 Fedor
Fedor


На новый)
 Александр
Александр
Чем чревато работать на запись с zfs.recover=1?
Я не скажу конкретику, но в целом это все аварийные флаги. "Работать с тем, с чем лучше не работать"
 Vladislav
Vladislav
Чем чревато работать на запись с zfs.recover=1?
Насколько я помню - в этом состоянии он убивает все последние транзакции которые считаются не успешными
Vladislav
Насколько я помню - в этом состоянии он убивает все последние транзакции которые считаются не успешными
И запись соответственно может накрыться при следующем импорте пула
Vladislav
То есть записал ты 20 txg в recovery mode, а после перезапуска у тебя 17 из них только
Vladislav
То есть записал ты 20 txg в recovery mode, а после перезапуска у тебя 17 из них только
Recovery mode собственно позволяет тебе откатывать безвозвратно txg группы
И если ты маунтишь не как R/O, то будет вот так
Sl
Добрый ночи
Ivan
если ссылку оформить как цитату, то бот пропустит
Sl
Дела настройку openzfs Debian12 bookmaker ,(ссылку пока заблокировали )
С двумя дисками , вроде все ок
Но начал тестировать , с одним диском запускается
С другим нет
Sl
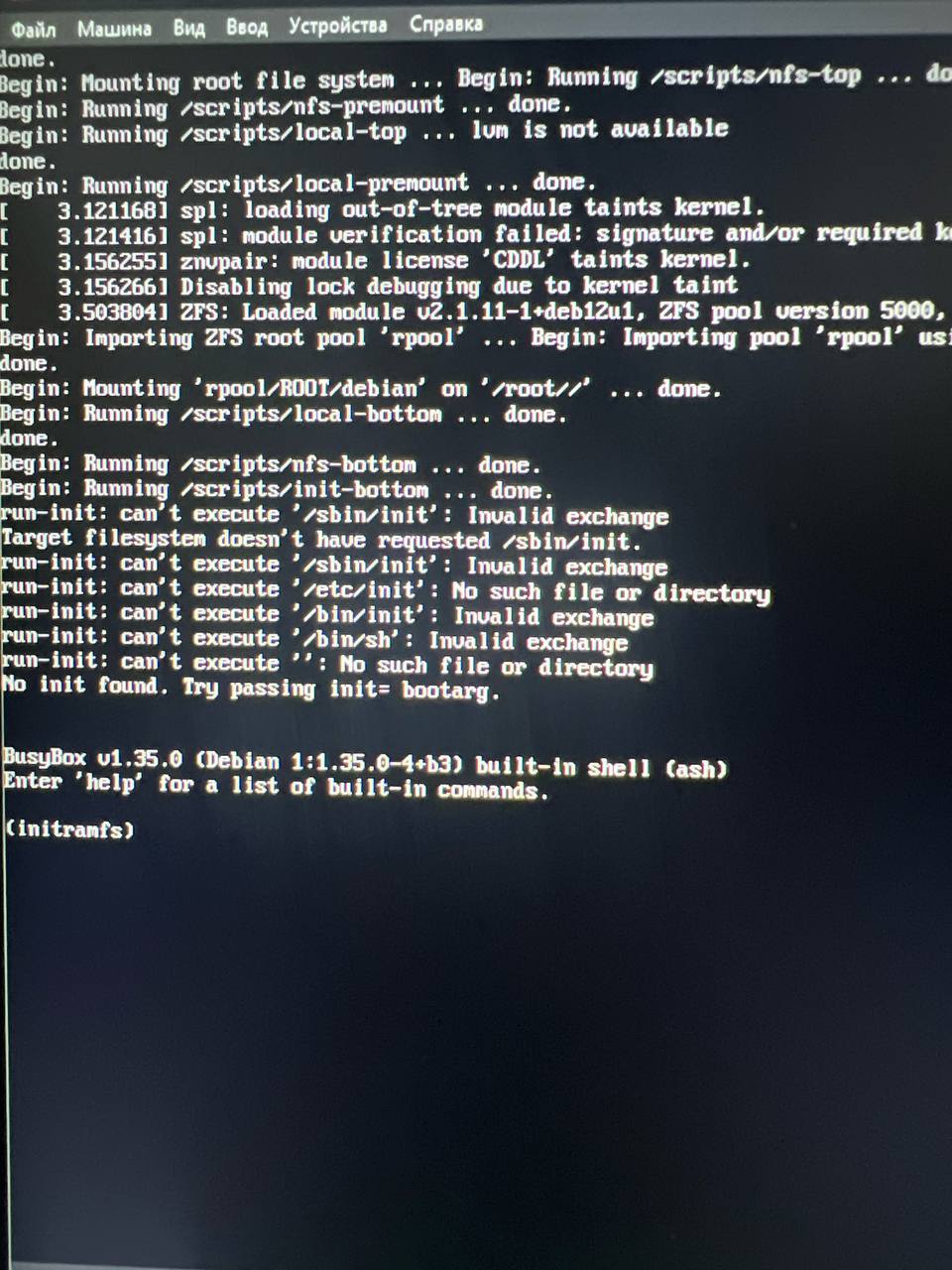 Sl
Sl
Щас хотел с двумя сделать, такая же ошибка (
 Khajiit
Khajiit
Khajiit
Khajiit
А вообще, это э виртуалка?
