 Vladislav
Vladislav


https://www.youtube.com/watch?v=cWI5_Kzlf3U
Vladislav
Ага вот теперь ясно 👍 но в некоторых сценариях я предпочту чтобы все же с памяти читало , ибо туда влезают все наши проекты , спасибо за разъяснение
Для All-flash nvme gen4 это медленнее будет да

 Georg🎞️🎥
Georg🎞️🎥
qnap вроде сам интегрировал допиленный DirectIO, но это не точно
Надо будет купить как нить через лет пять )) когда u2 на 60 теров будут не 500к ))
Vladislav
При включённом DirectIO=always
Vladislav
У нас процессор и процесс разве один?
Если же ты про =standard, то тогда из памяти берётся.
For O_DIRECT writes:
The request also must be block aligned (recordsize) or the write request will take the normal (buffered) write path.
In the event that request is block aligned and a cached copy of the buffer in the ARC, then it will be discarded
from the ARC forcing all further reads to retrieve the data from disk.
For O_DIRECT reads:
The only alignment restrictions are PAGE_SIZE alignment. In the event that the requested data is in buffered
(in the ARC) it will just be copied from the ARC into the user buffer.
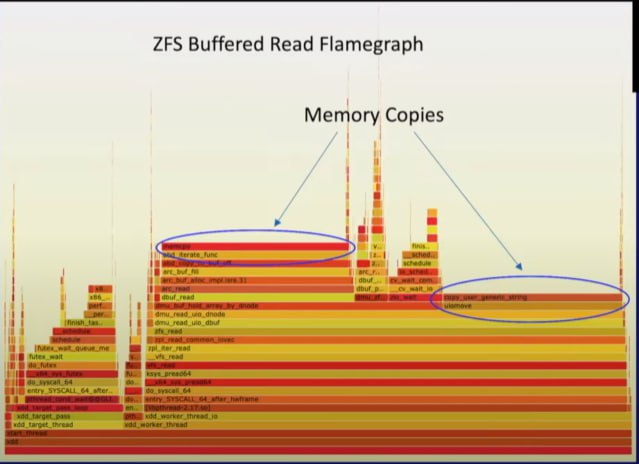
 Artem
Artem
Но O_DIRECT не пытается теперь копировать в ARC всё по радиусу
Ну то есть на чтение всё в порядке?
Vladislav
Ну то есть на чтение всё в порядке?
Если у тебя =standard, то для запросов без O_DIRECT ничего не меняется
Artem
Если у тебя =standard, то для запросов без O_DIRECT ничего не меняется
А когда меняется для запросов на чтение?
Vladislav
Если у тебя приложение 1 читает файл без O_DIRECT, а потом приложение 2 читает файл с O_DIRECT - то приложение 1 копирует его в ARC, затем приложение 2 берёт его тоже из ARC
Если у тебя =always, то приложение 1 лезет сразу в NVMe и приложение 2 аналогично
Artem
Чот сложна. Есть данные в кеше - отдаем оттуда, нет - лезем на диск. При записи - чуть иначе
Vladislav
Чот сложна. Есть данные в кеше - отдаем оттуда, нет - лезем на диск. При записи - чуть иначе
Только чуть сложнее, потому что даже если они есть на диске - ZFS не будет их копировать в ARC и читать потом оттуда
Artem
Или o_direct не оставляет следов чтения в кеше?
Vladislav
https://docs.google.com/presentation/d/1f9bE1S6KqwHWVJtsOOfCu_cVKAFQO94h/edit
Vladislav
И презентация
 Δαρθ
Δαρθ
При записи СИЛЬНО сокращается время, которое ZFS тратит на memcopy между кэшами
а зачем копировать между чем-то? просто указатель на кусок памяти перекинуть из одного кеша в другой -- не?
A
От копирования в памяти все равно никуда не деться. Весь вопрос только сколько раз будет такое копирование.
Vladislav
а зачем копировать между чем-то? просто указатель на кусок памяти перекинуть из одного кеша в другой -- не?
Между ядром и юзерспейсом? Немного так не работает
Vladislav
Я же написал, что это "очень грубое" объяснение
 Андрей🧛
Андрей🧛
всем привет, ребята подскажи у вас какое время билда на пулах zfs?
