zvol это же тот же файл? изначально sparse и фикс размера, ну и настройки/размеры блоков другие?
не совсем "просто файл", там есть приколы минимум с пробросом для ОС в виде блочника
 George
George


 Δαρθ
Δαρθ
ну проброс для ос это просто обертка же?
как mount -o loop например
 Alexander
Alexander
аля losetup?
Alexander
а ваще страшно, даже в ехт4 впилили дефраг, а тут...
Так даже в XFS и даже в СУБД причем онлайн.
Что-то они слишком уж самонадеянно разработчики заявляют, что дефрагментация для ZFS ненужна, ленятся просто.
Людмила Андреева has been banned! Reason: CAS ban.
 central
central
Так даже в XFS и даже в СУБД причем онлайн.
Что-то они слишком уж самонадеянно разработчики заявляют, что дефрагментация для ZFS ненужна, ленятся просто.
еще раз CoW фрагментирована by design ее не имеет смысла дефрагментировать, толку не будет
Alexander
еще раз CoW фрагментирована by design ее не имеет смысла дефрагментировать, толку не будет
Почему тогда есть толк после send | receive?
Alexander
И я не про 100% дефрагментацию, а хотя бы про снижение степени фрагментации в 2-3 раза от текущей.
Пусть бы даже для этого пришлось держать 2x девайсов, лишь бы вручную не перекидывать с одного пула на другой.
Трудно им сделать автоматический неспешный send | receive между пулом и его локальной копией по команде defrag?
Только чтобы все автоматом без создания вручную нового пула, без набора этих команд и т.п. А потом по завершению всех реплик автоматическое переключение на копию пула возможно с переключением всех кэширующих устройств со старого фрагментированного пула на новый более дефрагментированный (менее фрагментированный).
Допустим у старого пула была фрагментация 70%, а у нового получится 10-15%, - это огромный выигрыш по скорости работы.
Заодним это мог быть бы еще один уровень полной избыточности в случае постоянной online дефрагментации.
Т.е. появилась бы еще одна сущность типа defrag_pool, которая была бы логическим зеркалом оригинального фрагментированного пула.
Alexander
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
SWAP1 3.75G 2.88G 890M - - 68% 76% 1.00x ONLINE -
SWAP2 7.44G 5.05G 2.38G - - 83% 67% 1.00x ONLINE -
Alexander
Это к тому, что такие уровни фрагментации (68% и 83%) возможны практически, а не теоретически.
Только не надо троллить про SWAP, я не собираюсь его дефрагментировать ессно.
Δαρθ
еще раз CoW фрагментирована by design ее не имеет смысла дефрагментировать, толку не будет
для вращающихся винтов -- смысл есть
central
для вращающихся винтов -- смысл есть
только если zfs используется read only, иначе начинает работать CoW и все
Alexander
только если zfs используется read only, иначе начинает работать CoW и все
Если пишут только новые данные, а старые читают почти без изменений, то разве плохо иметь дефрагментированный пул? Старые данные большей частью не будут накапливать новой фрагментации из-за COW.
central
Alexander
ты вообще в курси как работают coy on write ФС?
Не на уровне разработчика ZFS, но в общих чертах знаю.
central
Не на уровне разработчика ZFS, но в общих чертах знаю.
ну тогда можешь ты уже скажешь почему уменьшать фрагментацию в CoW ФС не имеет смысла?
Alexander
то что тебе кажет zpool list это фрагментация свободного места
Является ли высокая фрагментация свободного места показателем высокой фрагментации занятого в последнее время места?
central
Является ли высокая фрагментация свободного места показателем высокой фрагментации занятого в последнее время места?
бл*ть, я заебался, надеюсь тут еще есть желающие выслушивать твои идеи
Δαρθ
только если zfs используется read only, иначе начинает работать CoW и все
не всегда. например софт делает fallocate() а потом пишет выровненными кусками по 1мб без перекрытия.
не знаю как зфс но например бтрфс в этом случае обходится без фрагментации
Alexander
ну тогда можешь ты уже скажешь почему уменьшать фрагментацию в CoW ФС не имеет смысла?
