https://github.com/openzfs/zfs/releases/tag/zfs-2.1.7
получается, 6.1 который лтс будет -- мимо?
 Δαρθ
Δαρθ


 Vladislav
Vladislav
https://www.phoronix.com/news/Linux-5.14-File-Systems
Интересно откуда такая разница с f2fs на 4к
Vladislav
Там особенность fs, она пишет блоками по 1 мб
Так ПО возращается факт записи сразу, она же кэширует их в буфере
 Anonymous
Anonymous
Так ПО возращается факт записи сразу, она же кэширует их в буфере
Маскирует как то, она говорит что блоки 4к записаны, но на самом деле не записаны, пока их не наберется какое то количество
Vladislav
Маскирует как то, она говорит что блоки 4к записаны, но на самом деле не записаны, пока их не наберется какое то количество
Да, поэтому и вопрос, почему fio показывает такие маленькие цифры
Anonymous
Anonymous
Раздел 3.3.2
Vladislav
Да, поэтому и вопрос, почему fio показывает такие маленькие цифры
Когда по факту это запись в оперативную память
 Okhsunrog
Okhsunrog
 Vladislav
Vladislav
наоборот, вы апгрейднули пул
Vladislav
надо было версию zfs обновить, перегрузить, а потом апгредить пул
Vladislav
т.е. сейчас грузиться в риск, обновлять ZFS и молиться, чтоб при следующем старте пул импортнулся
Okhsunrog
наоборот, вы апгрейднули пул
