 Vladimir
Vladimir


Мне вот руками тоже не хочется это дело разворачивать, но при этом "короьочного" функционала нигде не хватает
 Logan
Logan
это именно БАГ. У меня такой любимый на убунте есть с weave. если на хосте есть два интерфейса, то адреса нод должны быть строго публичными. Еесли указать приватные - weave будет падать. При этом трафик пойдет строго по приватному интерфейсу
Logan
вот такой вот подарок
Vladimir
Я поэтому и выбрал kargo как что то с знакомой основой (Ansible), активным сообществом, развивающееся и отчасти unopionated
Logan
вот я и пытаюсь постичь карго
Logan
с документацией-то катастрофа, ни квикстарта, ничего
Logan
про то, что надо поменять гуиды, хотя в документации написано, что делать этого нельзя
Logan
это явный баг, кто-то где-то в коде что-то посеял
Vladimir
А, ты про Azure Container Engine?
Logan
ага
Vladimir
Ага согласен
Vladimir
В чём ты разворачиваешь?
Vladimir
В AWS?
Logan
bare-metal, у нас свои сервера
Vladimir
А kargo-cli умеет bare metal?
Vladimir
Для обычного kargo, который на ansible, все конфигурации в какой то степени как bare metal
Logan
написно что умеет. В результате вся возня с карго для меня вылилась в генерацию конфигов. Как только я пойму, как сгенерить именно то, что мне нужно - решу 90% поставленой задачи. Осталась мелочь
 Denis
Denis
А вот как реализовать Public-Key-Pins средствами Ingress?
Ivan
Hello! Сорри, давно тут не проявлял активность, допиливал вот эту штуку https://github.com/Mirantis/kubeadm-dind-cluster Если у кого есть желание попробовать, то теперь можно запустить тестовый многонодовый k8s кластер, например, вот так:
$ wget https://cdn.rawgit.com/Mirantis/kubeadm-dind-cluster/master/fixed/dind-cluster-v1.5.sh
$ chmod +x dind-cluster-v1.5.sh
$ ./dind-cluster-v1.5.sh up
Нужен свежий докер (1.12+), проверялось на Mac OS X, Ubuntu 16.04, Fedora 25. Может работать с удалённым докером. При необходимости может собирать k8s из исходников, но может работать и без этого. Крайне быстро работает перезапуск кластера. Пока что не работает со storage driver'ом btrfs в докере (баг в cadvisor -> kubelet, проблема с зачисткой volumes).
Ivan
неплохо работает в Travis CI
Ivan
взлетает довольно легко на Маке с 8 Gb RAM
Ivan
за фидбэк буду признателен :)
 Knyage
Knyage
а что не так?
Видимо руки не из того места :) Только осваиваю кубер, медленно продвигается освоение.
Anonymous
У всех на определенном этапе бывает :)
Knyage
Без этого, конечно, никуда :)
Anton
ой ничего себе, Михаил, мир круглый
Anton
на свадьбе твоей сестры виделись))
Knyage
Мир и правда тесен =)
 Alex
Alex
У Миши за последние полчаса аж два подобных сюрприза) Мир - Шар. Sorry за оффтоп)
Sn00part
тут много кто кого знает. мне написал чувак с которым 10 лет назад работали
 Max
Max
Коллеги а кто-то знает аналогичный чатик по GCP? )
 Artem
Artem
ага, тоже интересно было бы, а то тут такое ощущение, что у всех кубер только на bare metal развернут)
Artem
а там есть некоторые свои нюансы
Max
GCP сам по себе, ссуко, странен - там и без k8s вопросов хватает
Max
то-ли дело AWS/OpenStack
 Zon
Logan
Ivan
Zon
Logan
Ivan
не совсем
Ivan
я правильно понимаю, что по функционалу это некоторый гибрид minicube и kargo?
это скорее что-то среднее между minikube и local-up-cluster, но только многонодовое
Ivan
minikube на данный момент стабильнее, но даёт только одну ноду и использует свою виртуалку
Anonymous
1.6.0 уже почти вот-вот https://github.com/kubernetes/kubernetes/releases/tag/v1.6.0-beta.4
Knyage
Поскорее бы:)
Vladimir
Я вчера beta3 взял, но AzureDisk на нём все равно медленно форматируется/подключается, хотя вроде должны были исправить
 M
M
кто-то поставил nginx ingress 0.9.0-beta.3?
