А это очень странное поведение. Потому что я гонял на 380-х прокс на zfs и на 420-м и у zfs не было шансов. В нвме не вижу смысла на вашем железе. Как и в л2арк, он бесполещен а иногда вреден имхо. Я бы лучше памяти докинул.
Вот именно - как по мне 420 должен быстрее быть, ну по крайней мере не хуже zfs. Железо всё протестировал, настройки контроллера перепроверил. По всякому пробовал - нет изменений. Мысли уже - подкинуть какой нить сата контроллер в качестве теста...
 Ivan
Ivan


 Georg🎞️🎥
Georg🎞️🎥
Сейчас 512 ГБ на сервер и по 128ГБ арк.
Я arc не ограничивал … так как он и 400 выжнет и мало будет в некоторых задачах
Autumn
Итого, слог какую производительность несёт ? Касаемо записи , судя по описанию 🤔🤷🏻♂️
Да записи. Не очень понял вопрос, Вас интересуют цифры или логика? Первое не помню, но я реальную схему описывал: zfs raidz2 + nfs. Там синхронная запись и там слог мастхэв был что бы сливать бэкапы с прокса. Логику долго описывать, будет простыня.
Georg🎞️🎥
Да записи. Не очень понял вопрос, Вас интересуют цифры или логика? Первое не помню, но я реальную схему описывал: zfs raidz2 + nfs. Там синхронная запись и там слог мастхэв был что бы сливать бэкапы с прокса. Логику долго описывать, будет простыня.
Не, логику не надо, я не пойму. А nfs шустрее smb ?🤔 получше ? Что скажите ?
Autumn
Я arc не ограничивал … так как он и 400 выжнет и мало будет в некоторых задачах
У меня гиперконвергент, поэтому под арк 128, останое виртуалки. Но я делал тесты, можно было и 64 ГБ под арк, в моем случае разницы не было.
Autumn
Не, логику не надо, я не пойму. А nfs шустрее smb ?🤔 получше ? Что скажите ?
https://www.servethehome.com/what-is-the-zfs-zil-slog-and-what-makes-a-good-one/ тут можно прочитать
Autumn
Не, логику не надо, я не пойму. А nfs шустрее smb ?🤔 получше ? Что скажите ?
Нет. Просто на nfs я сливал бэкапы с прокс кластера т.к. она нативная для линухов, а самбу то в никсы уже с винды втащили. Честно я никогда не использовал самбу в линухах кроме как файлопомойку для юзеров под виндой, но ntfs + smb 3 после появления в вин серваке 2012 давала обалденую производительность, и да эта связка была быстрее чем nfs over zfs. Я на ней держал vhdx под кластер гипер-в, до перехода на prox+zfs. Как себя samba over zfs показывает без понятия.
Autumn
Вот именно - как по мне 420 должен быстрее быть, ну по крайней мере не хуже zfs. Железо всё протестировал, настройки контроллера перепроверил. По всякому пробовал - нет изменений. Мысли уже - подкинуть какой нить сата контроллер в качестве теста...
Ну вот у меня был быстрее. Да и с вашей конфигурацией на два винта да 5 ссд, я бы при отсутсвии аппаратного рейда просто mdadm собрал. В принципе что обычно и делаю на дедиках по всяким хетцнерам, класстическая схема на мини клиента - 8 и выше ядер цп, 64-128гб рам, 2-4 ссд + 2-4 шпинделя собираю в mdadm под дебом потом превращаю в прокс. На ссд виртуалки клиентов, на винты холодные данные + бэкапы, а потом с винтов скриптом сливаю в бэкблейз. В такой схеме аппаратный рейд обычно дорог, когда клиент пытается на 200 баксов аренды за сервак в мес. экономить 10-15 баков рейда, а zfs избыточен и несет лишние накладные расходы но бонусов при отсутсвии доступа к железу дает мало.
Autumn
Вот именно - как по мне 420 должен быстрее быть, ну по крайней мере не хуже zfs. Железо всё протестировал, настройки контроллера перепроверил. По всякому пробовал - нет изменений. Мысли уже - подкинуть какой нить сата контроллер в качестве теста...
А рейд не "тюнили". Я бы не тюнил, сбросил бы все в дефолт, если сервак стендово-тестовый сейчас, то попробовал бы сделать 10-й рейд на 4-х ссд, зеркало на винтах, а одну ссдшку не трогат и проверить в такой конфе. Может хотспейр чудит. Ну и у 420-к фирмваря должна обновлятся, посмотрел бы может обновы есть решающие проблему какой-то логики.
