FROM node:18-slim
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
RUN apt-get update && apt-get install gnupg wget -y && \
wget --quiet --output-document=- https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor > /etc/apt/trusted.gpg.d/google-archive.gpg && \
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' && \
apt-get update && \
apt-get install google-chrome-stable -y --no-install-recommends && \
rm -rf /var/lib/apt/lists/*
ENV TZ="Europe/Moscow"
WORKDIR /project
COPY package*.json .
RUN npm install
COPY . .
CMD ["npm", "start"]
Спасибо
 🦋noteee
🦋noteee

 🦋noteee
🦋noteee
FROM node:18-slim
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
RUN apt-get update && apt-get install gnupg wget -y && \
wget --quiet --output-document=- https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor > /etc/apt/trusted.gpg.d/google-archive.gpg && \
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' && \
apt-get update && \
apt-get install google-chrome-stable -y --no-install-recommends && \
rm -rf /var/lib/apt/lists/*
ENV TZ="Europe/Moscow"
WORKDIR /project
COPY package*.json .
RUN npm install
COPY . .
CMD ["npm", "start"]
А можно ведь как то сделать билд докер контейнера отдельно? Допустим. Я что то поменяю в своём проекте на ноде, тогда билд начнется заново. А если билдить проект ноды от паппитера отдельно, тогда это же ускорит процесс, потому что при ре-билде паппитер снова билдить не нужно
🦋noteee
Я что то такое примерно видел. Уже не помню даже что и как
 Roman
Roman
А можно ведь как то сделать билд докер контейнера отдельно? Допустим. Я что то поменяю в своём проекте на ноде, тогда билд начнется заново. А если билдить проект ноды от паппитера отдельно, тогда это же ускорит процесс, потому что при ре-билде паппитер снова билдить не нужно
Так докер и не должен в таком случае делать полный ребилд. Если образ сборки не был удален, то слои с дистрибутивом и нодой остаются на месте, ребилдится только уровень, котором были изменения
 Null
Null
А можно ведь как то сделать билд докер контейнера отдельно? Допустим. Я что то поменяю в своём проекте на ноде, тогда билд начнется заново. А если билдить проект ноды от паппитера отдельно, тогда это же ускорит процесс, потому что при ре-билде паппитер снова билдить не нужно
Как и сказал Роман, слои как раз помогут не пересобирать каждый раз полностью образ.
Но если хочешь сбилдить разные образы, то можно и так:
FROM node:18-slim
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
RUN apt-get update && apt-get install gnupg wget -y && \
wget --quiet --output-document=- https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor > /etc/apt/trusted.gpg.d/google-archive.gpg && \
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' && \
apt-get update && \
apt-get install google-chrome-stable -y --no-install-recommends && \
rm -rf /var/lib/apt/lists/*
После сборки, к примеру так:
docker build -t pptr:1.0 .
Можно использовать собранный ранее образ:
FROM pptr:1.0
ENV TZ="Europe/Moscow"
WORKDIR /project
COPY package*.json .
RUN npm install
COPY . .
CMD ["npm", "start"]
 это клёво, разве нет?
это клёво, разве нет?