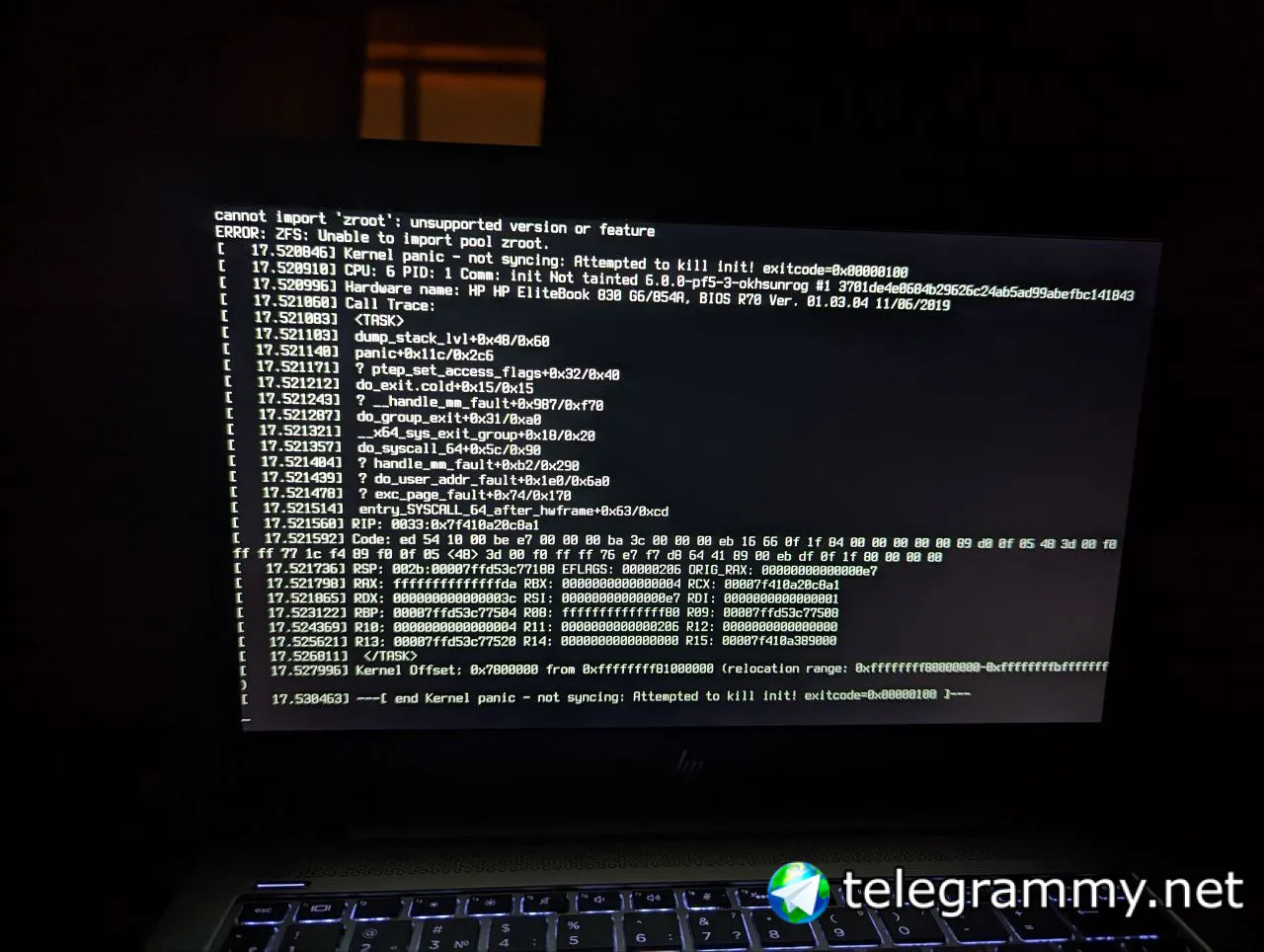
Я не апгрейдил его. Лишь пересобрал ядро с zfs 2.1.7 и zfs utils 2.1.7 поставил.
После перезагрузки увидел это
Vladislav
Я не апгрейдил его. Лишь пересобрал ядро с zfs 2.1.7 и zfs utils 2.1.7 поставил.
После перезагрузки увидел это
Ну, так прочтите первые две строки.
Okhsunrog
 Okhsunrog
Okhsunrog
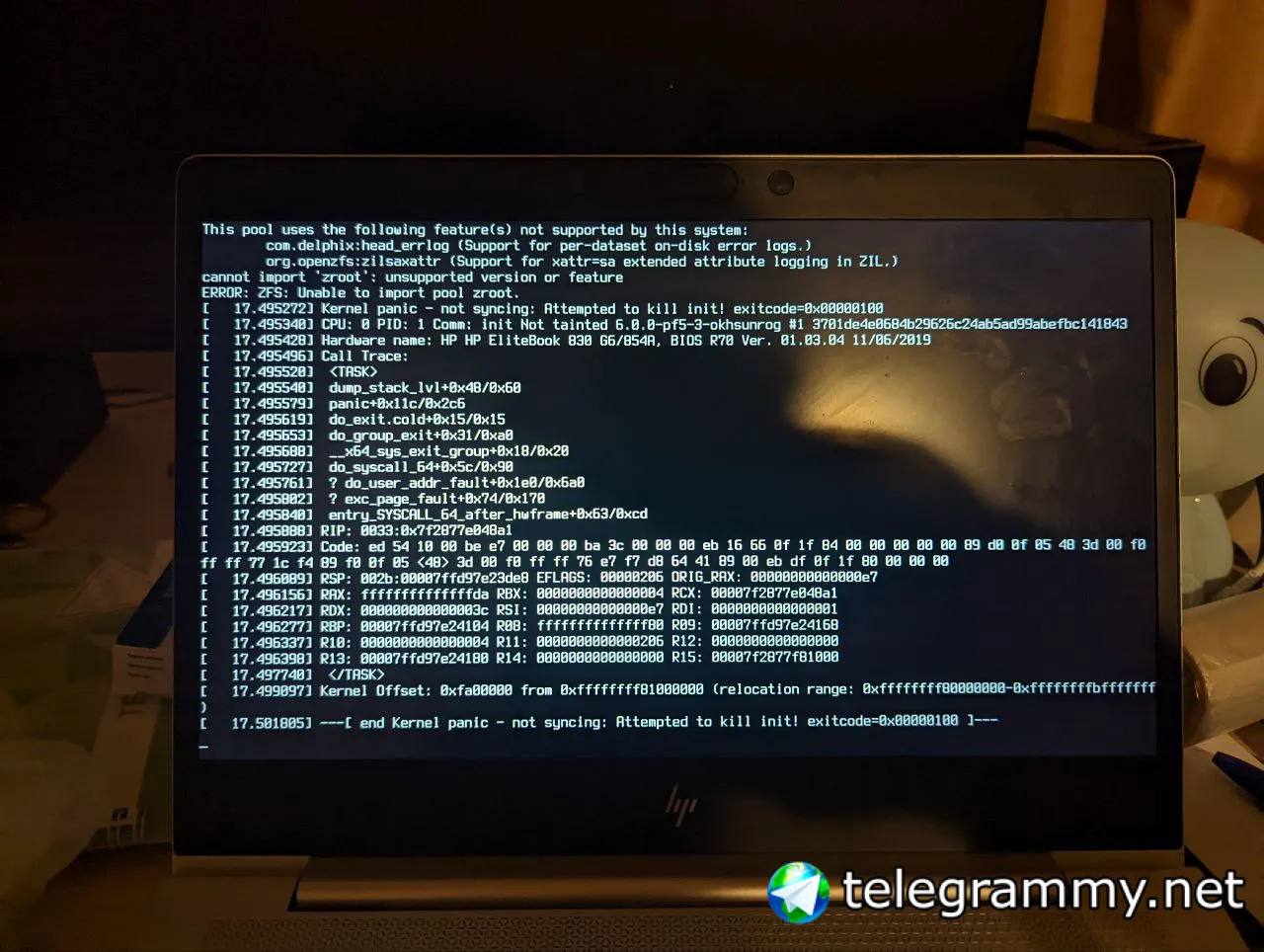
Подсказка. Тестируйте обновления в виртуалке.
Спасибо, на будущее буду знать.
Смог загрузиться с клона, потом сделал rollback основного рутового датасета и восстановил старую версию ядра в /efi
Сейчас буду разбираться, что у меня пошло не так...
Animal
Зачем апгрейдить пул если на то нет серьезных причин? Кроме как если в новой версии есть какие исправления критических косяков или есть новые фишки или функции которыми вы точно будете пользоваться?
 Arseniy
Arseniy
Кто нибудь в курсе, ProxMox получает обновления zfs с какой скоростью? В плане, они там что то тестируют, прежде чем обнову вставить, или она сразу прилетает?
 Сергей
Сергей
Кто нибудь в курсе, ProxMox получает обновления zfs с какой скоростью? В плане, они там что то тестируют, прежде чем обнову вставить, или она сразу прилетает?