Georg🎞️🎥
@autumn_river благодарю
Ivan
А рейд не "тюнили". Я бы не тюнил, сбросил бы все в дефолт, если сервак стендово-тестовый сейчас, то попробовал бы сделать 10-й рейд на 4-х ссд, зеркало на винтах, а одну ссдшку не трогат и проверить в такой конфе. Может хотспейр чудит. Ну и у 420-к фирмваря должна обновлятся, посмотрел бы может обновы есть решающие проблему какой-то логики.
Сбрасывал, но без "спары" нет. Не подумал. Фирварю сразу обновил до последней. Сегодня ночью попробую - спасибо за идею.
Autumn
@autumn_river благодарю
Да незачто, вообще же в опенсорсе да часто и в целом нет такого понятия лучше/хуже, все ситуативно. Так и zfs. Пока палкой не потыкать верный рецепт в разных ситуациях не найти. А чужой опыт это лишь направление для движения. Вон тут в чате кубвирта человека жаловаться на кубернетес пробило :) Ну бывает.
Autumn
 Δαρθ
Δαρθ
зачем так, когда можно
export DEBIAN_FRONTEND=noninteractive
yes | add-apt-repository ppa:jonathonf/zfs
apt update && apt install -y zfs-dkms zfsutils-linux
reboot
?
чото левьё какое-то, собрано хз кем и хз какой версии )
Δαρθ
btrfs в топку, если есть аппаратный рейд да еще на батарейке лучше его вместо zfs, если нет железного рейда, zfs raid 10
чойто фтопку-то? бтрфс в некоторых случаях быстрее zfs оказывается и манаджить ее (снапшоты всякие) удобнее чем зфс.
правда раид5/6 нельзя и очень грустно если образы vm на ней файлами складывать (zfs просто летает с zvolами)
Autumn
чойто фтопку-то? бтрфс в некоторых случаях быстрее zfs оказывается и манаджить ее (снапшоты всякие) удобнее чем зфс.
правда раид5/6 нельзя и очень грустно если образы vm на ней файлами складывать (zfs просто летает с zvolами)
Потому и в топку :) Не ну под таймшифт в свежей федоре норм систему снапшотить, но я уж лучше zfs предпочту.
Δαρθ
Δαρθ
я свои аргументы изложил
Autumn
почему?
Ну например потому что я не хочу использовать фс которую начали придумывать как zfs-альтернативу под линукс но за 10 лет не смогли доделать потому что там видители рейд5 может с потерей данных покрашится.
Autumn
Тут не вопрос в том что быстрее/медленнее, а в том что я слишком стар что бы по ночам еще и бутерфс воскрешать если что пойдет не так.
 Fedor
Fedor
Каждая фс может навернуться, но о бтрфс я слышал историй о потере данных больше в сравнении с другими фс.
Может ситуация и изменилась.
Ivan
Autumn
https://www.google.com/amp/s/habr.com/ru/amp/post/559014/
Autumn
Вот тут например по бутеру прошлись. Да и без этого я видел спонтанно сдохший бутер не раз. Может причина и была, но я ее не нашел, с zfs за все время ее эксплуатации таких чудес не было. Поэтому увы btrfs нишмагла, да думаю уже врядли сможет, куча времени потеряно.
Δαρθ
https://www.google.com/amp/s/habr.com/ru/amp/post/559014/
это не разраб бтрфс очевидно, а хейтер )
Autumn
это не разраб бтрфс очевидно, а хейтер )
а я не говорил что разраб бутера, это разраб новой rizerfs =) но он уж точно в теме понимает
Δαρθ
Вот тут например по бутеру прошлись. Да и без этого я видел спонтанно сдохший бутер не раз. Может причина и была, но я ее не нашел, с zfs за все время ее эксплуатации таких чудес не было. Поэтому увы btrfs нишмагла, да думаю уже врядли сможет, куча времени потеряно.