Я тебе из практики говорю даже без вникания в принципы работы, что после send | receive на другой чистый пустой пул, датасет читается намного быстрее, мне этого достаточно, чтобы иногда делать дефрагментацию, к сожалению сейчас это жутко неудобно через send | receive.
Alexander
бл*ть, я заебался, надеюсь тут еще есть желающие выслушивать твои идеи
Если свободное место сильно фрагментировано, то все последние и новые записи будут создавать сильно фрагментированные структуры данных для файлов? Вероятно более фрагментированные, чем на чистом пустом пуле по крайне мере, если в пул не было недавно добавления новых пустых девайсов? Или я ошибаюсь?
Неужели по твоему ZFS на чистом пустом пуле сама специально рандомно фрагментит данные даже при их первой (а НЕ повторной) записи?
Я не пытаюсь тебя переспорить, просто интересуюсь. Считай, что я вообще нихера не понимаю в фрагментации ZFS, обращаюсь к тебе как к эксперту по COW FS.
 Sergey
Sergey
Я тебе из практики говорю даже без вникания в принципы работы, что после send | receive на другой чистый пустой пул, датасет читается намного быстрее, мне этого достаточно, чтобы иногда делать дефрагментацию, к сожалению сейчас это жутко неудобно через send | receive.
Возьмем диски sas 8ТБ 7200.
Линейная скорость записи в начале диска примерно 210МБ/c
Линейная скорость записи в конце диска примерно 110МБ/c
По мере заполнения диска скорость падает в два раза.
Ясен пень что на новом пуле на новых дисках поначалу все быстрее будет...
Alexander
Возьмем диски sas 8ТБ 7200.
Линейная скорость записи в начале диска примерно 210МБ/c
Линейная скорость записи в конце диска примерно 110МБ/c
По мере заполнения диска скорость падает в два раза.
Ясен пень что на новом пуле на новых дисках поначалу все быстрее будет...
Так даже на SSD, и речь не о в 2 раза, а разнице на порядок на отдельных фрагментах данных.
110 и 210 Мбс - это линейные скорости для HDD, а при сильной фрагментации свободного места мы получим новые записи, которые читаться будут НЕлинейно, т.е. в сотни раз медленнее.
Alexander
Я же не спорю, что если в старые дефрагментированные данные что-то снова писать новое, то они опять станут фрагментированы из-за COW.
Речь о том, что бывают пулы в которые пишутся восновном новые данные, а старые изменяются редко. Например, документно-учетные базы данных архивного характера либо базы с топологиями для развертывания IaC имеют именно такой характер, не говоря уж о пулах с рабочими файлами, где меняется очень мало чего только в новых проектах.
Лично у меня почти все ZFS нагрузки именно такого характера и мне важен мой use case, а не абстрактное поведение COW ZFS на базе данных какого-нибудь Zabbix/Prometheus или ZoneMinder.
central
Желаю online дефрагментацию :)
ты же сам пишешь что тебе плевать на всех, интересует только твой кейс
central
так что ты ждешь от ZFS
Alexander
ты же сам пишешь что тебе плевать на всех, интересует только твой кейс
Я не писал, что мне плевать на всех, это ты придумал.
Я писал, что мне нужна дефрагментация для моего кейса.
От этого все пострадают, а я выиграю, наплевав на них по твоей версии?
 Василий
Василий
Желаю online дефрагментацию :)
Не будет. Они мелкофичи с глюками делают, а это очень сложный функционал
Alexander
Не будет. Они мелкофичи с глюками делают, а это очень сложный функционал
Жаль Sun не успела.
Alexander
Может Oracle осилит эту killer feature? Тогда ZOL останется только для бэкапчиков.
Василий
Жаль Sun не успела.
А сан пофиг. У них в серверах памяти чтобы горячие данные влезли вместе с дедупом
Alexander
А сан пофиг. У них в серверах памяти чтобы горячие данные влезли вместе с дедупом
С Oracle наверно таже история :(
Василий
сколько бреда про фрагментацию....
