Заюзал подобное решение, годнота, даже проще чем замерять response. Только использовал CDP сессию.
Круто! Правда я не очень понял что такое CDP сессия)
 Александр
Александр

 Pavel
Pavel
Круто! Правда я не очень понял что такое CDP сессия)
Там где заканчивается пумпатер начинается Chrome Devtools Protocol
Александр
норм, мне пока хватает стандартного апи)
Serhii
Привет всем, ребята возникла проблема, когда делаем скриншоты с headless: true, скриншоты валидные все ок, с headless: false - empty, с чем это может быть связанно?
 Gambit501
Serhii
Gambit501
Serhii
йеп
Gambit501
const defaultViewport = {height: 1920,width: 1280};
const bodyHandle = await page.$('body');
const boundingBox = await bodyHandle.boundingBox();
const newViewport = {
width: Math.max(defaultViewport.width, Math.ceil(boundingBox.width)),
height: Math.max(defaultViewport.height, Math.ceil(boundingBox.height)),
};
await page.setViewport(Object.assign({}, defaultViewport, newViewport));
Gambit501
и после него уже делай скриншот
Serhii
await page.setViewport(size);
У нас есть размеры блока с картинкой которую нужно заскриншотить
Serhii
то что ты скинул, не решило проблему, все равно в режиме headless: false - empty
Serhii
Есть еще какие-то варианты?
Serhii
можно ли как-то посмотреть в нетворк pupeteer? Как реквест он делает?
Serhii
можно подробнее, какой перехватчик?
Serhii
ааа все я понял, спс
Serhii
@bin2hex а ты случайно не можешь предположить с чем может быть связанна проблема?
Serhii
да я повесил слушатели, спасибо
Serhii
секунда сейчас предоставлю немножко инфы
Serhii
Делаем скриншоты выделенной области, в которой рендерится обычный html с 1-й картинкой.
Процентов 95 картинок валидные скриншоты, а некоторые пустые, причем эти пустые картинки мы процессили отдельно и они в режиме headless: false - рендерятся и скриншоты валидные, а в режиме headless - они пустые.
Serhii
То что они не успевают отрендерится исклюбчено, я ставил тайм ауты в разном range, с headless: true, всегда - пустые, для некоторых
Serhii
у нас стоит так же StealthPlugin, который всякие блокеры обходит
Serhii
Давай будем рассматривать что это одна html страничка с 1-м имеджем
Serhii
для всех нормально, а для одной вот такая вот беда
Serhii
В html - картинка > мы делаем скриншот > скриншот пустой
Serhii
полноценная картинка внутри html
Serhii
а когда мы делаем скриншот, в headless режим, скриншот пустой
Serhii
он в html
Aleks
Есть у кого опыт вытягивания фоловеров из инсты без api, просто парсингом в лоб?
Aleks
Спасибо)
 Андрей
Андрей
Привет, ребят,
подскажите, пожалуйста, как с помощью queryParser получить доступ к элементу
id="A./b:c_"
Пробовал экранировать двоеточие и обратный слэщ
document.querySelector("#A.\\/b\\:c").querySelectorAll('tr');
Элемент не находится:
Uncaught TypeError: Cannot read property 'querySelectorAll' of null
Андрей
Привет, ребят,
подскажите, пожалуйста, как с помощью queryParser получить доступ к элементу
id="A./b:c_"
Пробовал экранировать двоеточие и обратный слэщ
document.querySelector("#A.\\/b\\:c").querySelectorAll('tr');
Элемент не находится:
Uncaught TypeError: Cannot read property 'querySelectorAll' of null
Ребят, есть вариант cheerio или в ноде заюзать CSS.escape ?
Андрей
Спасибо
Nikita
Господа, может вы сможете помочь.
пытаюсь скачать файл.
При нажатии на условное "скачать" открывается новая вкладка с адресом типа url.pdf и всё. Дальше любые действия бесполезны.
Киньте в меня идеей, пожалуйста, что можно сделать, что бы после перехода по url начиналось скачивание автоматически
Nikita
page.pdf([]) не работает.
page._client.send тоже не работает, т.к. по факту кнопка "скачать" не нажата, и ему нечего ловить
Nikita
Пробовал. Проблема в том, что у меня нету кнопки "скачать" или нормального url.