А можно ведь как то сделать билд докер контейнера отдельно? Допустим. Я что то поменяю в своём проекте на ноде, тогда билд начнется заново. А если билдить проект ноды от паппитера отдельно, тогда это же ускорит процесс, потому что при ре-билде паппитер снова билдить не нужно
 🦋noteee
🦋noteee
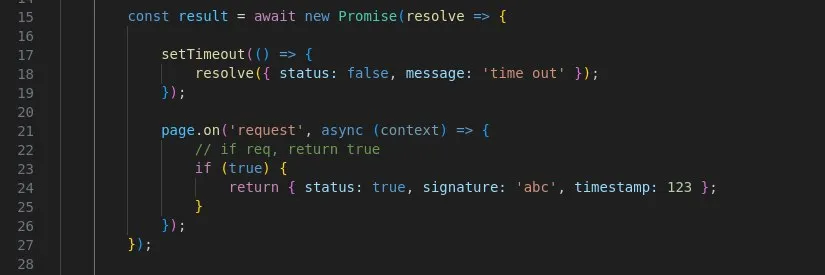 Null
Null
 Sergey
Sergey
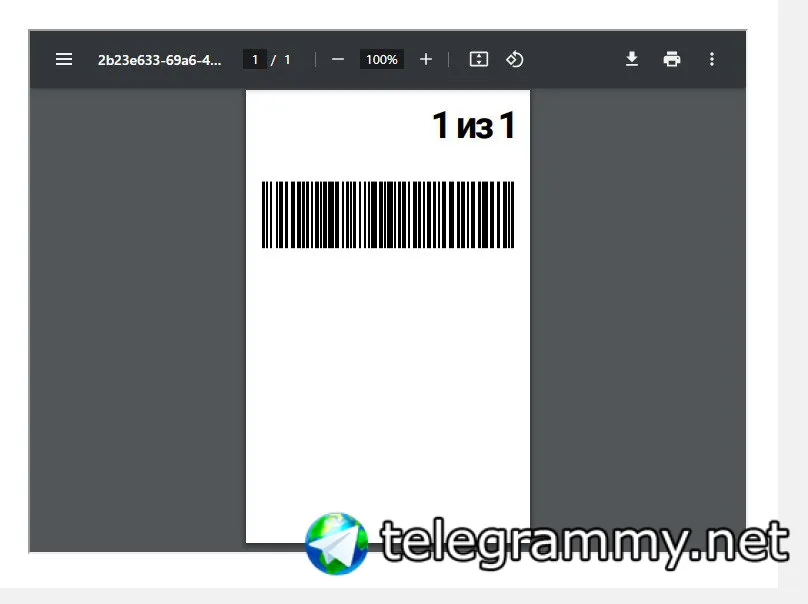 🦋noteee
Sergey
🦋noteee
Sergey
 🦋noteee
🦋noteee
Это отдельное окно с открытой пдфкой?
Скорее всего, на странице есть какой то селектор, при нажатии на который и будет открываться пдфка. Думаю с ним и нужно работать
Sergey
нет, это iframe
Sergey
кнопок нет а сама пдфка нарисована стандартным плагином
Sergey
на клиенте генерится
Sergey
вероятно react-pdf
 Andrey@inotoxic
Andrey@inotoxic
почитайте что такое blob ссылки
Sergey
почитайте что такое blob ссылки
я примерно представляю, но должна быть непосредственно сама ссылка я так понимаю?
Andrey@inotoxic
я примерно представляю, но должна быть непосредственно сама ссылка я так понимаю?
смотря как настроено
может быть и ссылка
а могут быть и сами данные - зашифрованные в base64
js обрабатывает blob - рендерится контент
Sergey
смотря как настроено
может быть и ссылка
а могут быть и сами данные - зашифрованные в base64
js обрабатывает blob - рендерится контент
я имел в виду что для того чтобы данные оттуда получить нужна сама ссылка вроде или гуид там не помню
Null
я примерно представляю, но должна быть непосредственно сама ссылка я так понимаю?
Попробуй это добавить и покажи вывод:
page.on("response", async (res) => {
if (res.url().match(/(blob:|\.pdf)/i)) {
console.log(res.url());
const buffer = await res.buffer();
console.log("size:", buffer.length);
}
});
Null
Только тебе нужно это добавить на нужный iframe.
UPD: Проверил, достаточно на страницу повесить, он увидит и внутри iframe.
Sergey
это подразумевает обращение по сети?
Sergey
его было бы видно в devtools?
Null
это подразумевает обращение по сети?
Не обязательно. Это блоб, который можно сгенерировать даже офлайн внутри страницы.
Sergey
Только тебе нужно это добавить на нужный iframe.
UPD: Проверил, достаточно на страницу повесить, он увидит и внутри iframe.
ну короче он перехватывает да, но там в буффере собственно содержимое iframe
Sergey
как на скрине с iframe который я выше прикладывал
Null
ну короче он перехватывает да, но там в буффере собственно содержимое iframe
Что-то не то перехватывается значит, в буфере должно быть тело PDF. А URL перехваченный совпадает с тем что видно в браузере?