Sl
Khajiit
Если это была просто тестовая виртуалка, то тогда проще пересоздать и не морочиться, кмк
 The Join Captcha Bot
The Join Captcha Bot
Капча решена, Пользователь подтвержден.
Добро пожаловать в чат, @srgcs2
 hz
hz
подскажите feature@... которые указываются только при создании можно в ходе использования включить или нужно пересоздавать пул? Я к чему пул boot grub2 перестал видеть, было указано zp-boot compatibility grub2 local. Чтение мана, показало что у версий 2.12 2.06 разные наборы параметров которые они поддерживают. Наверное надо было указать zp-boot compatibility grub2-2.06 local . А в дебиан последняя версия 2.06 =(
hz
я их не включал, добавил только снимки по времени, но они ничего не включают. Странно что compatibility grub2 работало при 2.06 версии около года, а теперь решило напомнить о себе, ну так чтобы веселее жилось...
 George
George
George
George
Не помню помогает ли удаление этого снапа правда
hz
Не помню помогает ли удаление этого снапа правда
мне не помогло удаление снимка и даже пересоздание пула с ограничением, к этому нужно ещё было переустановить grub на этом диске. спасибо за помощь.
 Alisa
Alisa
@oaSiwk131 а точно не бот? :D
 Fedor
Fedor
Если будут признаки бота, его забанит
George
В мире локальных стораджей наметилась очень интересная тенденция складывать всё в S3,
AWS у себя в FSx (где они используют zfs) ловко сделали псевдо-tiering и сгружают данные сразу в S3:
This change is in use by FSx in production today for FSx Intelligent Tiering file systems, which use S3 storage-backed vdevs.
А пару лет назад Delphix передумал выкладывать object-based vdev в апстрим.
Интересный кейс, выгода решает.
 Free
Free
данные в ОЗУ всё равно окажутся (на записи), если прям уверены что кеш на чтение не нужен, то можно выставить primarycache=metadata (но не рекомендую)
не стоит экономить неиспользованную память, бОльший кеш всегда упрощает жизнь, даже если он штатно быстро дропнется.
min=max кстати может такой эффект дать, думаю, я бы вернул в дефолты и тестил дальше
По поводу большой загрузки CPU процессами arc_prune и arc_evict - вынужденное продолжение тестирования.
На днях апгрейд debian/zfs спровоцировал рецидив проблемы: загрузка CPU под 80-90% на каждый их этих процессов, сопровождающаяся очень частой аварийной перезагрузкой сервера.
В попытках избежать перезагрузки был установлен primarycache=none НА ВСЕХ пулах/датасетах.
Однако это не снизило нагрузку на CPU от arc_prune и arc_evict.
Ниже дам подробности про конфигурацию сервера, но независимо от этого возникает 2 вопроса:
❓1) Чем вообще занимаются arc_prune и arc_evict, если primarycache=none НА ВСЕХ пулах/датасетах???
2) Как (пусть за счет ухудшения производительности дисковых операций) полностью отключить arc, чтобы процессы arc_prune и arc_evict вообще не запускались?
