не, прошёл бы.
Расскажи это админу развалившегося пула в нагруженном проде, где за нарушение SLA могут лишить премии или чего-нибудь похуже ...
 Alexander
Alexander


 Fedor
Fedor
Расскажи это админу развалившегося пула в нагруженном проде, где за нарушение SLA могут лишить премии или чего-нибудь похуже ...
Ну значит такое решение выбрал, что уж там. Сам виноват.
Fedor
Надо проверенное временем брать и прогонять тестами по всем циклам жизненного пути эмулируя отказы
Alexander
Ну значит такое решение выбрал, что уж там. Сам виноват.
У меня в проде кстати v0.6.x работал с ресилверингом понадежнее, чем v0.7.12
Один раз даже пришлось менять диск на ходу еще 22 июня 2015 года.
Fedor
Fedor
Ctrl+C на источнике "zfs send ..." - это наобум?
Репликация выглядит примерно так:
zfs send -I DS@S1 DS@S2 | pv | ssh host "zfs receive XXX"
Прерываю репликацию на источнике, на приемнике по прежнему висит сессия с receive, особенно если после потери связи (выключение интерфейса по таймеру например или выдергивание кабеля) или даже предположительно Ctrl+C на источнике.
Прибиваю на приемнике shell сессию с receive по kill -s 9, она вроде бы даже и невсегда прибивается.
Далее пытаюсь сделать ssh host "zfs rollback XXX@S1", вроде бы даже проходит.
Дальнейшие попытки репликации сообщают, что XXX занят.
Даже zpool export XXX_pool говорит, что пул занят, пишите в спортлото.
Как на хосте приемнике - host датасет XXX вернуть в исходное состояние, готовое к репликации с источником ?
ессно БЕЗ ребута.
If the sending process was interrupted and we ask ZFS to not clean up the data, we can’t send other data to the same dataset. Instead, we have to continue in the place interrupt occurred, or we have to abort it. Another option is to force send using ‘-F’ options which rollback all the changes, which basically means we will rollback all the send.
Alexander
Fedor
ну а чего ты тогда говорил, что ФС плохая и ничего потом не льётся?)
Fedor
если сможешь воспроизвести ситуацию - будет прекрасно.
Fedor
можно будет дальше поискать чего как это всё привести в нормальное состояние
Alexander
можно будет дальше поискать чего как это всё привести в нормальное состояние
Сначала почитаю доки про resume токены.
Fedor
продолжить наливание чаще быстрее, чем начинать с нуля
Fedor
я сенды не использую, так что большего у меня нет.
 George
George
была бага в 0.7 с бесконечным ресильвером. в самом последнем релизе (вроде 0.7.13) решили проблему
там zed косячил, решалось его отключением на ресильвер
Alexander
там zed косячил, решалось его отключением на ресильвер
Очень сомневаюсь, что бага была только в zed, я раньше вообще не ставил zed.
George
мб я что забыл по багам конечно, но 99% обращений решались советом "отключите zed"
Alexander
если сможешь воспроизвести ситуацию - будет прекрасно.
Воспроизвести я могу еще более интересную ситуацию, когда после копирования через dd образа пула на исправное устройство этот пул будет сыпать CRC ошибками и потом вероятно помрет через несколько дней скраба.
Разработчики мне написали, что такого не может быть, потому что не может быть :) и закрыли issue :(
Alexander
Интересно, опция receive -s по умолчанию отсутствует?
Т.е. если ее не указывать, то такой receive не поддерживает resume при обрыве? И соответственно не требует abort -A при попытке повторной репликации с начала?
https://www.reddit.com/r/zfs/comments/ay2q3a/cannot_receive_stream_with_or_without_resume/
Alexander
Демонстрация рулезности ZFS на примере вычитывания данных с медленно умирающих дисков:
https://ashish.blog/2020/04/resume-support-in-zfs-send/receive/
Как раз с опцией продолжения receive -s
Alexander
И баги тоже были по этой опции resume:
https://github.com/openzfs/zfs/issues/10439
Вот такой программный продукт, который нужно уметь правильно использовать (не по инструкции).
