 Vladislav
Vladislav


Потому что 870 evo задохнется от 4k
 Shaker
Shaker
 Ivan
Ivan
Коллеги, наткнулся на такой момент в archwiki
Summarizing Toponce's guidance:
RAIDZ2 should use four (2+2), six (4+2), ten (8+2), or eighteen (16+2) disks.
RAIDZ3 should use five (2+3), seven (4+3), eleven (8+3), or nineteen (16+3) disks.
Я не совсем понял из него. А что я не могу сделать RAIDZ2 скажем на 8 дисках (6+2)? Или этот вариант возможен, но хуже по производительности или еще что?
Vladislav
Vladislav
Чтобы он нацело делился по степеням двойки
Ivan
Не совсем понял. Вот у меня 24 SAS диска, я хочу сделать пул из трех raidz2 (6+2)
Ivan
Я что не могу это делать?
Ivan
или можно, но не желательно
Vladislav
Vladislav
или можно, но не желательно
Окей, в чем суть, мне может изменять память, но как я помню
Есть Stripes Size, это блок, который в итоге будет писаться на рейд (в ZFS это recordsize), это наименьшая единица, которая будет использовать ZFS для чтения данных и из записи на датасет
Вы пишите файл размером 4МБ
С recordsize=64К на 1 массив 6d+2p
ZFS получает от Вас этот файл и разбивает его на куски по 64К (потому что record size это для датасета параметр)
И каждый кусок затем делит на количество data дисков (потому что ему же надо записать только кусочек на каждый диск.
Если у Вас 6+2, то 64/6 никак не поделить, поэтому необходимо добивать последний кусок нулями, чтобы он комфортно лег на диски
Vladislav
Окей, в чем суть, мне может изменять память, но как я помню
Есть Stripes Size, это блок, который в итоге будет писаться на рейд (в ZFS это recordsize), это наименьшая единица, которая будет использовать ZFS для чтения данных и из записи на датасет
Вы пишите файл размером 4МБ
С recordsize=64К на 1 массив 6d+2p
ZFS получает от Вас этот файл и разбивает его на куски по 64К (потому что record size это для датасета параметр)
И каждый кусок затем делит на количество data дисков (потому что ему же надо записать только кусочек на каждый диск.
Если у Вас 6+2, то 64/6 никак не поделить, поэтому необходимо добивать последний кусок нулями, чтобы он комфортно лег на диски
Теперь рассмотрим массив 8d+2p
64К/8 = 8К
На каждый диск отправится кусок данных по 8К (дальше это уже бьётся на ashift куски, потом уже на размер блока самого диска)
Отсюда и рекомендация про диски по степени двойки
Ivan
Аааа, понял
Ivan
Спасибо большое
 Georg🎞️🎥
Georg🎞️🎥
 Nick
Nick
Чтобы он нацело делился по степеням двойки
этот подход был популярен и уже давно известно что является неверным
Nick
Коллеги, наткнулся на такой момент в archwiki
Summarizing Toponce's guidance:
RAIDZ2 should use four (2+2), six (4+2), ten (8+2), or eighteen (16+2) disks.
RAIDZ3 should use five (2+3), seven (4+3), eleven (8+3), or nineteen (16+3) disks.
Я не совсем понял из него. А что я не могу сделать RAIDZ2 скажем на 8 дисках (6+2)? Или этот вариант возможен, но хуже по производительности или еще что?
можете. процент потери полезного объема можно посмотреть в табличке https://openzfs.github.io/openzfs-docs/Basic%20Concepts/RAIDZ.html
Nick
(внизу страницы)
Nick
но это в идеальном случае на больших файлах, на мелких файлах все чуть иначе
Vladislav
этот подход был популярен и уже давно известно что является неверным
Мммм, так в таблице аналогичное приводится судя по описанию?
Мол, при несовпадении data дисков+recordsize у вас появляется padding
Nick
нет.
в ряде ситуаций определенное сочетание количества дисков неэффективно по проценту полезного места, но вполне оправдано потому что увеличивает суммарный объем
Nick
Мммм, так в таблице аналогичное приводится судя по описанию?
Мол, при несовпадении data дисков+recordsize у вас появляется padding
а я кстати не уверен что паддинг блок будет. Его, кажется, как раз нет
Nick
@gmelikov актуален ли текст по ссылке про паддинг?