Free
Конфигурация сервера:
root@S04:~# cat /etc/debian_version
12.9
root@S04:~# zfs version
zfs-2.2.7-1~bpo12+1
zfs-kmod-2.2.7-1~bpo12+1
root@S04:~# uname -r
6.12.9+bpo-amd64
Память 64 ГБ, при всех протестированных вариантах установок zfs_arc_min/zfs_arc_max минимум 8ГБ было available
30 HDD c одинарными пулами, на каждом по 2 ноды storj, которые создают довольно большую нагрузку на диски. Проблемы с arc_prune/arc_evict и перезагрузки проявляются при работе примерно начиная от 3/4 от общего количества нод. До этого несколько месяцев работали все ноды с максимальной загрузкой без каких-либо проблем, никакие настройки системы не менялись.
При этом стояло primarycache=all, zfs_arc_min=zfs_arc_max=8ГБ. При тестировании сейчас перебирал разные значения, в том числе дефолтные (которые zfs установил в 2/32).
При активной работе arc_prune/arc_evict arc_summary показывает ARC size (current):, превышающей 100% (доходило до 200%) ДАЖЕ ПРИ primarycache=none
Alisa
По поводу большой загрузки CPU процессами arc_prune и arc_evict - вынужденное продолжение тестирования.
На днях апгрейд debian/zfs спровоцировал рецидив проблемы: загрузка CPU под 80-90% на каждый их этих процессов, сопровождающаяся очень частой аварийной перезагрузкой сервера.
В попытках избежать перезагрузки был установлен primarycache=none НА ВСЕХ пулах/датасетах.
Однако это не снизило нагрузку на CPU от arc_prune и arc_evict.
Ниже дам подробности про конфигурацию сервера, но независимо от этого возникает 2 вопроса:
❓1) Чем вообще занимаются arc_prune и arc_evict, если primarycache=none НА ВСЕХ пулах/датасетах???
2) Как (пусть за счет ухудшения производительности дисковых операций) полностью отключить arc, чтобы процессы arc_prune и arc_evict вообще не запускались?
Выключить полностью ARC
echo 0 > /sys/module/zfs/parameters/zfs_arc_max
Но потоки после этого сами по себе не завершатся скорее всего
Free
А почему так мало RAM?
Потому что нодам storj (а кроме них на сервере ничего нет) этого выше крыши.
Обычо во время работы было available ~32GB
Free
Выключить полностью ARC
echo 0 > /sys/module/zfs/parameters/zfs_arc_max
Но потоки после этого сами по себе не завершатся скорее всего
Пробовал min=max=0.
При этом система рассматривает 0 как указание использовать дефолтные значения и устанавливает 2/32
Alisa
Попробуйте так - echo "options zfs zfs_arc_max=0" > /etc/modprobe.d/zfs.conf
Alisa
но нужен ребут :(
Free
Попробуйте так - echo "options zfs zfs_arc_max=0" > /etc/modprobe.d/zfs.conf
так и делал.
Ребут и так постоянно происходит 😊
Alisa
или рестарт всех zfs демонов
 Alexey
Alexey
update-initramfs -u -k all
Alexey
после изменений в modprobe
Alisa
@FreeKopcap что у вас в выдаче
cat /sys/module/zfs/parameters/zfs_arc_max
cat /sys/module/zfs/parameters/l2arc_noprefetch
Alexey
до reboot
Free
@FreeKopcap что у вас в выдаче
cat /sys/module/zfs/parameters/zfs_arc_max
cat /sys/module/zfs/parameters/l2arc_noprefetch
root@S04:~# cat /sys/module/zfs/parameters/zfs_arc_max
0
root@S04:~# cat /sys/module/zfs/parameters/l2arc_noprefetch
1
root@S04:~#
Alisa
очень странно
Free
При этом сейчас
root@S04:~# arc_summary | grep -A 3 "ARC size (current)"
ARC size (current): 102.8 % 32.3 GiB
Target size (adaptive): 20.7 % 6.5 GiB
Min size (hard limit): 6.2 % 2.0 GiB
Max size (high water): 16:1 31.4 GiB
Alisa
echo "options zfs zfs_arc_max=0" > /etc/modprobe.d/zfs.conf
update-initramfs -u -k all
reboot
Alisa
Пробовали так?
Alexey
я бы не пытался отключить arc:
во-первых, не получится,
во-вторых, zfs без arc не нужен.
его можно ограничить, но у него есть настройка минимального объема памяти, ниже которого не получится настроить.