ну можно еще долго перечислять что zfs нишмагла
Δαρθ
Δαρθ
ну мне честно пофиг его упражнения, я говорю из своего опыта эксплуатации того и другого
Autumn
ну мне честно пофиг его упражнения, я говорю из своего опыта эксплуатации того и другого
и я Ваш опыт коллега уважаю, но мой говорит - чур ее эту бтрфс, чур =)
Autumn
Тут же еще надо учитывать момент, что я сам себе злобный буратино и что в голову стукнет то и буду крутить, может завтра на серваки буду раскатывать федора-сервер на бутере и пусть весь мир подождет, но когда кто-то спрашивает совет, а я осмеливаюсь его дать, то всегда стараюсь дать 100% железобетонное повторяемое и максимально предсказуемое решение, а злобным буратином человек себя всегда сам может сделать =)
Δαρθ
https://www.google.com/amp/s/habr.com/ru/amp/post/559014/
краткое содержание:
бтрфс - говно
зфс - говно
ехт4 - говно
хфс - говно
торвальдс - злобный чудак и не берет рейзер4 в ядро
и вообще все тупые и программировать не умеют, один я в белом пальто красивый и все запатентовал
Autumn
краткое содержание:
бтрфс - говно
зфс - говно
ехт4 - говно
хфс - говно
торвальдс - злобный чудак и не берет рейзер4 в ядро
и вообще все тупые и программировать не умеют, один я в белом пальто красивый и все запатентовал
ага, есть такое =), ну ко всему надо критично подходить, нарциссизм такая себе штука
 George
George
краткое содержание:
бтрфс - говно
зфс - говно
ехт4 - говно
хфс - говно
торвальдс - злобный чудак и не берет рейзер4 в ядро
и вообще все тупые и программировать не умеют, один я в белом пальто красивый и все запатентовал
это интервью к тому же и старое, там в комментах прошлись
George
но в идеи Шишкина я так до конца и не въехал, какие-то мысли на уровне домашней файлопомойки где по диску добивать можно и тд, из того что я увидел
 Vladislav
nikolay
Vladislav
nikolay
но в идеи Шишкина я так до конца и не въехал, какие-то мысли на уровне домашней файлопомойки где по диску добивать можно и тд, из того что я увидел
так идей нет, он пишет что надо брать лучшее от сетевых фс и применять на уровне докальных. а потом говорит - нафиг усложнять, все и так работает)
George
так идей нет, он пишет что надо брать лучшее от сетевых фс и применять на уровне докальных. а потом говорит - нафиг усложнять, все и так работает)
я про reiser5 https://www.opennet.ru/opennews/art.shtml?num=52121
он с одной стороны хочет менеджер томов (что я понимаю), с другой стороны "Возможно просто и эффективно скомпоновать логический том из блочных устройств, разных по размеру и пропускающей способности." , что звучит как чисто кейс собрать stipe голый
Vladislav
я про reiser5 https://www.opennet.ru/opennews/art.shtml?num=52121
он с одной стороны хочет менеджер томов (что я понимаю), с другой стороны "Возможно просто и эффективно скомпоновать логический том из блочных устройств, разных по размеру и пропускающей способности." , что звучит как чисто кейс собрать stipe голый
"Возможно просто и эффективно скомпоновать логический том из блочных устройств, разных по размеру и пропускающей способности."
Если его потом можно расширять с перестройкой страйпа на все новые диски, а не просто линейно их друг за другом крепить, то это годно
George
"Возможно просто и эффективно скомпоновать логический том из блочных устройств, разных по размеру и пропускающей способности."
Если его потом можно расширять с перестройкой страйпа на все новые диски, а не просто линейно их друг за другом крепить, то это годно
ну размазывать нагрузку по страйпам все менеджеры томов умеют, ставить на это ставку - не понимаю
George
обычно всё же не страйпами пользуются, а чем-то с избыточностью
George
и не равномерные страйпы не любят по причине неравномерной нагрузки
George
как бы в О(1) не аллоцировать, разные размеры дисков не дадут утилизировать их одинаково
Vladislav
и не равномерные страйпы не любят по причине неравномерной нагрузки
Как минимум - пока не закончится место на самом маленьком диске - вполне себе будет равномерно
George
Как минимум - пока не закончится место на самом маленьком диске - вполне себе будет равномерно
отлично, оно кончилось, что дальше?
Vladislav
Второй вариант, это блок который не равномерно бьётся на количество дисков не дополнять нулями, записывать в диски которые больше
George
тот же zfs чаще всего за неравномерную производительность ругают
George
система, которая деградирует без возможности построить ожидания - боль в эксплуатации
Vladislav
отлично, оно кончилось, что дальше?