некоторая вещь суть паддинг ведь только в draid, а в raidz* маленькие данные меньше чем ашифт занимают ашифт плюс на других дисках столько ашифтов, сколько raidz
Vladislav
Так, пункт первый интересный:
stripe width in RAIDZ is dynamic, and starts with at least one data block part, or up to disks count minus parity number parts of data block
То есть при записи файла размером меньше, чем recordsize у нас не будет 1 диск с файлом и 5 с 0.
А будет играться от ashift
Nick
если ашифт условно 4к, а файл условно 300 байт то будет использован один кусок в 4к на одном диске и на двух дисках под контроль четности/восстановление
Vladislav
For example, for raidz1 of 3 disks with ashift=12 and recordsize=4K we will allocate on disk:
one 4K block of data
one 4K padding block
Nick
и если это raidz1 на 50 дисков, то на этот файлик будет потрачено только 3 куска по ашифт на 3х разных дисках
Vladislav
То есть мы все равно получим 4k padding
Nick
на сколько я понимаю - в этом случае как раз никакого паддинга нет
Vladislav
ashift=12 and recordsize=128K for raidz1 of 3 disks:
total stripe width is 3
one stripe can have up to 2 data parts of 4K size because of 1 parity blocks
we will have 128K/2 = 64 stripes with 8K of data and 4K of parity each
Vladislav
на сколько я понимаю - в этом случае как раз никакого паддинга нет
Буквально написано, что он есть
Vladislav
For example, for raidz1 of 3 disks with ashift=12 and recordsize=4K we will allocate on disk:
one 4K block of data
one 4K padding block
For example, for raidz1 of 3 disks with ashift=12 and recordsize=4K we will allocate on disk:
one 4K block of data
one 4K padding block
Vladislav
ashift=12 and recordsize=128K for raidz1 of 3 disks:
total stripe width is 3
one stripe can have up to 2 data parts of 4K size because of 1 parity blocks
we will have 128K/2 = 64 stripes with 8K of data and 4K of parity each
Вот паддинга не будет, но это случай не 3+1, а 2+1, поэтому все ровно ложиться
Vladislav
Я не могу понять как читать таблицу, если меня интересует как ведёт себя record size с 4 дисками и блоком 4к
Полагаю нижняя часть про него
 George
George
@gmelikov актуален ли текст по ссылке про паддинг?
некоторая вещь суть паддинг ведь только в draid, а в raidz* маленькие данные меньше чем ашифт занимают ашифт плюс на других дисках столько ашифтов, сколько raidz
padding есть в обоих, в draid fixed stripewidth, а в raidz он не фиксированный
George
я когда писал, несколько раз перепроверял себя) если кто косяк найдёт - говорите, буду рад поправить
Fedor
кстати в dev уже есть block3 как checksum, никто не пробовал, он действительно быстрей fletcher4?
George
кстати в dev уже есть block3 как checksum, никто не пробовал, он действительно быстрей fletcher4?
емнип быстрее флетчера ничего нет до сих пор
Vladislav
на сколько я понимаю - в этом случае как раз никакого паддинга нет
Согласно нижней таблице - при 4 дисках в рейде и размере record size в 32К у нас будет 27% потерь
То есть 32КБ (32768 б) мы пишем на 3 диска, это не делится ровно
10922.(66)байт.
Если у нас ashift 12 (4k - 4096), то это 8 блоков
То мы записали 3 на первый диск, 3 на второй, 2 на третий и паддингом ещё один надо забить ещё 1 на третьим диске. Это даёт нам 12% потерь +25% от parity
Я не понимаю почему 27%
George
емнип быстрее флетчера ничего нет до сих пор
```
cat /proc/spl/kstat/zfs/fletcher_4_bench
0 0 0x01 -1 0 7158528941 27766906031758
implementation native byteswap
scalar 9231458636 8848257268
superscalar 13232923107 11773429831
superscalar4 14042072947 11179921314
sse2 20151495205 11128219958
ssse3 20355501459 19231175538
avx2 39453374270 35709947942
fastest avx2 avx2
```
против https://github.com/openzfs/zfs/pull/12918
```
implementation 1k 4k 16k 64k 256k 1m 4m
edonr-generic 1196 1602 1761 1749 1762 1759 1751
skein-generic 546 591 608 615 619 612 616
sha256-generic 240 300 316 314 304 285 276
sha512-generic 353 441 467 476 472 467 426
blake3-generic 308 313 313 313 312 313 312
blake3-sse2 402 1289 1423 1446 1432 1458 1413
blake3-sse41 427 1470 1625 1704 1679 1607 1629
blake3-avx2 428 1920 3095 3343 3356 3318 3204
blake3-avx512 473 2687 4905 5836 5844 5643 5374
```
George
они его похоже позиционируют как более быструю версию sha
да, наиболее быстрый из криптостойких
Ivan
Ребята, может кто подскажет куда смотреть. Собрал систему на 24 SAS дисках и там организовал пул на 4 vdev из raidz2 (4+2) каждый. При стандартной работе с сервером проблем нет, когда я не нагружаю массив. Но стоит мне начать писать на массив, через 5-10 секунд система виснет намертво, что даже IPMI отваливается.