Alexey
При этом сейчас
root@S04:~# arc_summary | grep -A 3 "ARC size (current)"
ARC size (current): 102.8 % 32.3 GiB
Target size (adaptive): 20.7 % 6.5 GiB
Min size (hard limit): 6.2 % 2.0 GiB
Max size (high water): 16:1 31.4 GiB
сейчас у Вас арк настроен на значение по умолчанию: половина озу под него отдается.
минимальное значение 2гб, не меньше.
текущее 6,5
Отношение минимального к максимальному 16:1, т.е. 32:2
 I
I
Чтобы изменения вступили в силу, нужно перезагружать модуль ядра, вот пример, с проверкой, что модуль используется, этот способ на тесте использовал:
lsmod | grep zfs
zfs unmount -a
zpool export -a
modprobe -r zfs && modprobe zfs
zpool import -a
zfs mount -a
Free
я бы не пытался отключить arc:
во-первых, не получится,
во-вторых, zfs без arc не нужен.
его можно ограничить, но у него есть настройка минимального объема памяти, ниже которого не получится настроить.
В будущем собирался включить.
Это в рамках тестирования, чтобы на какое-то время избежать непрерывных перезагрузок сервера и дать возможность нодам storj успеть еще кое-что сделать
Alexey
можно попробовать экспортировать пулл, т.е. отключить его от системы (если это возможно). И посмотреть на загрузку проца.
Free
сейчас у Вас арк настроен на значение по умолчанию: половина озу под него отдается.
минимальное значение 2гб, не меньше.
текущее 6,5
Отношение минимального к максимальному 16:1, т.е. 32:2
Да, это стало после того, как записал zfs_arc_min=zfs_arc_max=0 - видимо нулевые значения zfs воприняла как указание использовать дефолт.
До этого пробовал разные другие значения
Free
можно попробовать экспортировать пулл, т.е. отключить его от системы (если это возможно). И посмотреть на загрузку проца.
Можно проще.
Если остановить все ноды storj - нагрузка всего (в том числе arc_prune/arc_evict) падает до 0
Alexey
напишите:
zpool status -v
Free
напишите:
zpool status -v
следил за этим.
Все 30 online, errors: No known data errors
Кроме одного вспомогательного mirror на SSD, у которого один из дисков недавно отвалился, он degraded, но работает без ошибок.
Alexey
судя по всему, не увидим :)
Free
судя по всему, не увидим :)
Ну вот начало:
root@S04:~# zpool status -v
pool: db
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: scrub repaired 0B in 00:04:52 with 0 errors on Sun Dec 8 00:28:54 2024
config:
NAME STATE READ WRITE CKSUM
db DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
3343446589784457371 UNAVAIL 0 0 0 was /dev/disk/by-id/ata-ADATA_SU650_2K442L12J9YX-part1
ata-ADATA_SU650_2L1329ACCKXL ONLINE 0 0 0
errors: No known data errors
pool: s01
state: ONLINE
scan: scrub canceled on Tue Dec 10 18:15:21 2024
config:
NAME STATE READ WRITE CKSUM
s01 ONLINE 0 0 0
wwn-0x5000c500e664a10a ONLINE 0 0 0
errors: No known data errors
pool: s02
state: ONLINE
scan: scrub canceled on Tue Dec 10 18:18:36 2024
config:
NAME STATE READ WRITE CKSUM
s02 ONLINE 0 0 0
wwn-0x5000c500e6605dda ONLINE 0 0 0
errors: No known data errors
ну и так далее до s30 - не хочу забивать здесь длинной простыней
Free
Еще одно наблюдение:
После перезагрузки долгое время top вообще не видит arc_prune/arc_evict, потом вдруг сразу же они появляются с 80-90% CPU.
Через некоторое время могут снова исчезнуть.
Ну и про ошибки:
В dmesg и journalctl при аварийной перезагрузке никаких сообщений не появляется 🙈
Alexey
можно попробовать по одному пул отключать и искать на каком проблемы появляются. Это пока догадка, что какой-то из пулов капризит.
Станислав
Еще одно наблюдение:
После перезагрузки долгое время top вообще не видит arc_prune/arc_evict, потом вдруг сразу же они появляются с 80-90% CPU.
Через некоторое время могут снова исчезнуть.