Ivan
Демонстрация рулезности ZFS на примере вычитывания данных с медленно умирающих дисков:
https://ashish.blog/2020/04/resume-support-in-zfs-send/receive/
Как раз с опцией продолжения receive -s
оно умеет определять и перепрыгивать побитые блоки, как ddrescue ?
Alexander
оно умеет определять и перепрыгивать побитые блоки, как ddrescue ?
Насколько я понял, в приведенном примере просто есть возможность перечитывать и постепенно продвигаться вперед с опцией resume.
При условии, что устройство все же в состоянии вычитать данные, пусть не с первого раза.
Кстати вроде бы есть другая опция и даже пропуска непрочитанных данных.
Ivan
Насколько я понял, в приведенном примере просто есть возможность перечитывать и постепенно продвигаться вперед с опцией resume.
При условии, что устройство все же в состоянии вычитать данные, пусть не с первого раза.
Кстати вроде бы есть другая опция и даже пропуска непрочитанных данных.
сомнительная польза для побитого диска
George
Воспроизвести я могу еще более интересную ситуацию, когда после копирования через dd образа пула на исправное устройство этот пул будет сыпать CRC ошибками и потом вероятно помрет через несколько дней скраба.
Разработчики мне написали, что такого не может быть, потому что не может быть :) и закрыли issue :(
на issue
Alexander
Воспроизвести я могу еще более интересную ситуацию, когда после копирования через dd образа пула на исправное устройство этот пул будет сыпать CRC ошибками и потом вероятно помрет через несколько дней скраба.
Разработчики мне написали, что такого не может быть, потому что не может быть :) и закрыли issue :(
на issue
Issue под анонимной учеткой, не хочу ее палить.
Можешь поиском по ключу ganstalking.
George
George
если пул экспортировали, то всё ок должно быть, только если при записи проблемы были на новый диск
George
но первый скраб это должен выявить
Alexander
но первый скраб это должен выявить
Скраб только увеличивает количество ошибок и вообще любые чтения аналогично. Ошибки вероятно в метаданных или вообще какие-то мнимые ошибки - может быть бага.
Копия пула у меня сохранилась, причем проблема не в пуле, а именно в содержимом dd образа vdev, при его выталкивании из пула проблема исчезает.
Но как я уже упоминал, этот образ этого проблемного vdev будет сыпать CRC и потом вообще помрет на любом вашем самом дорогом и надежном оборудовании.
George
Скраб только увеличивает количество ошибок и вообще любые чтения аналогично. Ошибки вероятно в метаданных или вообще какие-то мнимые ошибки - может быть бага.
Копия пула у меня сохранилась, причем проблема не в пуле, а именно в содержимом dd образа vdev, при его выталкивании из пула проблема исчезает.
Но как я уже упоминал, этот образ этого проблемного vdev будет сыпать CRC и потом вообще помрет на любом вашем самом дорогом и надежном оборудовании.
надо было сверить содержимое дисков после dd перед импортом первым
George
магии не бывает
George
просто "на моём ноутбуке работает" 😁
Alexander
надо было сверить содержимое дисков после dd перед импортом первым
Ну вот если этот образ скопирует кто угодно из этого чата на свои распрекрасные сверхнадежные устройства, то все повторится. Значит у всех участников этого чата неисправное оборудование?
George
Ну вот если этот образ скопирует кто угодно из этого чата на свои распрекрасные сверхнадежные устройства, то все повторится. Значит у всех участников этого чата неисправное оборудование?
повторюсь - надо сначала сверить соответствие образа оригиналу
Alexander
повторюсь - надо сначала сверить соответствие образа оригиналу
Так на оригинале были атаки по цепи питания во время появления этих ошибок. После перезагрузки пул импортировался вообще кое как принудительно.
George
Так на оригинале были атаки по цепи питания во время появления этих ошибок. После перезагрузки пул импортировался вообще кое как принудительно.
ну если оригинал битый то какие вопросы то
George
если оригинал работает, а копии сыпятся - в процессе копирования что-то пошло не так
Alexander
ну если оригинал битый то какие вопросы то
Битый конечно после атаки, но почему zpool scrub его не исправляет или хотя бы не пишет, что исправить не может?