Андрей🧛
у меня вот такие показателя
Device Model: HGST HUS728T8TALE6L4
Serial Number: VGJ2WU8G
rpool 300T 8,9T 291T 3% /rpool
scan: resilvered 5,03T in 452h55m with 0 errors on Sat Sep 14 06:30:12 2024
Андрей🧛
еще один такой же пулл все еще в билде порядка 2-3 недель наверно
 George
George
у меня вот такие показателя
Device Model: HGST HUS728T8TALE6L4
Serial Number: VGJ2WU8G
rpool 300T 8,9T 291T 3% /rpool
scan: resilvered 5,03T in 452h55m with 0 errors on Sat Sep 14 06:30:12 2024
zpool status покажите лучше, плюс версию zfs -V и zfs get all
на raidz неоптимальном ожидаемо может быть долго. Для больших массивов стоит рассматривать draid который как раз может при вылете диска быстро восстановить избыточность
George
у меня вот такие показателя
Device Model: HGST HUS728T8TALE6L4
Serial Number: VGJ2WU8G
rpool 300T 8,9T 291T 3% /rpool
scan: resilvered 5,03T in 452h55m with 0 errors on Sat Sep 14 06:30:12 2024
и вы в личке про регулярные ошибки на дисках говорили, это верный признак наличия проблем с оборудованием