У меня открывается страница с пдф файлом после нажатия на enter, и иначе никак туда не попасть. И адресс файла одноразовый, т.е. я никак не могу начать скачивание.
Nikita
я немного тупенький в плане запросов. перехватил запрос, но че с ним делать не понятно )
Nikita
окей, сейчас попробую, спасибо
Anonymous
и правда нормальное))
 Robert
Robert
Добрый день. Есть ли спецы, готовые взяться за написание парсера с использованием puppeteer? Парсить требуется АлиЭкспресс
 倫太郎
倫太郎
Проще в окно
Alex*
Добрый день. Есть ли спецы, готовые взяться за написание парсера с использованием puppeteer? Парсить требуется АлиЭкспресс
https://developers.aliexpress.com/en/doc.htm?docId=108088&docType=1
Alex*
я мельком глянул вроде все есть
Alex*
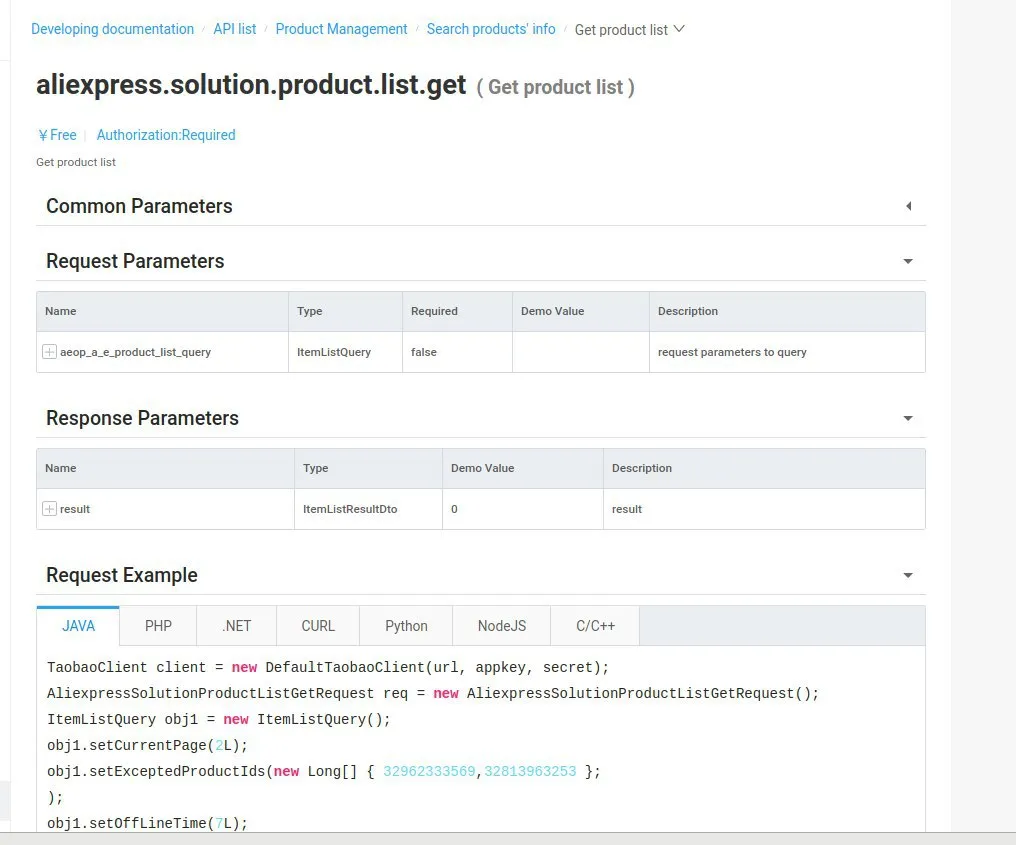 Alex*
Alex*
Я думаю это другое. Здесь для разработчиков
Alex*
https://developers.aliexpress.com/
Alex*
но наверное только для китайских
Alex*
 Alex*
Alex*
Да, что-то такое. Значит надо парсить. )
Robert
У меня есть возможность получать товары, категории, ссылки на товары, но нужны отзывы
Андрей
Привет, ребят,
Подскажите пож. Есть ли возможность c помощью puppeteer.js скачать файл по ссылке.