 Kirill
Kirill
Поставил
Kirill
Работает
 Dorian
Dorian
Кто-нить озадачивался скрещиванием ODL с Kubernetes?
Dorian
Навеяно неплохой презентацией
https://www.slideshare.net/premsankar/kubernetes-integration-with-odl
Dorian
Правда я бы выпилил оттуда OS
Sn00part
можно вкратце, чем лучше калико?
Sn00part
если только сеть брать
Sn00part
или это вообще не про это?
Dorian
если только сеть брать
Не, калико круто! Только речь про то, чтобы отказаться от OS
Чтобы пускать контейнеры на BM
 🦠
🦠
А как со скоростью на двойной виртуализации?
Dorian
Где двойная?
🦠
На вводе-выводе
Dorian
Вот тут ODL нужен
https://kubernetes.io/docs/admin/ovs-networking/
M
all, как удалить podы в unknown status? образовались после пропадания одного из воркеров сильно надолго
M
кубер успел переподнять поды до его появления
M
помог ребут ноды на которой были unknown статусы
M
подскажите, у кого бареметалл и натроен мультимастер, у вас корректно происходит ребут одной ноды? у меня через раз при ребуте одной ноды кубер показывает что not ready две ноды, это как то можно разрулить? балансир аписерверов хапрокси
 Dmitry
Anonymous
Dmitry
Anonymous
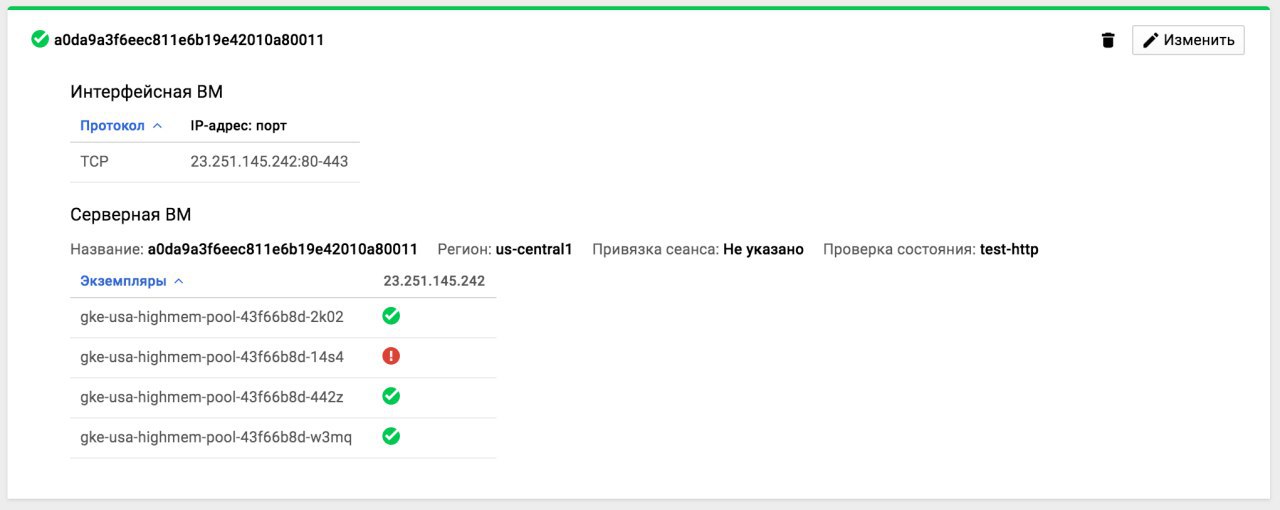
короче какая-то шняга с кластером на гугле: запросы через балансировщик стандартный идут через раз (одна из нод не отвечает)
самое интересное что при удалении ноды зараза эта переходит на другую ноду %)
что посоветуете сделать чтоб с минимальным даунтаймом хрень отдебажить и/или поправить?
Anonymous
это GKE?
Anonymous
или сам делал на GCE?
Anonymous
GKE
Anonymous
хочу попробовать текущие ноды в дрейн, создать пул с новыми, обновить кластер и грохнуть старые
Anonymous
хз поможет или нет, плюс опять же даунтайм что плохо
Anonymous
не, не помогло - че за хрень
Anonymous
 Anonymous
Anonymous
если эту ноду кильнуть то другая красной становится
Anonymous
кто-нибудь сталкивался?