Андрей🧛
и вы в личке про регулярные ошибки на дисках говорили, это верный признак наличия проблем с оборудованием
Согласен,возможно hba дохнуть начинают. Щас переходим на adaptec план стоит выпилить ото всюду zfs,и остаться на Хардах,хотя буквально в четверг на adaptec рейд ушел в деградейт (60) и закрылся от записи и пару часов записи потеряли
Δαρθ
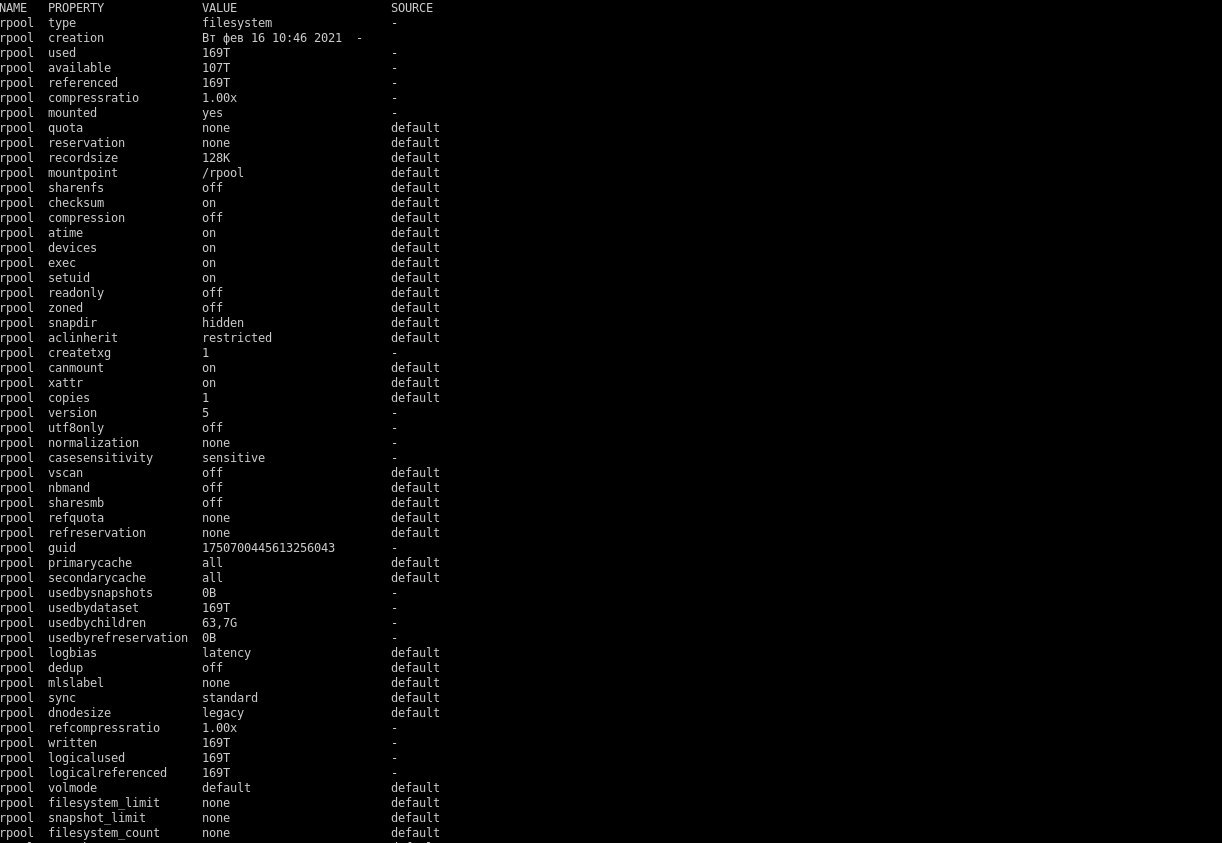 Андрей🧛
Андрей🧛
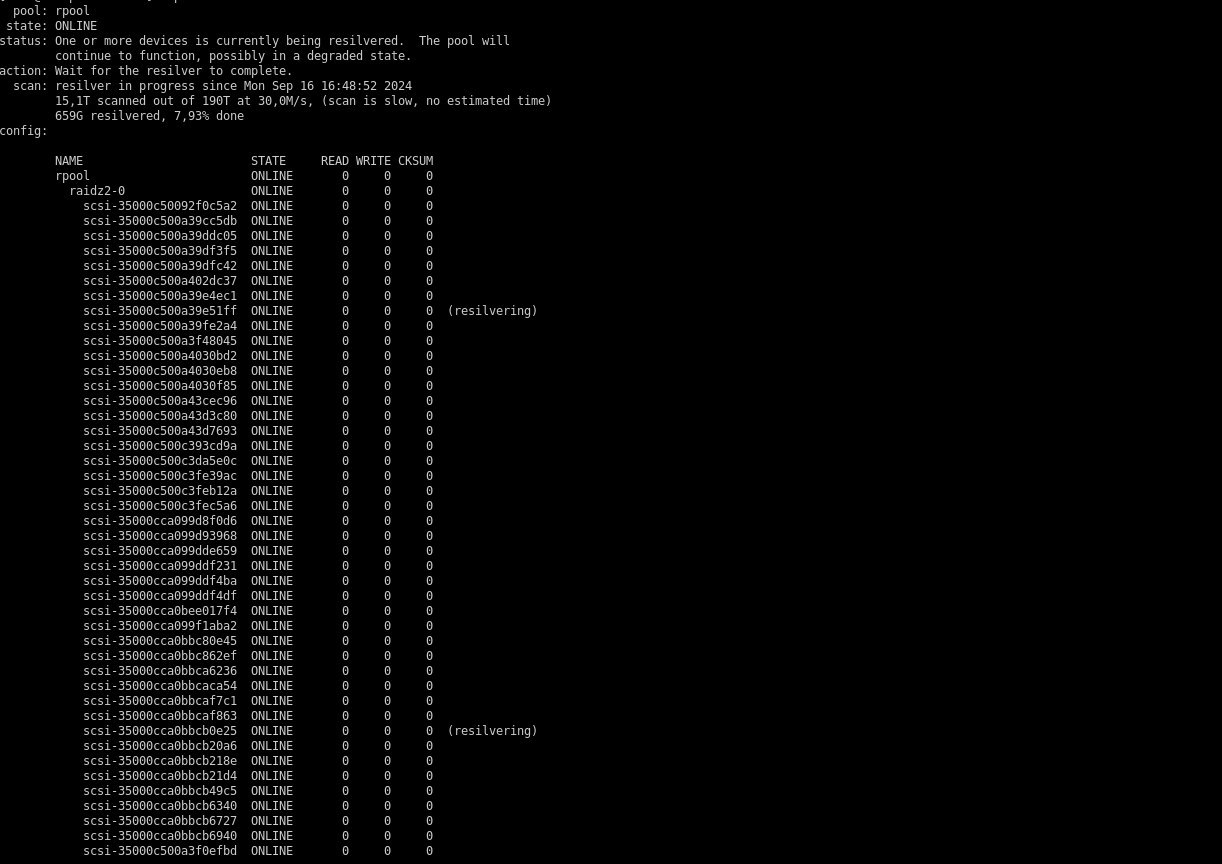 Андрей🧛
Андрей🧛
ну а версию не показывает просто открывает man до меня все еще это собирали,да и ось там centos 7
 Roman
Roman
Это законно столько дисков в raidz пихать?
Vladislav
Не увидел там ничего про копирование из кеша в кеш
А зря
Стоит тогда внимательнее почитать
Или если с этим сложно послушать видосик
 Vladislav
Vladislav
Это законно столько дисков в raidz пихать?
это довольно неразумно, где-то считали, что оптимально 7-9 дисков в группе raidz
Ivan
тут получа ется что страйпы из raidz2 выгодней по скорости работы, ресильвера, да еще и по месту не сильно проиграешь.