Null
как на скрине с iframe который я выше прикладывал
Вот так попробуй:
page.on("requestfinished", async (req) => {
if (req.url().match(/(blob:|\.pdf)/i)) {
console.log(req.url());
const buffer = await req.response().buffer();
console.log("size:", buffer.length);
await page.evaluate((url) => {
const link = document.createElement('a');
link.href = url;
link.download = "result.pdf";
document.body.append(link);
link.click();
link.remove();
}, req.url());
}
});
const client = await page.target().createCDPSession();
await client.send('Browser.setDownloadBehavior', {
behavior: "allow",
downloadPath: "./downloads",
eventsEnabled: true,
});
client.on('Browser.downloadWillBegin', (res) =>
console.log("[Browser.downloadWillBegin]", res)
);
client.on('Browser.downloadProgress', (res) =>
console.log("[Browser.downloadProgress]", res)
);
await page.goto("<URL>");
Vyacheslav
Никто не знает как anti aliasing отключить?
Vyacheslav
--disable-lcd-text
Vyacheslav
 User
User
При запуске
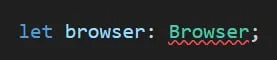
const browser = await puppeteer.launch({
args:[
'--no-sandbox',
`--proxy-server=${proxy}`,
],
});
если не доступен прокси, то вылетает ошибка net::ERR_SOCKS_CONNECTION_FAILED at https://site.com, но сам браузер запущен и его никак нельзя закрыть, т.к. константа browser не существует. Как закрыть браузер или отловить ошибку? try catch не помогает.
это клёво, разве нет?
User
Скинь код с использованием try catch
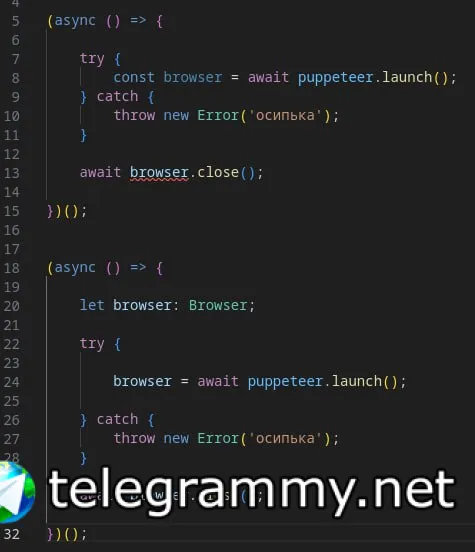
try {
const browser = await puppeteer.launch({
args:[
'--no-sandbox',
`--proxy-server=${proxy}`,
],
});
const page = await browser.newPage()
} catch (e) {
if (typeof browser !== 'undefined') {
await browser.close()
} else {
console.log('No const browser')
}
}
это клёво, разве нет?
try {
const browser = await puppeteer.launch({
args:[
'--no-sandbox',
`--proxy-server=${proxy}`,
],
});
const page = await browser.newPage()
} catch (e) {
if (typeof browser !== 'undefined') {
await browser.close()
} else {
console.log('No const browser')
}
}
 User
User
 это клёво, разве нет?
это клёво, разве нет?
это клёво, разве нет?
это клёво, разве нет?
Ошибку связанную с прокси выдает только при переходе на страницу, так что можно использовать
const browser = await puppeteer.launch();
let page = await browser.newPage();
try {
await page.goto()
} catch {}
User
Ошибку связанную с прокси выдает только при переходе на страницу, так что можно использовать
const browser = await puppeteer.launch();
let page = await browser.newPage();
try {
await page.goto()
} catch {}
Спасибо, действительно, надо было отдельно отлавливать ошибку открытия страницы.
 Aleksandr
Aleksandr
подскажите, на странице несколько элементов с id типа selec1 selec2 selec3, причем номера всегда меняются, как мне получить их по маске кликнуть по первому из них
Null
подскажите, на странице несколько элементов с id типа selec1 selec2 selec3, причем номера всегда меняются, как мне получить их по маске кликнуть по первому из них
await page.waitForXPath("//div[starts-with(@id, 'selec']")
Aleksandr
Спасибо!