у народа в соседнем чатике прокса сам прокс после обновлений не всегда запускается))) да. тестируют 😃 но это все не точно
Ivan
у народа в соседнем чатике прокса сам прокс после обновлений не всегда запускается))) да. тестируют 😃 но это все не точно
в 99% случаев ломается от кривых рук.
 George
George
Кто нибудь в курсе, ProxMox получает обновления zfs с какой скоростью? В плане, они там что то тестируют, прежде чем обнову вставить, или она сразу прилетает?
Бесплатная версия прокса как бы на тестовые их репы указывает, если что. Не, у них есть ещё совсем bleeding edge репа, но помнить стоит. Но они стабильный код zfs юзают, не из мастер ветки
Lone
Бесплатный ProxMox ломается при апдейте время от времени, так что тестируйте на своем железе. Или покупайте платную версию. У меня лично ломался, правда, через пару недель они пофиксили.
 Владимир
Владимир
Всем привет, кто подскажет как расширить zpool если раздел который был добавлен как vdev был увеличен, как заставить перечитать новый размер?
 Алексей
Алексей
Автоэкспанд должен быть включен до создания/импорта пула
 Egor
Egor
Всем привет, кто подскажет как расширить zpool если раздел который был добавлен как vdev был увеличен, как заставить перечитать новый размер?
