ну так у вас там throw стреляет
В чем ещё может быть проблема?
 Dima
Dima


 Aleksey
Aleksey
Поставьте брейкопйнт на блоке catch и почитайте детали исключения e
Dima
Поставьте брейкопйнт на блоке catch и почитайте детали исключения e
Оно туда не доходит. Думает, что программа отрабатывает нормально
Aleksey
Оно туда не доходит. Думает, что программа отрабатывает нормально
А если через dotnet run в консольке запустить, что будет?
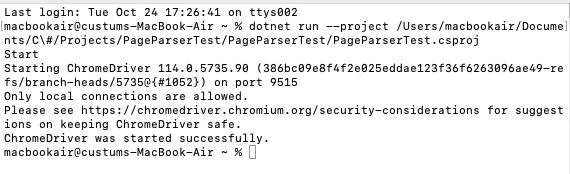 Aleksey
Aleksey
а покажите ка, как метод Main объявлен
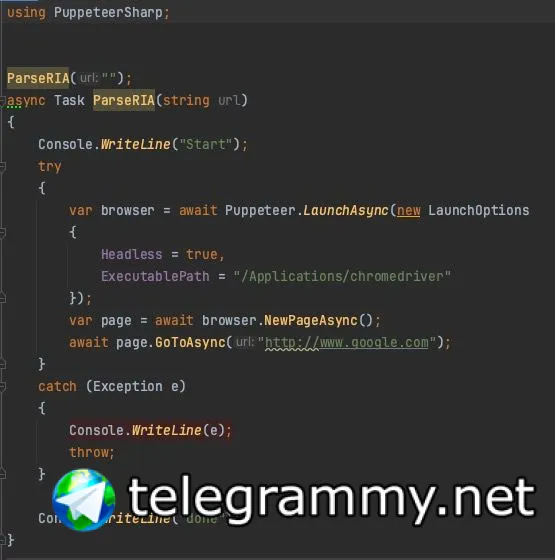
 это клёво, разве нет?
это клёво, разве нет?
 Aleksey
Aleksey
Aleksey
Aleksey
Использовать резидентские прокси, отключить признаки "тестирования" на браузере, использовать стелс плагин, эмулировать активность пользователя перед ключевым действием, использовать сервис для решения капчи, типа Рукапча.
Aleksey
А иногда достаточно просто посмотреть раздел нетворк в браузере, может оказаться, что капчу прикрутили криворукие или лентяи, и она не распространяется на http-вызовы,как следует, это можно проверить, подставляя в http-запросе в рекапча токен всякую туфту
это клёво, разве нет?
Использовать резидентские прокси, отключить признаки "тестирования" на браузере, использовать стелс плагин, эмулировать активность пользователя перед ключевым действием, использовать сервис для решения капчи, типа Рукапча.
 это клёво, разве нет?
это клёво, разве нет?
 Aleksey
это клёво, разве нет?
Aleksey
это клёво, разве нет?
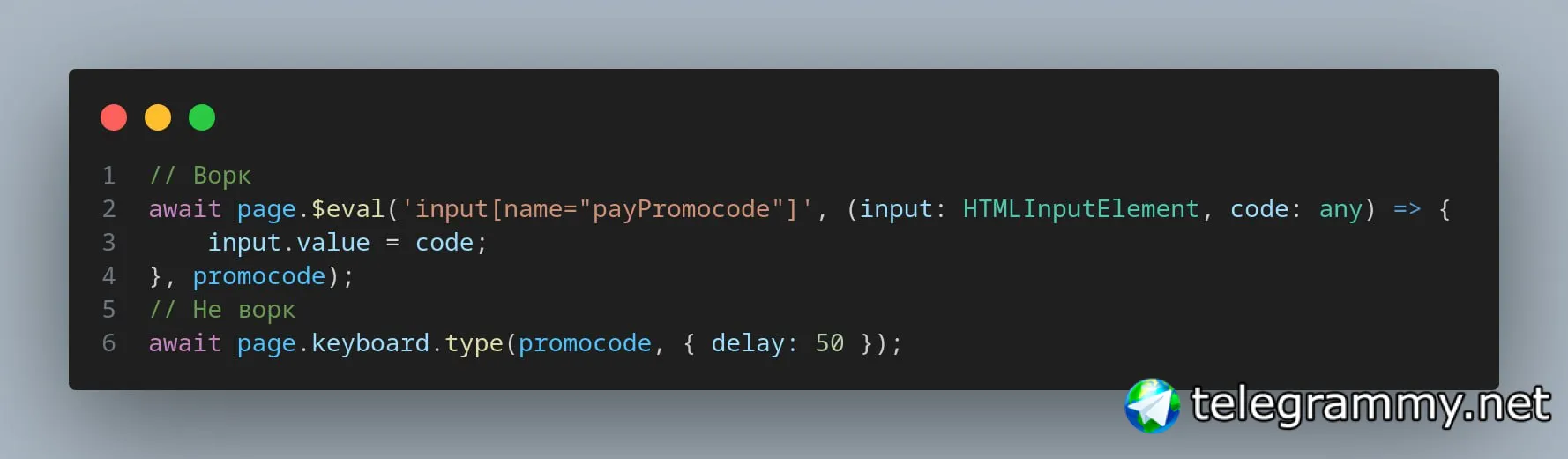