Ну и про ошибки:
В dmesg и journalctl при аварийной перезагрузке никаких сообщений не появляется 🙈
А что с температурой проца и других компонентов? Может рубиться то по причине перегрева или БП по питанию не вывозит
Vladislav
Еще одно наблюдение:
После перезагрузки долгое время top вообще не видит arc_prune/arc_evict, потом вдруг сразу же они появляются с 80-90% CPU.
Через некоторое время могут снова исчезнуть.
Ну и про ошибки:
В dmesg и journalctl при аварийной перезагрузке никаких сообщений не появляется 🙈
Попробуй мониторить latency на диски
Free
Попробуй мониторить latency на диски
Все диски в storj под высокой нагрузкой, равномерно по всем дискам, и это всегда так было и на этом сервере, и на всех остальных.
Вот так в среднем
avg-cpu: %user %nice %system %iowait %steal %idle
4.02 0.00 14.39 79.87 0.00 1.72
Vladislav
Все диски в storj под высокой нагрузкой, равномерно по всем дискам, и это всегда так было и на этом сервере, и на всех остальных.
Вот так в среднем
avg-cpu: %user %nice %system %iowait %steal %idle
4.02 0.00 14.39 79.87 0.00 1.72
avg не особо поможет, если какой-то диск уходит в iowait на 2сек
Vladislav
А остальные в 300-400мс
George
По поводу большой загрузки CPU процессами arc_prune и arc_evict - вынужденное продолжение тестирования.
На днях апгрейд debian/zfs спровоцировал рецидив проблемы: загрузка CPU под 80-90% на каждый их этих процессов, сопровождающаяся очень частой аварийной перезагрузкой сервера.
В попытках избежать перезагрузки был установлен primarycache=none НА ВСЕХ пулах/датасетах.
Однако это не снизило нагрузку на CPU от arc_prune и arc_evict.
Ниже дам подробности про конфигурацию сервера, но независимо от этого возникает 2 вопроса:
❓1) Чем вообще занимаются arc_prune и arc_evict, если primarycache=none НА ВСЕХ пулах/датасетах???
2) Как (пусть за счет ухудшения производительности дисковых операций) полностью отключить arc, чтобы процессы arc_prune и arc_evict вообще не запускались?
а что такое в вашем случае то аварийная перезагрузка? что провоцирует?
arc в том или ином виде всегда будет использоваться ибо это аналог pagecache у zfs. Как совет по умолчанию - сначала откатите любые изменения настроек до дефолтных и от этого раскручивайте.
Free
а что такое в вашем случае то аварийная перезагрузка? что провоцирует?
arc в том или ином виде всегда будет использоваться ибо это аналог pagecache у zfs. Как совет по умолчанию - сначала откатите любые изменения настроек до дефолтных и от этого раскручивайте.
Основное отличие от остальных серверов (и от этого сервера в том состоянии, когда не было перезагрузок) - это как раз загрузка CPU процессами arc_prune/arc_evict до 80-90%.
Никаких сигналов непосредственно в момент перезагрузки обнаружить не удалось.
Значения zfs_arc_min, zfs_arc_max сейчас, во время тестирования, установились как раз дефолтные 2/32 (до этого долгое время были одинаковые = 8ГБ - тоже из каких-то рекомендаций, что это уменьшает работу arc_prune/arc_evict).
primarycache в попытке убрать arc_prune/arc_evict установил в none - но, наверное, сейчас снова верну =all, раз они не убираются
George
Основное отличие от остальных серверов (и от этого сервера в том состоянии, когда не было перезагрузок) - это как раз загрузка CPU процессами arc_prune/arc_evict до 80-90%.
Никаких сигналов непосредственно в момент перезагрузки обнаружить не удалось.
Значения zfs_arc_min, zfs_arc_max сейчас, во время тестирования, установились как раз дефолтные 2/32 (до этого долгое время были одинаковые = 8ГБ - тоже из каких-то рекомендаций, что это уменьшает работу arc_prune/arc_evict).
primarycache в попытке убрать arc_prune/arc_evict установил в none - но, наверное, сейчас снова верну =all, раз они не убираются
в общем у них говорящие название, это треды по вытеснению из кеша, вызываются либо при переполнении кеша либо когда ядро память просит, обычно на это наталкиваются те у кого огромный рейт изменений в кеше, что обычно бывает с nvme а не с hdd. На hdd весьма сложно такого достичь, но можно представить вырожденные кейсы аля огромный recordsize и тд.