А дальше мой выбор получать меньшую скорость на новые данные, пока я не расширюсь
Vladislav
система, которая деградирует без возможности построить ожидания - боль в эксплуатации
Система с 0 рейдом уже звучит болью
George
А дальше мой выбор получать меньшую скорость на новые данные, пока я не расширюсь
ну этот кейс я только в домашнем использовании видел
Vladislav
ну этот кейс я только в домашнем использовании видел
Я бы сказал "не критические данные"
George
Я бы сказал "не критические данные"
не, в промышленном использовании это нафиг не нужно, и стоит сразу учить приложение работать с разными дисками
George
я просто не понимаю мотивации разработки ФС, которая покрывает только кейсы НЕ промышленного использования. Такие решения банально уже есть
Vladislav
я просто не понимаю мотивации разработки ФС, которая покрывает только кейсы НЕ промышленного использования. Такие решения банально уже есть
М? У меня довольно много головной боли было с тем, чтобы запихнуть 960гб, 1ТБ, 1.1ТБ, 1.92 ссд диски в один массив
George
М? У меня довольно много головной боли было с тем, чтобы запихнуть 960гб, 1ТБ, 1.1ТБ, 1.92 ссд диски в один массив
ну вопрос как раз в мотивации.
в один массив без избыточности на раз два делается. С избыточностью тоже можно, чуть погеморроившись с разделами, если очень хочется
Vladislav
George
vmware виртуалки подключённые по 40г rdma линку
ну с резервированием легко докидывается по 2 диска в виде миррора, на примере тоже же zfs vdev, размер не важен
Vladislav
Проблема в расширении
mdadm работает через конвертацию в raid4
lvm raid0 сам нарезает диски по самому маленькому, т.е. в этом примере:
960гб, 1ТБ, 1.1ТБ, 1.92
У меня просто было 4 элемента по 960ГБ
ZFS и NVMe не работают ещё
btrfs.... не тестил
s3 - не вариант
Других вариантов я не находил
Vladislav
ну с резервированием легко докидывается по 2 диска в виде миррора, на примере тоже же zfs vdev, размер не важен
У меня не бесконечный бюджет :))))))
George
> ZFS и NVMe не работают ещё
так работают, вопрос в перформансе, и любой raid0 на nvme будет медленнее чем использование каждого диска отдельно
Vladislav
> ZFS и NVMe не работают ещё
так работают, вопрос в перформансе, и любой raid0 на nvme будет медленнее чем использование каждого диска отдельно
Ммммм, я получил свои 20 ГиБ/с (локально) на чтение и 7 ГиБ/с на запись с 8 дисков nvme и в целом всем доволен
5% потеря и 60% потеря это разница довольно существенная
 Arseniy
Arseniy
я просто не понимаю мотивации разработки ФС, которая покрывает только кейсы НЕ промышленного использования. Такие решения банально уже есть
Тут вопрос, возможно, больше не в фс, а в способе организации? Вот, скажем, я пощупал Unraid. Вполне сносная штука, крути себе диски разного размера, главное чтоб парити был наибольшим) слышал, люди и в офисах с количеством пользователей меньше 100 используют анрейд. Он прост в эксплуатации
Dmitrii
Добрый вечер
Вопрос
Можно ли как то заставить ZFS перераспределить данные на новый диск при добавлении в RaidZ2 нового диска? через zfs attach или zfs add
и ещё - адекватно ли делать каждый диск - отдельный vdev ?
George
Добрый вечер
Вопрос
Можно ли как то заставить ZFS перераспределить данные на новый диск при добавлении в RaidZ2 нового диска? через zfs attach или zfs add
и ещё - адекватно ли делать каждый диск - отдельный vdev ?
- только перезаписью данных
- каждый диск = отдельный vdev это получится stripe без резервирования, а не raidz2
Dmitrii
- только перезаписью данных
- каждый диск = отдельный vdev это получится stripe без резервирования, а не raidz2
получается если хочется raidz2 то сразу делать один массив
и больше не добавлять диски
George
получается если хочется raidz2 то сразу делать один массив
и больше не добавлять диски
да, пока в raidz vdev нельзя по одному диску добавлять, патч ещё в разработке
George
только новый raidz vdev
Dmitrii
да, пока в raidz vdev нельзя по одному диску добавлять, патч ещё в разработке
надеюсь там будет перераспределение данных как при аппаратном Рейде =)
George
надеюсь там будет перераспределение данных как при аппаратном Рейде =)
нет, это другой функционал, им пока никто не занимается, сложно
George
но при перезаписи данные отбалансируются
Dmitrii
нет, это другой функционал, им пока никто не занимается, сложно
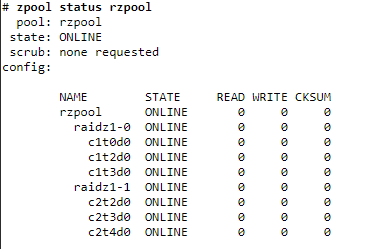 Georg🎞️🎥
Georg🎞️🎥
А все еще нет ничего похожего на дефрагментацию ? ))) типа нажал - пару дней пул погудел и «дырки» ушли )))