Верет
Всем привет, может конечно глупый вопрос, пишу код на Python pyppeteer
как я могу с помощью него проскролить страницу вниз до упора
это клёво, разве нет?
Всем привет, может конечно глупый вопрос, пишу код на Python pyppeteer
как я могу с помощью него проскролить страницу вниз до упора
Привет! Чтобы проскролить страницу вниз до упора с помощью Pyppeteer, можно использовать метод page.evaluate() для выполнения JavaScript-кода внутри страницы.
Вот пример кода, который поможет тебе проскролить страницу вниз до упора:
import asyncio
from pyppeteer import launch
async def scroll_to_bottom():
# Запускаем браузер
browser = await launch()
page = await browser.newPage()
# Переходим на нужную страницу
await page.goto('https://example.com')
# Получаем высоту страницы
page_height = await page.evaluate('document.body.scrollHeight')
# Прокручиваем страницу вниз до упора
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
# Проверяем, достигнут ли конец страницы
while True:
# Ждем некоторое время, чтобы страница успела прокрутиться
await asyncio.sleep(1)
# Получаем новую высоту страницы
new_page_height = await page.evaluate('document.body.scrollHeight')
# Если новая высота страницы не изменилась, значит мы достигли конца страницы
if new_page_height == page_height:
break
# Продолжаем прокручивать страницу вниз
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
# Обновляем высоту страницы
page_height = new_page_height
# Закрываем браузер
await browser.close()
# Запускаем прокрутку страницы
asyncio.get_event_loop().run_until_complete(scroll_to_bottom())
В этом примере мы используем page.evaluate() для выполнения JavaScript-кода window.scrollTo(0, document.body.scrollHeight), который прокручивает страницу вниз до конца. Затем мы проверяем, достигнут ли конец страницы, и, если нет, продолжаем прокручивать.
Учти, что для использования Pyppeteer должен быть установлен браузер Chrome или Chromium.
 👨💻
👨💻
Мой отвал жопы прозошел еще на 2 часу этого дерьма.
Добавляю задание в очередь. После добавление тут же запускается страница в браузере. Однако она закрывается сама собой.
БЕЗ какой либо причины. Создавал отдельный файл чисто с кластером по открытию любого сайта. Все тоже самое происходит.
как это исправить не смог найти за целый день
👨💻
такая же проблема абсолютно на чистом проекте
👨💻
Самый прикол в том, что проблема началась только сегодня. Ранее такой картины не наблюдалось. Решить вообще никак не получается
Null
Мой отвал жопы прозошел еще на 2 часу этого дерьма.
Добавляю задание в очередь. После добавление тут же запускается страница в браузере. Однако она закрывается сама собой.
БЕЗ какой либо причины. Создавал отдельный файл чисто с кластером по открытию любого сайта. Все тоже самое происходит.
как это исправить не смог найти за целый день
Насколько я вижу это дефолтное поведение. В чём проблема?
👨💻
Насколько я вижу это дефолтное поведение. В чём проблема?
Странно. Так действует, как я понимаю именно cluster. У обычного пупетира такого нет.
Причем раньше кластер у меня не закрывал окна в браузере.
Проблема в том, что скрипт начинает выполнять различные действия, но страница попросту закрывается. То есть идёт выполнение действий, но страница закрывается. Из-за закрытой страницы выполнение скрипта падает в ошибку, потому что пишет, что не могу получить данные.
👨💻
Страница закрывается как при выполнении каких-то действий, так и без них
👨💻
Может есть у кого идеи причины такого поведение ?
То есть даже если пупетир жмёт на кнопки, переключает что-то на сайте, то открытая страница закрывается вообще без причин. И дальше при любом действии вылезает ошибка естественно, потому что окно закрылось
Anton
Никто не сталкивался с ошибкой TimeoutError: Timed out after 30000 ms while waiting for the WS endpoint URL to appear in stdout! при запуске браузера в докере? В один прекрасный момент перестал подключаться по WS с этой ошибкой. При этом на других машинах тот же код нормально работает.