На FreeBSD примерно так:
gpart recover da0
gpart resize -i 3 da0
zpool online -e zroot da0p3
Egor
На линухе думаю почти так же, разница только в способе расширения раздела на котором zfs пул лежит
Владимир
В общем всё получилось), спасибо)
Владимир
хелп у зфс конечно слабоинформативный)
Vladislav
 Vladislav
Vladislav
Утро начинается не с кофе
Vladislav
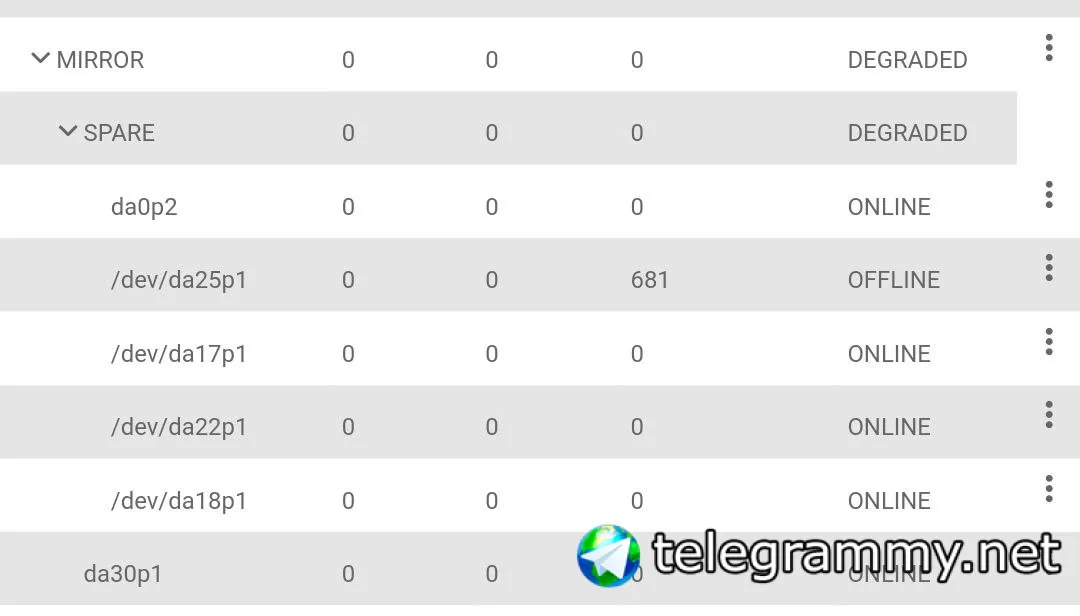
30 дисков WD black
Сперва умер один из дисков в зеркале (диск X)
Ему на смену из HS пришёл диск, который с 681 ошибок по чексуммам
Я принудительно сделал replace диск X на сторонний диск, который был не в пуле (da0)
После resilvering ничего не поменялось и da25p1 продолжил висеть со статусом Degraded
Я сделал da25 Offline и после этого ВСЕ hot-spare решили, что ВРЕМЯ ПРИШЛО
Ладно бэкап есть пятничный, а то было бы ссыкотно мальца
 Shaker
Shaker
Не используйте изначально плохие диски )
Shaker
Только если можно сразу смириться с риском потерять все данные
Vladislav
Не используйте изначально плохие диски )
))))))
Начальство увидев стоимость новых дисков сказало - эти диски 2014 года, которые нам отдала другая конторка))))
Shaker
У меня есть другой вопрос. Никто не интересовался, или может знает про частичное копирование снапшотов в zfs ? У клиента при копировании первого снапшота перегревается hba. Размер снимка 470Tb. К серверу клиента нет доступа ни у клиента, ни у нас. Канал 1гбит. Размер файлов 8К-30M, rsync через gnu parallel уже работает. Но кажется, есть другой вариант )
 Evgenii
Evgenii
У меня есть другой вопрос. Никто не интересовался, или может знает про частичное копирование снапшотов в zfs ? У клиента при копировании первого снапшота перегревается hba. Размер снимка 470Tb. К серверу клиента нет доступа ни у клиента, ни у нас. Канал 1гбит. Размер файлов 8К-30M, rsync через gnu parallel уже работает. Но кажется, есть другой вариант )
такое возможно. Реализовано в ZFS, при копировании снимка нужно добавить особый ключ, тогда в целевой датасет запишется особое свойство, с ключом по которому можно продолжить прерванное копирование.
Shaker
О, это интересно. Не нашли.
Evgenii
Популярное средство по репликации снимков syncoid умеет работать с этой фишкой
Сергей
О, это интересно. Не нашли.
-s вроде. после прерывания на стороне получаетля получаешь токен возврата, и в новую команду добавляешь в send -i -t и токен
Evgenii
О, это интересно. Не нашли.
https://openzfs.github.io/openzfs-docs/man/8/zfs-recv.8.html
-s
If the receive is interrupted, save the partially received state, rather than deleting it. Interruption may be due to premature termination of the stream (e.g. due to network failure or failure of the remote system if the stream is being read over a network connection), a checksum error in the stream, termination of the zfs receive process, or unclean shutdown of the system.