Не понял как сделать через $x, сделал через page.$(), но буквы он всё равно проглатывает
Aleksey
Не понял как сделать через $x, сделал через page.$(), но буквы он всё равно проглатывает
await (await page.$x(xpath)).type("жопа");
 это клёво, разве нет?
это клёво, разве нет?
Вроде пофиксил, сейчас проверю
UPD: не пофиксил
 Roman
это клёво, разве нет?
Roman
это клёво, разве нет?
 Aleksey
Aleksey
это клёво, разве нет?
Aleksey
Aleksey
это клёво, разве нет?
У метода.type() есть опции, одна из которых - это задержка ввода, чтоды больше походить на юзера, попробуйте ее заюзать
 Aleksey
Aleksey
Нз
Null
Это не везде работает, к сожалению, да.
Первый раз слышу чтобы не работал этот метод. Если есть какой-то пример, кидай, посмотрим.
По-идее там посылается самое обычно событие нажатия клавиши. Если пользователь может вручную это делать, значит и type() сможет. Возможно поле ввода ожидало какого-то события, типа focus/mouseenter/mousemove.
Null
это клёво, разве нет?
Если это публичная страница, можешь кинуть пример, я посмотрю как будет время.
Там авторизоваться необходимо через стим. Могу фулл код в личку кинуть и отметить проблемное место + показать проблему на видео
 Alhimik
Alhimik
 🦋noteee
это клёво, разве нет?
🦋noteee
это клёво, разве нет?
 это клёво, разве нет?
это клёво, разве нет?
 Null
это клёво, разве нет?
Null
это клёво, разве нет?
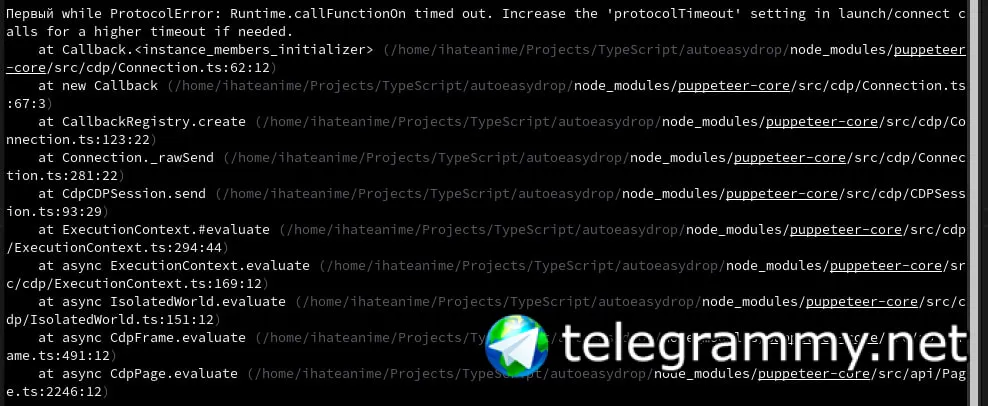
Этот код не должен вызывать такое поведение.
Проблема появилась только после его добавления
Null
Проблема появилась только после его добавления
Это на конкретном сайте происходит или со всеми?
