что их нет. Приходить будет всё что нам прислали в склеенном виде, и нам или регулярками вытаскивать волшебные сигнатуры конца сообщения (что грубо и стрёмно, и может присутстовать в теле, что ломает систему), или кодировать и разделять чем-то типа \n.
TCP — это про потоки байтов, там всё склеивается.
Я к тому, что вместо пустой строки можно использовать любой другой спец.символ, и смысл не изменится. Главное, чтобы на входе ждали тот же спец.разделитель, что и выставят на отправке.
Лепикоршев
Пустая строка — это и есть спецсимвол. И нужен для разделения. Разницы никакой, но оно служит именно спецсимволом разделения и ничем больше. Я про это и написал.
"самый короткий формат" — он самый короткий потому, что в принципе позволяет надёжно разделять сообщения. В противном случае, мы, кто бы мог подумать, не можем разделять сообщения, потому что их нет. Приходить будет всё что нам прислали в склеенном виде, и нам или регулярками вытаскивать волшебные сигнатуры конца сообщения (что грубо и стрёмно, и может присутстовать в теле, что ломает систему), или кодировать и разделять чем-то типа \n.
TCP — это про потоки байтов, там всё склеивается.
Я и говорю, в идеальном мире.
Потому что сплошь и рядом сообщение пихают в поток байт и без разделителей, и без длины.
И нужно самому догадаться, по каким признакам верно будет разрезать склейку.
Snusmumriken
Тогда почему каждый раз из partial высылается вся строка?
Только потому что socket.sleep. В данных условиях, это слип на пол года.
Snusmumriken
За секунду луасокет вполне успешно пересылает и принимает 105МБ, я уже писал тестилку на локалхосте ))
Лепикоршев
Только потому что socket.sleep. В данных условиях, это слип на пол года.
Не уловил. Как связано с ожиданием? Типа, за время слипа, успела прийти вся строка? А в partial она только потому, что соединение не закрыто?
Snusmumriken
Да.
Лепикоршев
Аа, ок, теперь понял.
Лепикоршев
За секунду луасокет вполне успешно пересылает и принимает 105МБ, я уже писал тестилку на локалхосте ))
А ты только socket тестировал, другие либы никакие не проверял для передачи по сети?
Snusmumriken
Не особо. Ещё свои ffi-биндинги к winsock, но они.. Специфичные.
Snusmumriken
Я и говорю, в идеальном мире.
Потому что сплошь и рядом сообщение пихают в поток байт и без разделителей, и без длины.
И нужно самому догадаться, по каким признакам верно будет разрезать склейку.
Кстати, где ты видел "сплошь и рядом поток байт без разделителей/длины"?
Snusmumriken
Назови какой-нибудь пользовательский протокол.
Snusmumriken
Длины может не быть только там, где, собственно.. Потоковый протокол. Например, интернет-радио. Там не будет длины, и условный ogg-файл будет передаваться бесконечно.
Snusmumriken
А в любом сообщение-ориентированном протоколе будут разделения, инфа 100%.
Лепикоршев
Я тут просто интересный грабель выкопал в lua sys. Если создать сокет, не важно даже, tcp или udp, то длина принимаемого сообщения не может превысить 4096 байт.
Это должно быть задано какой-нибудь опцией, но... Может быть и захардкоженой багой.
Лепикоршев
Кстати, где ты видел "сплошь и рядом поток байт без разделителей/длины"?
Логи аудита системы bluecoat, например
Snusmumriken
Офигенно странно. Мб оно предназначено тупо для непрерывной записи в файл, и там разделителем отдельных логирующих сообщений работает \n.
Лепикоршев
Назови какой-нибудь пользовательский протокол.
Ты про rfc 7-го уровня? Потому что я про проприетарные устройства, которые по сети общаются, а как, вендор не указывает.
Лепикоршев
А в любом сообщение-ориентированном протоколе будут разделения, инфа 100%.
Только в том, что по rfc писали, хотя бы с формальной совместимостью.
А это далеко не всегда так.
Snusmumriken
Потому что непрерывные неразделённые логи — это немножко мусор. Там должна быть как минимум метка времени, которая может работать началом сообщения.
Лепикоршев
Офигенно странно. Мб оно предназначено тупо для непрерывной записи в файл, и там разделителем отдельных логирующих сообщений работает \n.
\n при этом прекрасно встречает я в теле запроса
Лепикоршев
Потому что непрерывные неразделённые логи — это немножко мусор. Там должна быть как минимум метка времени, которая может работать началом сообщения.
И опять же, запрос содержит вложенные метки времени того же формата. Если отделать по ним, один запрос будет добиться на 4-5 штук без целостного смысла
Лепикоршев
Поэтому мысль, что все форматы сообщений специфицированы,
Лепикоршев
... А люди, их писавшие - разумны, слегка оптимистично))
Snusmumriken
Так, тогда ещё один вопрос: этот лог предназначен для чтения и парсинга машиной? Или только человеком?
Snusmumriken