Vladislav
Ребята, может кто подскажет куда смотреть. Собрал систему на 24 SAS дисках и там организовал пул на 4 vdev из raidz2 (4+2) каждый. При стандартной работе с сервером проблем нет, когда я не нагружаю массив. Но стоит мне начать писать на массив, через 5-10 секунд система виснет намертво, что даже IPMI отваливается.
Смотрите на cpu и память, возможно они битые, у меня такое было
Vladislav
Поставьте TrueNAS и мониторьте вывод экрана
Он перед смертью дебагами напишет
Ivan
А может быть такое, что температура дисков поднимается слишком сильно и система вырубается?
Ivan
Дело в том, что даже в простое температура дисков доходит до 50 градусов
Ivan
А если начать писать, то рискну предположить, что температура улетает сильно выше
 central
central
А может быть такое, что температура дисков поднимается слишком сильно и система вырубается?
У вас там есть короб герметичный?
Ivan
Не совсем понял какой короб и где?
Ivan
Есть корпус серверный в нем 24 диска подключенные через хот свап салазки
Ivan
Все фронтальное пространство корпуса занимают салазки с дисками, 24 шт
Ivan
Смотрите на cpu и память, возможно они битые, у меня такое было
А что в итоге оказалось в вашем случае?
Fedor
Дело в том, что даже в простое температура дисков доходит до 50 градусов
может, особенно если выше
Fedor
и начнёт сыпаться
Fedor
ещё питание надо смотреть
Ivan
А что питание? Там 2 БП с резервированием 2 по 900, если память не изменяет
Fedor
мало ли
Vladislav
Но я поменял и процы и память
Vladislav
Потому что там было ddr3 и v0
Alexandr
Всем привет , посоветуйте как быть есть zraid3 вылетело 2 диска , Как быть с заменой ? Можно ли менять на горячую
Alexandr
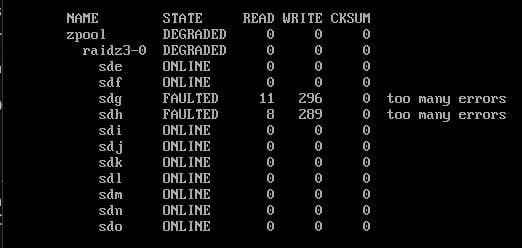 Vladislav
Vladislav
Можно и надо
Alexandr
прост прочел инфу что диски в офлайн затем тушить хост и менять диски
Ivan
прост прочел инфу что диски в офлайн затем тушить хост и менять диски
выключать сервер не нужно
Ivan
ну только если материнка/контроллер хотсвап не поддерживает, тогда нужно. но такое железо уже редкость.
Alexandr
понял спасибо
Alexandr
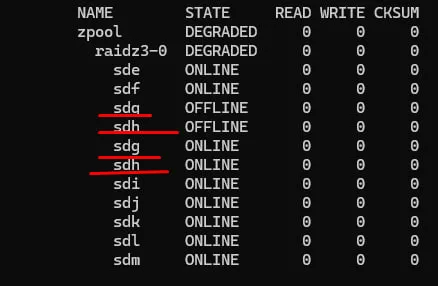 Vladislav
Alexandr
Vladislav
Alexandr
Т.е. сейчас просто переткнуть диски ?
Vladislav
Т.е. сейчас просто переткнуть диски ?
Сейчас уже ждите, я вообще не понял, что у Вас на скрине
Vladislav
У Вас sdh оказался внутри рейда как его часть
Vladislav
Вместо реплейса
Vladislav
Иными словами, если его вынуть у Вас все умрёт
Vladislav
Fedor
Иными словами, если его вынуть у Вас все умрёт
там разве не получилось переименования после ребута?
Nikita
А диски точно чистые были?