The receive can be resumed with a stream generated by zfs send -t token, where the token is the value of the receive_resume_token property of the filesystem or volume which is received into.
To use this flag, the storage pool must have the extensible_dataset feature enabled. See zpool-features(7) for details on ZFS feature flags.
Shaker
https://unix.stackexchange.com/questions/343675/zfs-on-linux-send-receive-resume-on-poor-bad-ssh-connection
Shaker
Да тут есть пример
Shaker
Да, конечно, остается верить в консистентность данных
Сергей
но тут тоже бывают приколы. пару раз ловил, что при попытке докопирования он пишет что пул занят, хотя ничего не происходит. и лечилось только через детач атач пула на стороне приемнике
Shaker
наверное scrub выявит, если что-то не так )
Сергей
Да, конечно, остается верить в консистентность данных
консистентно. я после рсинком прогонял. несколько сотен миллионов файлов. все ок
Shaker
консистентно. я после рсинком прогонял. несколько сотен миллионов файлов. все ок
Ну, у нас тоже такой набор примерно, сотни милионов картинок и json
Shaker
Но на этом фоне конечно gnu parallel rsync все равно проигрывает конечно, нет ничего быстрее снапшотов.
Сергей
рсинком прогоните просто и все. еще момент, что после обрыва нельзя ничего менять в приемнике. иначе данные будут разные и придется заново копировать)
Сергей
Ну, у нас тоже такой набор примерно, сотни милионов картинок и json
через
zfs send -Lec temp/04@send | mbuffer -m 1G -p 60 | zfs recv -s -v my/04
вот эта конструкция даст максимальную скорость. если есть оперативки больше, то можно еще упростить жизнь
Shaker
рсинком прогоните просто и все. еще момент, что после обрыва нельзя ничего менять в приемнике. иначе данные будут разные и придется заново копировать)
Да, это понятно. Проходили со снапшотами обычными, пришлось rollback делать, чтобы вернуть на место
Shaker
Сергей
Но на этом фоне конечно gnu parallel rsync все равно проигрывает конечно, нет ничего быстрее снапшотов.
через интернет при гигабином канале, без урезаний, рсинк работает примерно в 3-5 раз медленнее, чем снэпшоты. 6 миллионов файлов, или где-то 2тб рсинком копируется где-то около полутора дней, через сенд в районе пол дня. при этом рсинк создает гораздо более жуткую нагрузку, чем буфер в памяти.
по времени могу немного врать, помню что разница была прямо катастрофическая. особенно когда рсинк падал и приходилось заново миллионы файлов перечитывать
Сергей
пока зфс метаданные этих файлов хранит в памяти или на ссд все хоть как-то. когда не хранит, ребилд списка файлов становится кошмаром наяву)
Shaker
через интернет при гигабином канале, без урезаний, рсинк работает примерно в 3-5 раз медленнее, чем снэпшоты. 6 миллионов файлов, или где-то 2тб рсинком копируется где-то около полутора дней, через сенд в районе пол дня. при этом рсинк создает гораздо более жуткую нагрузку, чем буфер в памяти.
по времени могу немного врать, помню что разница была прямо катастрофическая. особенно когда рсинк падал и приходилось заново миллионы файлов перечитывать
Да, все так и есть. Но чтобы файлы не пересчитвать ужн полно комбайнов которые сами делают листинг, сохраняют , распределят между рсинками и параллельно шлют ) Но все равно это медленнее. Да, find . -print занял больше недели ;)
Сергей
Да, все так и есть. Но чтобы файлы не пересчитвать ужн полно комбайнов которые сами делают листинг, сохраняют , распределят между рсинками и параллельно шлют ) Но все равно это медленнее. Да, find . -print занял больше недели ;)
это если файлы статичны) у меня список файлов уже на столько меняется к моменту их сбора, что следующий сбор занимает не сильно меньше времени. в сутки где-то +3-5млн файлов загружается и удаляется под 1 млн
Shaker
Работает, спс. Ну у нас проще, лишь бэкапы на zfs.