это клёво, разве нет?
Ну тут как-то так..
это клёво, разве нет?
Насколько я понял сайт если не может прогрузить картинку то пытается сделать это повторно бесконечное кол-во раз, сейчас попробую добавить её в исключения
Null
Насколько я понял сайт если не может прогрузить картинку то пытается сделать это повторно бесконечное кол-во раз, сейчас попробую добавить её в исключения
Если такое происходит, лучше вместо блокировки, отдавать ему картинку-заглушку. Потому что при ошибках могут отправляться сообщения на сервера и поведение кода меняться.
это клёво, разве нет?
Насколько я понял сайт если не может прогрузить картинку то пытается сделать это повторно бесконечное кол-во раз, сейчас попробую добавить её в исключения
Сработало, теперь сайт не висит в бесконечной загрузке
это клёво, разве нет?
Если такое происходит, лучше вместо блокировки, отдавать ему картинку-заглушку. Потому что при ошибках могут отправляться сообщения на сервера и поведение кода меняться.
Там проблема с одним изображением из миллиона, пока что просто дал ему прогружаться. Проблем с другими изображениями вроде нет
Null
Если такое происходит, лучше вместо блокировки, отдавать ему картинку-заглушку. Потому что при ошибках могут отправляться сообщения на сервера и поведение кода меняться.
Если понадобится, создай картинку-заглушку, например PNG 1x1px. Потом закэшируй:
const files = {
png: fs.readFileSync("./assets/image.png"),
};
И внутри интерсептора замени req.abort() на req.respond():
req.respond({
body: files.png,
contentType: 'image/png',
});
это клёво, разве нет?
Хорошо, спасибо :3
 4unkur
4unkur
Привет ребят.
немного старая версия апифай и пуппетеер. у меня задача сделать кроулер и считать инфу из ажакс запроса на graphQL
пытаюсь навеситься на событие response
но если не дожидаться загрузки страницы, то коллбек никогда не выполняется:
4unkur
const crawler = new Apify.PuppeteerCrawler({
preNavigationHooks: [
async ({ page }): Promise<void> => {
page.on('response', async (response) => {
if (!response.request().url().includes(GRAPHQL_PATH)) return;
const data = await response.json();
console.log(data[0]?.data?.search?.advert?.id);
});
},
],
handlePageFunction: async ({ request, page }): Promise<void> => {
switch (request.label) {
case LABEL_LIST:
return listHandler(page);
case LABEL_VIEW:
// а) await page.waitForNavigation({ waitUntil: 'networkidle0' });
// б) await page.waitForResponse((response) => response.url().includes(GRAPHQL_PATH));
return viewHandler(page);
// return await vehicleHandler($, url, kvStore, dataset, locationURL, statisticService, session);
default:
break;
}
},
});
crawler.run();
4unkur
в handlePageFunction как видите я закоментил куски кода, которые я пробовал.
а) - если ждать networkidle то в принципе работает, но хаотично и браузер может долго висеть, генерит ошибки. в общем непонятно как работает.
б ) - вообще не работает. Кажется этот метод не для этого. Я думал не ждать загрузки всей стр, а всего лишь дождаться ответа от нужного мне ажакс запроса, но чот не работает
4unkur
есть идеи куда копать?
Aleksey
Сделайте 2 промиса
page.goto()
И
page.waitForResponse(нужный вам запрос)
А потом дождитесь результата waitForResponse
4unkur
Сделайте 2 промиса
page.goto()
И
page.waitForResponse(нужный вам запрос)
А потом дождитесь результата waitForResponse
да, это в инете много где упоминается. но чот я не понял как его применить в контексте crawler-а так как он сам редиректит и никаких goto не нужно делать
Aleksey
да, это в инете много где упоминается. но чот я не понял как его применить в контексте crawler-а так как он сам редиректит и никаких goto не нужно делать
Ничего он не редиректит. Он просто ждет указанного вами запроса на страничке и отваливается через таймаут, если не дождался
4unkur
Ничего он не редиректит. Он просто ждет указанного вами запроса на страничке и отваливается через таймаут, если не дождался
изначально скраппер был на cheerio. потом сайт обновили и теперь там cheerio никак не заскрапить, поэтому переписываю на puppeteer.