Alexander
если оригинал работает, а копии сыпятся - в процессе копирования что-то пошло не так
Данные читались с пула, но постоянно сыпались CRC ошибки в zpool status без появления новых файлов в списке -v. Потом пул умирал примерно через неделю.
Количество ошибок могло достигать несколько десятков или сотен тысяч, потом пул все ...
Ivan
George
круто что данные то позволил zfs достать ещё при таких проблемах с оборудованием)
Alexander
круто что данные то позволил zfs достать ещё при таких проблемах с оборудованием)
Целую неделю еще можно было читать данные кроме нескольких файлов, которые писались как раз в момент того, про что уже хватит.
Такие файлы (или их часть), которые were being written в момент атаки, мгновенно попадали в список zpool status -v и новых файлов в этом списке потом не появлялось, несмотря на постепенное нарастание CRC ошибок даже на исправном оборудовании, защищенном от атак. Причем их состояние до последнего снэпшота включительно было вполне нормальным и вычитываемым.
Т.е. в качестве защитной меры против утери данных в таких сложных условиях можно считать частный zfs snapshot.
Время жизни пула после возникновнеия проблемы конечно зависело не от прошедших дней, а от количества вычитанных данных и порожденных от этого новых CRC ошибок в статусе и вероятно каких-то структурах данных в первую очередь конечно.
 Aleksandr
Aleksandr
Обновите прошивку на контроллере до последней, ловил такие ошибки
Дык вроде последние поставил, перепровею на всякий случай
 Aleksandr
Aleksandr
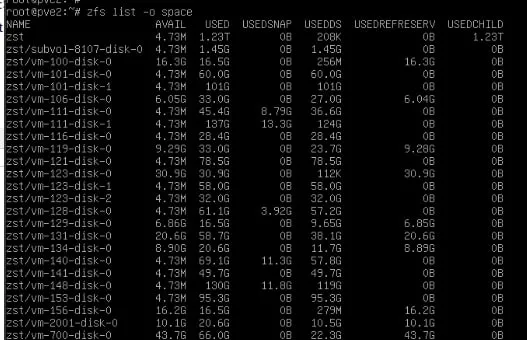
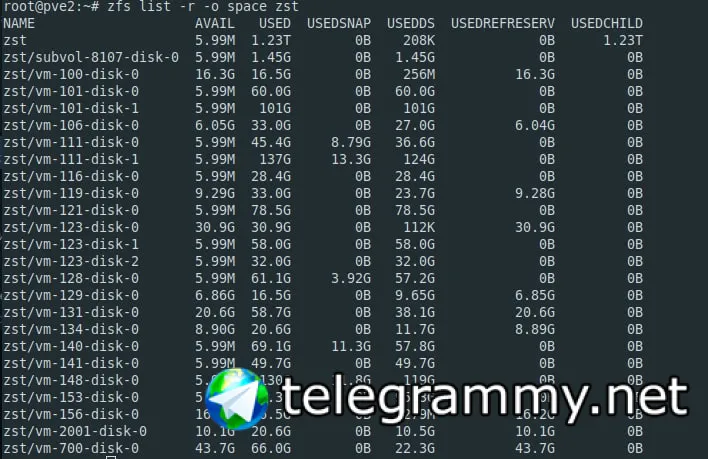
Всем привет. Беда такая, есть пул zst на нем лежит реально 340 гиг, но он говорит что занято 100% места. Удаление данных тоже не освобождает место...
Подскажет кто как дебажить?
Alexander
Всем привет. Беда такая, есть пул zst на нем лежит реально 340 гиг, но он говорит что занято 100% места. Удаление данных тоже не освобождает место...
Подскажет кто как дебажить?
Создавать новый пул, большего размера и переносить
Aleksandr
А почему так выходит что пул занят в 100% но самих данных там и на половину нет?
Aleksandr
 Ivan
Ivan
наверно thin надо включить
Aleksandr
 inqfen
inqfen
А почему так выходит что пул занят в 100% но самих данных там и на половину нет?