George
George
zfs тут себя отлично показал, несколько лет не разваливался к чертям)
George
ну а версию не показывает просто открывает man до меня все еще это собирали,да и ось там centos 7
в свежих версиях ресильвер сделали поточным, т.е. сильно ускорили, увы без версии понять есть ли оно уже в вашей версии нельзя
George
Андрей🧛
это довольно неразумно, где-то считали, что оптимально 7-9 дисков в группе raidz
Да тоже уже читали,но это работает за пол года два диска вылетело,а вот ошибки скидывать надо каждый день ну или через день
George
Согласен,возможно hba дохнуть начинают. Щас переходим на adaptec план стоит выпилить ото всюду zfs,и остаться на Хардах,хотя буквально в четверг на adaptec рейд ушел в деградейт (60) и закрылся от записи и пару часов записи потеряли
Не важно что выберете - не собирайте один raid6, собирайте аналог raid60 хотя бы
Андрей🧛
Не важно что выберете - не собирайте один raid6, собирайте аналог raid60 хотя бы
Не щас везде на харде 50 и 60 рейды
George
Ну и на таких числах стоит смотреть на draid, он ровно для таких кейсов делался
Андрей🧛
Ну на скрине - нет:)
Так это zfs а я как говорил у нас плановый переход на железные рейды,этот сервер щас стоит в отстое т.е бекап истекает через месяц) уберу тут и еще на пару серверах zfs
George
Так это zfs а я как говорил у нас плановый переход на железные рейды,этот сервер щас стоит в отстое т.е бекап истекает через месяц) уберу тут и еще на пару серверах zfs
расскажите обязательно про опыт на аппаратных рейдах через полгода-год
George
Сравним
Ivan
занятно. я наоборот от всех железных рейдов избавился, т.к. они данные били (в raid10 нет контроля четности).
Андрей🧛
расскажите обязательно про опыт на аппаратных рейдах через полгода-год
Так могу и сейчас у меня 32 сервера хранилища на 18 сереверах уже стоят железные из 18 где то половина sas диски,не одного вылета. А вот sata летят не часто но бывает,но тут специфика. Видео наблюдение порядка 20 тыс камер на них пишут,а сервера аналитики читают
Андрей🧛
занятно. я наоборот от всех железных рейдов избавился, т.к. они данные били (в raid10 нет контроля четности).
10 рейды не использую воообще,у меня самое маленькое хранилище это 145тб
Roman
Можно было бы глюстер какой-нибудь собрать из пачки сервров.
Андрей🧛
Можно было бы глюстер какой-нибудь собрать из пачки сервров.
Это было сделано до моего прихода
 Eug
Eug
чат, разбираюсь в zfs. подскажите пожалуйста, я правильно понимаю что грубо говоря zfs — это более апргрейднутый вариант raid массивов?
 Fedor
Fedor
ZFS это, можно сказать, сервис внутри системы, в котором есть возможность в том либо ином виде хранить данные на тех либо иных носителях. Включая функционал, схожий с разными видами рейдов.
Vladislav
это довольно неразумно, где-то считали, что оптимально 7-9 дисков в группе raidz
https://jro.io/nas/#overhead
В том числе
Eug
ZFS это, можно сказать, сервис внутри системы, в котором есть возможность в том либо ином виде хранить данные на тех либо иных носителях. Включая функционал, схожий с разными видами рейдов.
м, вот как. получается мы мы можем объединять различные типы дисков (HDD + SSD) и при этом получаем хороший перфоманс?
Fedor
Перфоманс всегда будет по самому медленному диску в пуле. Оптимизации по скорости есть, но это продумывается на этапе проектирования, учитывая все вводные
Fedor
Это инструмент, который надо использовать к месту и уметь готовить, тогда он покажет прекрасные результаты
Eug
Eug
вот я что-то не совсем понимаю чем он так крут
искренне хочу разобраться
Eug
тип, неужели остальные аналоги (ext4, btrfs) хреновые?
Dim-soft
вот я что-то не совсем понимаю чем он так крут
искренне хочу разобраться
У меня были 40-к HDD seagate с родовой травмой и за месяц все умерли, были под Adaptec RAID 5, Windows SS и ZFS - только на ZFS ,без потери данных были плавно поменяны на другие, все остальные варианты или совсем потеряли данные (adaptec) или я их смог прочитать в RO после восстановления на спец оборудовании (Windows SS)
Fedor
вот я что-то не совсем понимаю чем он так крут
искренне хочу разобраться
В первом закрепе находится ссылка на ресурсы с документацией по зфс. Можно начать ознакомление с них, ознакомиться с возможностями.