в listHanlder я просто дергаю нужные линки и добавляю в очередь:
await requestQueue.addRequest({
url: new URL(url).origin + ViewUrl,
userData,
});
в viewHandler - скрапинг данных
4unkur
Сделайте 2 промиса
page.goto()
И
page.waitForResponse(нужный вам запрос)
А потом дождитесь результата waitForResponse
все таки смог решить. Ваш ответ в целом был правильный.
Коротко говоря я удалил совсем preNavHooks и листенер и просто оставил waitForResponse
почему то я не думал что он возвращает httpResponse
в итоге в handlePageFunction:
const res = await page.waitForResponse((response) =>
response.url().includes(URL_PROPERTIES_DICTIONARY.GRAPHQL_PATH),
);
const data = await res.json();
и все работает ))
Спасибо!
 Mishka
Mishka
Привет всем! Кто то сталкивался с проблемой что браузер с headless true работает по другому нежели headless false. У меня лично просто не может подтянуть html корректно. Не знаю даже что делать с этим
Null
Привет всем! Кто то сталкивался с проблемой что браузер с headless true работает по другому нежели headless false. У меня лично просто не может подтянуть html корректно. Не знаю даже что делать с этим
Конечно сталкивались. Нужно как минимум менять user-agent, а лучше пользоваться stealth-плагином и всё равно это не даст гарантий. Нужно погружаться в то как сайты отличают автоматизацию от ручного использования браузера человеком.
Mishka
а там сайту пофигу вроде бы, там ни каптч ничего
Mishka
просто заход на страничку
Mishka
https://debank.com/stream/878412 вот условно страница и с нее данные получать надо, никуда нажимать и тд не требуется.
Null
https://debank.com/stream/878412 вот условно страница и с нее данные получать надо, никуда нажимать и тд не требуется.
Не вижу никаких проблем.
> не может подтянуть html корректно
Что именно не получается?
Mishka
 Mishka
Mishka
'#root > div > div.DesktopFrame_mainContainer__2V8Re > div.container_mainSubContainer__39U6P > div > div.DetailContainer_stream__2efLF > div.StickySide_stickySide__1e8C7.DetailContainer_sidebar__2Bm9-'
вот селектор если нужен
Mishka
Я заметил что там как будто на странице снала подгружается шаблон, а потом уже контент поста (#root > div > div.DesktopFrame_mainContainer__2V8Re > div.container_mainSubContainer__39U6P > div > div.DetailContainer_stream__2efLF)
Mishka
 Null
Mishka
Null
Mishka
А где можно посмотреть как сделать так чтобы не отличал? Если честно станно работает, иногда достаточно написать console log, и тогда начинает нормально работать, но не долго и в какой-то момент фриз ловит
Null
А где можно посмотреть как сделать так чтобы не отличал? Если честно станно работает, иногда достаточно написать console log, и тогда начинает нормально работать, но не долго и в какой-то момент фриз ловит
Я выше кинул ссылку на стелс-плагин, можно посмотреть там примеры.
4unkur
Mishka
Привет еще раз! Получилось побороть headless true, но возникла проблема в том что нужно этот проект закинуть на сервер, и не получается код запустить на линуксе и через докер. Использую мак на ARM
Mishka
Кто то занимался подобным?
это клёво, разве нет?
это клёво, разве нет?
options = {
headless: 'new',
executablePath: '/usr/bin/google-chrome',
args: ['--mute-audio', '--no-sandbox']
};
Mishka
спасибо, сейчас попробую)
🦋noteee
Mishka
заработало но посему то тг бота блочит сервак)
🦋noteee
Файл не открывается
Null
Мне скрин нужен
FROM node:18-slim
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
RUN apt-get update && apt-get install gnupg wget -y && \
wget --quiet --output-document=- https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor > /etc/apt/trusted.gpg.d/google-archive.gpg && \
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' && \
apt-get update && \
apt-get install google-chrome-stable -y --no-install-recommends && \
rm -rf /var/lib/apt/lists/*
ENV TZ="Europe/Moscow"
WORKDIR /project
COPY package*.json .
RUN npm install
COPY . .
CMD ["npm", "start"]