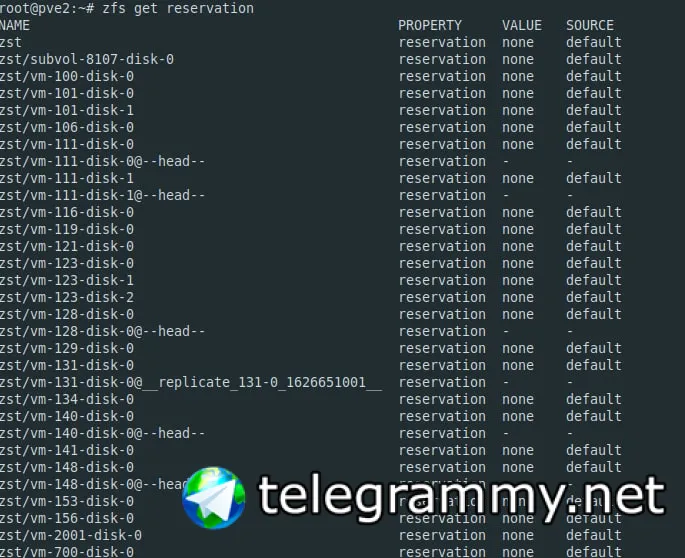
reservation наверное включен
Ivan
Вроде остается ждать. В свойствах диска вм еще желательно включить discard, если диски scsi и внутри вм включить fstrim timer.
inqfen
проверь на датасеты zfs get reservation
 inqfen
inqfen
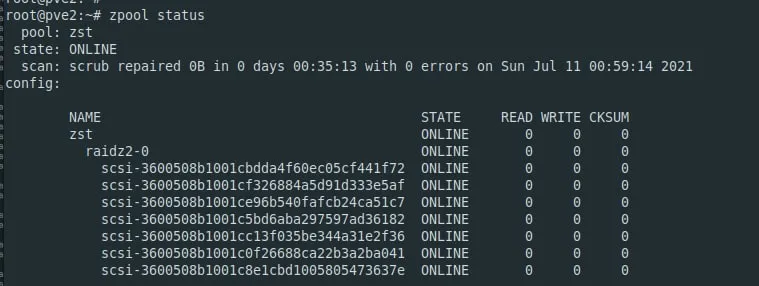
это не raidz?
 Aleksandr
Aleksandr
raidz
Alexander
А почему так выходит что пул занят в 100% но самих данных там и на половину нет?
Вероятно забит снэпшотами?
В таком случае удаление данных по rm только увеличивает потребление пространства, а уменьшает его:
zfs destroy xxx/yyy@zzz
inqfen
А какой ashift?
inqfen
Еще метадата может много жрат
inqfen
если ashift большой
Aleksandr
 inqfen
inqfen
12
Ну если recordsize небольшой, то метадата может немало сожрать при ashift12 - ее размер от блока zfs зависит
Aleksandr
Ну если recordsize небольшой, то метадата может немало сожрать при ashift12 - ее размер от блока zfs зависит
Есть одна виртуалко где много мелких записей, если е1 дропнуть попустить может?
Alexander
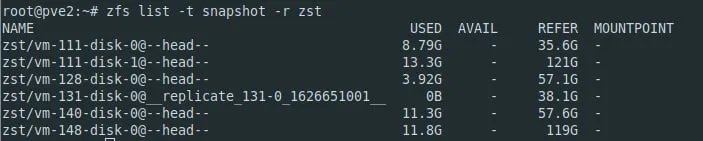 Aleksandr
Aleksandr
Удаляля виртуалки целые, место не освобождается
Alexander
Удаляля виртуалки целые, место не освобождается
Может быть, виртуалки "удаляются" только в GUI, а датасеты остаются? Какая-нибудь бага конфига и т.п.?
Aleksandr
inqfen
Удаляля виртуалки целые, место не освобождается
если виртуалки виндовые например и околопустые - то за счет дедупликации ты не удалишь в общем-то особо ничего
inqfen
Есть одна виртуалко где много мелких записей, если е1 дропнуть попустить может?
если связано с метадатой - да, должно
inqfen
где-то по интернетам есть формула расчета метадаты