👨💻
Task error occurred: Error: Timeout hit: 30000
at G:\JD\parser\node_modules\puppeteer-cluster\dist\util.js:69:23
at Generator.next (<anonymous>)
at fulfilled (G:\JD\parser\node_modules\puppeteer-cluster\dist\util.js:5:58)
наконец-то смог ошибку получить в консоли. с помощью такой вот записи. ВОобще ничего в консоль не выводит ошибку эту
cluster.on('taskerror', (err, data) => {
console.error('Task error occurred:', err);
// Handle the error here
});
 Hypno
Hypno
Приветствую. Имеется здесь пентестеры?
👨💻
та ошибку то показал, а исправить ее нельзя. Походу что-то сломали в библиотеке. Браузер закрывается при любых обстоятельствах.
При выполнение любого задания, при его отстутствии.
а, последнее обновленеи 2 года назад. Понимаю. Короче без шансов.
ошибка просто начала вылезать и ничего с ней нельзя сделать
👨💻
не думаю, что это нормальное поведение, с учетом того, что я приказал ему спать. Скрипт сам по себе не завершается и также ждет своего времени.
А когда время закончится, то вылезет ошибка
Null
Task error occurred: Error: Timeout hit: 30000
at G:\JD\parser\node_modules\puppeteer-cluster\dist\util.js:69:23
at Generator.next (<anonymous>)
at fulfilled (G:\JD\parser\node_modules\puppeteer-cluster\dist\util.js:5:58)
наконец-то смог ошибку получить в консоли. с помощью такой вот записи. ВОобще ничего в консоль не выводит ошибку эту
cluster.on('taskerror', (err, data) => {
console.error('Task error occurred:', err);
// Handle the error here
});
Ну правильно. Потому что асинхронная ошибка была. Для этого метод и нужен. Или нужно было самому оборачивать весь колбэк в try/catch и проблемы не было бы. Ещё можешь добавить в конфиг при запуске параметр monitor: true, и тогда будешь видеть сколько ошибок, процент выполненных задач.
Null
Странно. Так действует, как я понимаю именно cluster. У обычного пупетира такого нет.
Причем раньше кластер у меня не закрывал окна в браузере.
Проблема в том, что скрипт начинает выполнять различные действия, но страница попросту закрывается. То есть идёт выполнение действий, но страница закрывается. Из-за закрытой страницы выполнение скрипта падает в ошибку, потому что пишет, что не могу получить данные.
> Так действует, как я понимаю именно cluster.
Да, в этом его задача как раз. Отработать и закрыться, потому что в очереди могут стоять следующие задачи.
> У обычного пупетира такого нет.
Да, возможно тебе и нужен он, не понятно к чему тебе кластер, если ты хочешь пользоваться браузером после окончания задачи.
Null
не думаю, что это нормальное поведение, с учетом того, что я приказал ему спать. Скрипт сам по себе не завершается и также ждет своего времени.
А когда время закончится, то вылезет ошибка
А таймаут это кластер выдаёт? Если да, то измени его, наверняка должна быть опция.
👨💻
А таймаут это кластер выдаёт? Если да, то измени его, наверняка должна быть опция.
изменял. Ставил 999999999. Все равно окна браузера закрываются спустя 30 секунд.
Прикол в том, что такого еще вчера не было. А сегодня просто без какой-либо причины появилось. Я не менял скрипт от слова совсем
👨💻
> Так действует, как я понимаю именно cluster.
Да, в этом его задача как раз. Отработать и закрыться, потому что в очереди могут стоять следующие задачи.
> У обычного пупетира такого нет.
Да, возможно тебе и нужен он, не понятно к чему тебе кластер, если ты хочешь пользоваться браузером после окончания задачи.
мне нужно открытые окна, чтобы обращаться и получать куки от браузера и затем уже их использовать
Null
мне нужно открытые окна, чтобы обращаться и получать куки от браузера и затем уже их использовать
Я это к тому, что если у тебя иной алгоритм работы, то может и не нужен кластер. Ты можешь сам так же запускать сколько тебе нужно браузеров и с любым количеством вкладок.
👨💻
А таймаут это кластер выдаёт? Если да, то измени его, наверняка должна быть опция.