Shaker
это если файлы статичны) у меня список файлов уже на столько меняется к моменту их сбора, что следующий сбор занимает не сильно меньше времени. в сутки где-то +3-5млн файлов загружается и удаляется под 1 млн
Приичная должно быть нагрузка. На чем логи ? pmem ? optane ? Локально ?
Сергей
Приичная должно быть нагрузка. На чем логи ? pmem ? optane ? Локально ?
не. там мегабит 200 входящая постоянная и около 100 исходящая. логи на зеркале самых дешевых 120гб ssd дисках))) даже не на серверных
Δαρθ
У меня есть другой вопрос. Никто не интересовался, или может знает про частичное копирование снапшотов в zfs ? У клиента при копировании первого снапшота перегревается hba. Размер снимка 470Tb. К серверу клиента нет доступа ни у клиента, ни у нас. Канал 1гбит. Размер файлов 8К-30M, rsync через gnu parallel уже работает. Но кажется, есть другой вариант )
можно слать по пайпу через pv с ограничением скорости
Shaker
можно слать по пайпу через pv с ограничением скорости
Да, так и сделали первый раз. Как раз через pv. Но только опытным путем познается скорость при которой идет перегрев. Воссстановлние копирования через recv -s - наше спасение.
Δαρθ
еще вариант -- вентилятор приколхозить шоб дул на хреновую карту
Shaker
еще вариант -- вентилятор приколхозить шоб дул на хреновую карту
Доступа нет ни у кого. А так да, вариант. Тут как раз ситуация, что нужно поднимать емкость, свободного места меньше 1%, диск вылетел, в корзинах нет места, в сервере порты кончились, hba перегревается, а админы "ушли на фронт".
Vladislav
Animal
флеш рояль жеж
edo1
Захотелось странного 😁
А именно: добавить в raidz опцию минималаный размер страйпа, что-то вроде ashift.
Например, у нас есть raidz2 из 10 дисков, ashift=12, recodsize максимальный.
На raidz2 лежит 10тб больших файлов (больше гигабайта, скажем) и 1тб мелких (меньше 100кб, например).
Проблема в том, что мелкие файлы «размазываются» по всем дискам, что вызывает кратное увеличение количества требуемых операций ввода-вывода.
Например, файл на 32кб будет «размазан» по 8+2 дискам, соответственно чтение задействует 8 дисков из 10 (8 операций io). Если считать, что одиночный hdd умеет 100 iops, отдача с массива будет 1000 iops, итого всего 4мб/с на таких файлах.
Хочется же такие маленькие файлы хранить как один блок на 32к + 2 контрольных блока. Да, потребление дискового пространства заметно вырастет (96кб вместо 40кб), но и отдать наш массив сможет 32мб/с, в 8 раз больше!
Возможные альтернативы:
Использовать draid со схемой 3+2, например. И для маленьких файлов проблему не окончательно решит, и накладные расходы на крупные вырастут сильно.
Задрать ashift. В общем-то почти нужный результат, но больше потери, а на метаданных потери НАМНОГО больше, при использовании special будет больно.
Плотно код не смотрел ещё, но вроде бы текущая схема хранения вполне совместима, так что технических препятствий для реализации не должно быть.
Вопрос только в том имеет ли это изменение какие-то шансы на принятие в проект?
@gmelikov особенно к тебе вопрос )
nikolay
привет всем. я как всегда с необычной проблемой (или не проблемой в фичей, как посмотреть)Ж)
nikolay
есть 4 аппаратных сервера, собраны пулы zfs, raidz2 из 55 дисков + slog + special. вроде все работало, но в какой-то момент возникла странная ситуация.
nikolay
load average растет до 100-150 в моменте, %wa за 30 и выше, в топе два процесса
nikolay
1453 root 20 0 0 0 0 R 93.9 0.0 2556:26 arc_prune
1454 root 20 0 0 0 0 R 54.4 0.0 1371:25 arc_evict
nikolay
для zfs из 256 Гб выделено 128Гб, причем прописано явно
nikolay
# ARC 32GB min
options zfs zfs_arc_min=34359738368
# ARC 128GB max
options zfs zfs_arc_max=137438953472
edo1
А с памятью что?