Находил примеры с переходом на страницу с изображениями и скачивание с текущей страницы https://.../1.jpg,
Но это не то. У меня именно документ, который нельзя открыть в новой вкладке (!!! какие то Java EE/ либо JS заморочки)
Только скачать из текущей страницы по ссылке.
По идее нужно имитировать клик, тут проблем нет.
Далее нужно как то забрать скачивающийся файл. Вот тут вопрос - как можно сделать?
1
Привет, ребят,
Подскажите пож. Есть ли возможность c помощью puppeteer.js скачать файл по ссылке.
Находил примеры с переходом на страницу с изображениями и скачивание с текущей страницы https://.../1.jpg,
Но это не то. У меня именно документ, который нельзя открыть в новой вкладке (!!! какие то Java EE/ либо JS заморочки)
Только скачать из текущей страницы по ссылке.
По идее нужно имитировать клик, тут проблем нет.
Далее нужно как то забрать скачивающийся файл. Вот тут вопрос - как можно сделать?
Пример сохранения файла из Я.Диск
await page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: '/download' // Путь куда сохранять
});
// Сохранить файл Я.Диск
await page.evaluate(() => {
document.querySelectorAll('.clamped-text')[0].click();
document.querySelector('.download-button').click();
});
Андрей
Пример сохранения файла из Я.Диск
await page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: '/download' // Путь куда сохранять
});
// Сохранить файл Я.Диск
await page.evaluate(() => {
document.querySelectorAll('.clamped-text')[0].click();
document.querySelector('.download-button').click();
});
А есть какой то вариант получить или определить имя скачиваемого файла? У меня при множестве вариациях всегда download без расширения.
Pavel
У кого нибудь были проблемы с запуском скрипта под макбуком? Скриншоты там пустые.
Pavel
Проще в окно
Нам тут такие админы не нужны, или по делу или сложите свои полномочия, плз. Хуже флудера.
Nikita
Господа, мне уже откровенно нужна помощь.
Я пару дней назад спрашивал про скачивание pdf файла, и с тех пор проблему не победил.
я напишу портянку с проблемой, может кто может чем помочь. А то я так чекнусь.
Задача такая - зайти в личный кабинет на сайте, и скачать оттуда пдф, перекодировать его в base64 и отправить ответом на бэк.
Проблема в том, что этот pdf файл открывается сразу в отдельной вкладке ".pdf" и кнопка "скачать" есть только в браузере. url с этим файлом живет очень короткое время и доступен только с куками от сессии (потому что авторизация на сайте через логин\пароль)
Удалось сейчас перехватить url, видимо на этапе ответа от сайта с помощью: "browser.on('targetcreated', async target => {})
По этому url можно пройти и даже откроется этот файл в отдельной вкладке, но при этом никаких ни запросов ни ответов не происходит. Просто открывается файл. Как-то перехватить тело ответа с файлом тоже не получается. И я хер его знает че делать с этим.
Уже 3й день мучаюсь, ситуация начинает выглядеть беспомощной.
 Andrey
Andrey
Что-то вроде такого: https://github.com/puppeteer/puppeteer/issues/299#issuecomment-486961980 ???
倫太郎
Нам тут такие админы не нужны, или по делу или сложите свои полномочия, плз. Хуже флудера.
На самом деле парсить алик почти самоубийство.
Там одних капч штук 5
倫太郎
Но вообще ты прав
Nikita
Ссылку на пдф уже смог перехватить.
Смогу даже, наверное, прервать запрос после получения ссылки.
Как потом сохранить в буфер, что бы перекодировать, не понятно. Гугл тоже не особо помогает.
Сейчас я родил только такую мысль:
Эта ссылка с .pdf на конце, по сути уже должна являться файлом.
Я пытался делать что то типа const n = await Page.goto(url.pdf)
Const buffer = n.buffer()
Но я получаю в буфере промис объект. А не пдф файл.
Сейчас попробую раскрыть промис, но не уверен, что получится.
Nikita
Ну вообще в фолс, что бы было видно, что я делаю.