даже при выполнение скрипта когда идут действия, у меня все равно закрывается браузер. То есть у меня в таске еще строчек 400-500 есть, котоыре просто не могут выполнится, потому что браузера нет.
А почему его нет - вопрос хороший)
👨💻
Я это к тому, что если у тебя иной алгоритм работы, то может и не нужен кластер. Ты можешь сам так же запускать сколько тебе нужно браузеров и с любым количеством вкладок.
кластер для многопоточности нужен. Там хорошо воркеры сделаны
Null
изменял. Ставил 999999999. Все равно окна браузера закрываются спустя 30 секунд.
Прикол в том, что такого еще вчера не было. А сегодня просто без какой-либо причины появилось. Я не менял скрипт от слова совсем
Ну это странно, ведь либа давно не обновлялась, поэтому они поломать ничего не могли. Либо какой-то странный баг, который проявляется в новой версии браузера, либо у тебя в коде что-то изменилось.
Null
даже при выполнение скрипта когда идут действия, у меня все равно закрывается браузер. То есть у меня в таске еще строчек 400-500 есть, котоыре просто не могут выполнится, потому что браузера нет.
А почему его нет - вопрос хороший)
Это понятно, раз оно падает по таймеру, вкладка закрывается. Тебе нужно искать почему таймаут срабатывает.
👨💻
в коде точно ничего не изменялось. Вчера утром все выполнялось, окно в браузере не закрывалось. Однако запустив скрипт днем, началась проблема с вылетом страницы в браузере
👨💻
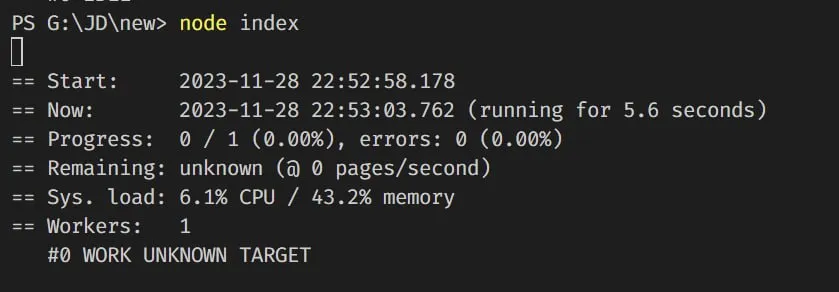 👨💻
👨💻
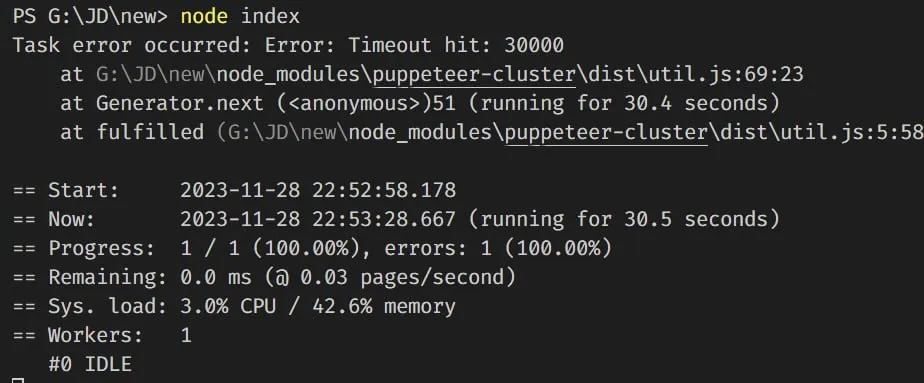 👨💻
👨💻
ща придется в код библиотеки лезть, смотреть и комментить походу строки
Null
ща придется в код библиотеки лезть, смотреть и комментить походу строки
Какая у тебя версия библиотеки?
Null
Я запустил пример как у тебя - через 30 секунд действительно закрылась вкладка, но когда добавил таймаут то вкладка висит уже 3 минуты.
👨💻
 👨💻
👨💻
ща нодужс переустановлю. Просто треш. Такое первый раз вообще
👨💻
все матные слова уже реоебрал. Переустноавил ноду, либу. Все равно такая же дичь