Я бы начал рыть в причины ребута. Сам факт загрузки этих тредов может быть не связан напрямую с ребутом.
Free
в общем у них говорящие название, это треды по вытеснению из кеша, вызываются либо при переполнении кеша либо когда ядро память просит, обычно на это наталкиваются те у кого огромный рейт изменений в кеше, что обычно бывает с nvme а не с hdd. На hdd весьма сложно такого достичь, но можно представить вырожденные кейсы аля огромный recordsize и тд.
Я бы начал рыть в причины ребута. Сам факт загрузки этих тредов может быть не связан напрямую с ребутом.
nvme вообще нет.
Есть SATA SSD (деградировавший mirror: один SSD отвалился, пока не собрался его заменить).
На нем - базы storj. Объем небольшой, primarycache тоже сейчас none
Free
а что такое в вашем случае то аварийная перезагрузка? что провоцирует?
arc в том или ином виде всегда будет использоваться ибо это аналог pagecache у zfs. Как совет по умолчанию - сначала откатите любые изменения настроек до дефолтных и от этого раскручивайте.
Аварийной я её называю, потому что она даже не успевает делать нормальный shutdown.
Вот как last reboot выглядит:
reboot system boot 6.12.9+bpo-amd64 Mon Feb 17 18:21 still running
reboot system boot 6.12.9+bpo-amd64 Mon Feb 17 17:53 still running
reboot system boot 6.12.9+bpo-amd64 Mon Feb 17 16:50 still running
reboot system boot 6.12.9+bpo-amd64 Mon Feb 17 16:29 still running
reboot system boot 6.12.9+bpo-amd64 Mon Feb 17 15:56 still running
Alisa
@FreeKopcap что в логах BMC?
Free
больше похоже на аппаратную проблему
uptime был несколько месяцев до того, как на днях apt upgrade сделал.
К тому же при снижении нагрузки (остановке половины нод storj) работает нормально.
Станислав
Free
Железо не серверное? Особенно интересует БП
Материнка и половина дисков питается от Cougar GEX750 (80 plus gold), вторая половина дисков на еще одном 750 (тоже, кажется, gold)
Сейчас не у компьютера, не могу посмотреть точнее
Станислав
Материнка и половина дисков питается от Cougar GEX750 (80 plus gold), вторая половина дисков на еще одном 750 (тоже, кажется, gold)
Сейчас не у компьютера, не могу посмотреть точнее
У обычных БП есть одна фича - при резком повышение нагрузки, примерно ватт на 100, они считают это как КЗ и уходят в защиту. Учитывая, что проц пыхтит там, то при небольшой паузе может снизиться потребление, а потом одним махом вернуться в прежний режим жора и срабатывает защита. Я много раз наблюдал такие приколы. По идее на серверных БП тоже защита подобная есть, но ни разу не столкнулся
Nikita
У обычных БП есть одна фича - при резком повышение нагрузки, примерно ватт на 100, они считают это как КЗ и уходят в защиту. Учитывая, что проц пыхтит там, то при небольшой паузе может снизиться потребление, а потом одним махом вернуться в прежний режим жора и срабатывает защита. Я много раз наблюдал такие приколы. По идее на серверных БП тоже защита подобная есть, но ни разу не столкнулся
а запуск тяжёлой игры с мощной видяхой разве не то же самое по нагрузке делает?
Станислав
а запуск тяжёлой игры с мощной видяхой разве не то же самое по нагрузке делает?
Обычно они плавно это делают. Но бывают случаи, особенно с жрущими видяхами по типу 3080Ti, что компы рубит по такому принципу. Можете поискать в гугле что-то с запросом "3080ti shutdown my pc". На форумах полно жалоб
 Artem
Artem
У обычных БП есть одна фича - при резком повышение нагрузки, примерно ватт на 100, они считают это как КЗ и уходят в защиту. Учитывая, что проц пыхтит там, то при небольшой паузе может снизиться потребление, а потом одним махом вернуться в прежний режим жора и срабатывает защита. Я много раз наблюдал такие приколы. По идее на серверных БП тоже защита подобная есть, но ни разу не столкнулся
Очень странно попахивает. Дельта всего 100 ватт - это меньше, чем проц из айдла ушел на 100% нагрузки. А они это делают очень быстро.