Но в бою работа будет в хедлес
Nikita
Оу, я помоему пробовал это пару дней назад, и он не скачался, но может пару дней назад луна была в другой фазе.
Но в любом случае проблема с перекодированием не исчезнет.
Файл скачает я в докер, потому что браузер открыт на нем
Nikita
Сейчас протестирую эти варианты, если не получится, я напишу за помощью. Не откажете?)
Pavel
Ссылку на пдф уже смог перехватить.
Смогу даже, наверное, прервать запрос после получения ссылки.
Как потом сохранить в буфер, что бы перекодировать, не понятно. Гугл тоже не особо помогает.
Сейчас я родил только такую мысль:
Эта ссылка с .pdf на конце, по сути уже должна являться файлом.
Я пытался делать что то типа const n = await Page.goto(url.pdf)
Const buffer = n.buffer()
Но я получаю в буфере промис объект. А не пдф файл.
Сейчас попробую раскрыть промис, но не уверен, что получится.
Кек, дак буфер забирай и пиши в фаил с расширением pdf. Если в base64, декодируй перед этим.
Nikita
Кек, дак буфер забирай и пиши в фаил с расширением pdf. Если в base64, декодируй перед этим.
т.е. просто в константу записывать url и сохранять в буфер?
Pavel
т.е. просто в константу записывать url и сохранять в буфер?
Если это правильный буффер его можно просто записать на диск и он станет файлом.
Nikita
Кек, дак буфер забирай и пиши в фаил с расширением pdf. Если в base64, декодируй перед этим.
Я отловил url ток через таргет, вот такой штукой:
browser.on('targetcreated', async target => {
let url = target.url();}
если в консоле посмотреть тип таргета, он скажет, что это "page"
и сохранить эту штуку как файл не выходит.
Открыть ее можно только, если использовать куки с предыдущей страницы
Pavel
Я отловил url ток через таргет, вот такой штукой:
browser.on('targetcreated', async target => {
let url = target.url();}
если в консоле посмотреть тип таргета, он скажет, что это "page"
и сохранить эту штуку как файл не выходит.
Открыть ее можно только, если использовать куки с предыдущей страницы
Тебе random balance отписал с конкретным примером по скачке, если что.
Nikita
Тебе random balance отписал с конкретным примером по скачке, если что.
оки, да.
Я прост ещё не протестил эти варианты, не успел, отвлекли. сейчас займусь
Nikita
всё тлен. ничего не работает.
оказалось, что через таргет отловить url можно только если headless false
в безголовом режиме хера лысого.
Я не знаю че делать, я в отчаянии.
У меня остался только один вариант, но вероятность успеха минимальна.
Попробовать перехватить post запрос, который уходит на сервер сайта, отправить самостоятельно точно такой же ответ, но ждать не что угодно, а конкретно файл. Но это уже отчаяние.
Nikita
Схема в том, что после нажатия на кнопку "копия документа" (открывается копия в новой вкладке в формате пдф
Nikita
И после нажатия улетает пост запрос с json с данными для формирования документа. Документ формируется где-то в другом месте, а в ответ на запрос прилетает конструктор ссылки.
Pavel
всё тлен. ничего не работает.
оказалось, что через таргет отловить url можно только если headless false
в безголовом режиме хера лысого.
Я не знаю че делать, я в отчаянии.
У меня остался только один вариант, но вероятность успеха минимальна.
Попробовать перехватить post запрос, который уходит на сервер сайта, отправить самостоятельно точно такой же ответ, но ждать не что угодно, а конкретно файл. Но это уже отчаяние.
Отлавливай событие ‘response’, и бери body на крайняк, но с CDP кошернее наверно
Nikita
Отлавливай событие ‘response’, и бери body на крайняк, но с CDP кошернее наверно
пробовал, прилетает не тело, а конструктор ссылки.
и я цепляю херабору из которой в ручную я могу собрать ссылку и пройти по ней при условии, что делаю это в из той же сессии, где прокинуты куки
Pavel
Тогда мои полномочия все, окончены. Я тут случайно проходил вообще)
Nikita
Тогда мои полномочия все, окончены. Я тут случайно проходил вообще)
а как я хочу случайно проходить мимо этой проблемы. А не сидеть над этим сраным куском кода 3 дня :)