дефрагментация вполне себе полезная вещь, просто ков системы фрагментируются в разы быстрее обычных.
к сожалению, дефрагментация в современных системах есть только в нтфс (по крайней мере других не знаю) и то она там сильно кривая.
дефраг, по ночам, после бекапа, был бы топ фичей, но нет: большому бизнесу на это пофиг, там память, а мелкий утрется
Alexander
сколько бреда про фрагментацию....
дефрагментация вполне себе полезная вещь, просто ков системы фрагментируются в разы быстрее обычных.
к сожалению, дефрагментация в современных системах есть только в нтфс (по крайней мере других не знаю) и то она там сильно кривая.
дефраг, по ночам, после бекапа, был бы топ фичей, но нет: большому бизнесу на это пофиг, там память, а мелкий утрется
Дефрагментация есть даже в XFS, и в Db2 DBMS reorg online.
Василий
Дефрагментация есть даже в XFS, и в Db2 DBMS reorg online.
Дб2 это не фс, в классическом ее понимании. Про хфс не знал, надо посмотреть что там и как сделано. Если как в нтфс, дефраг с дырками, то жопа
Alexander
Дб2 это не фс, в классическом ее понимании. Про хфс не знал, надо посмотреть что там и как сделано. Если как в нтфс, дефраг с дырками, то жопа
Я про сложность, понятно, что СУБД - это не FS.
Василий
xfs
ext4
btrfs
А можно ссылку на тулзу по ext4? А то по поиск только фанатов: "нет и не нужна" нашёл
Δαρθ
А можно ссылку на тулзу по ext4? А то по поиск только фанатов: "нет и не нужна" нашёл
https://man7.org/linux/man-pages/man8/e4defrag.8.html
riv
Можно узнать, на что поменяли?
На linux. Мне нравится shorewall, на мой взгляд, рано или поздно, скрипты настраивающие iptables эволюционирую по направлению к чему-то подобному. Логика shorewall хорошо раскладывает по полочкам все особенности функционирования маршрутизатора и правил фильтрации.
Василий
https://man7.org/linux/man-pages/man8/e4defrag.8.html
Ну так себе дефраг. Уровень нтфс походу
riv
а что о своем ресурсе при этом думал сам ссд в смарте?
Честно говоря эксперемент не ставил, но трим - это не запись. Повторно освобождёнеые блоки не перезаписываются. Другое дело, что поток мелких операций трим нагружает канал связи с накопителем и процессор накопителя. По этому, у меня autotrim выключен и я делаю трим ночью во время минимальной активности сразу после удаления снимков переданных на сервер резервного копирования.
riv
https://www.opennet.ru/openforum/vsluhforumID3/124698.html#88
Пишут, что SSD не подвержены фрагментации.
Однако мне кажется, что после send -R | receive датасета в новый пул даже на Samsung EVO ZFS работает заметно веселее.
Это проявляется даже при повторном send | receive который выдает поток данных с равномерной скоростью в десятки и сотни Mbs в зависимости от пропускной контроллера, а не рывками и приседаниями ниже 1Mbs вплоть до около 100 Kbs как до дефрагментации.
Ssd 100% подвержены фрагментации и после security erase даже intel s3700, например, работают заметно шустрее. Причем это внутрення фрагментация, не связанная с ырагментацией файлов в ФС.
riv
А почему тогда send > /dev/null вычитывает до дефрагментации дольше, проседания до 1Mbs и ниже?
А о какой модели ssd идет речь?
Alexander
Ssd 100% подвержены фрагментации и после security erase даже intel s3700, например, работают заметно шустрее. Причем это внутрення фрагментация, не связанная с ырагментацией файлов в ФС.
Я про воздействие фрагментации ZFS на Samsung EVO SATA на рабочей станции Core2 Quad.
Trim не делал.
riv
Я про воздействие фрагментации ZFS на Samsung EVO SATA на рабочей станции Core2 Quad.
Trim не делал.
Скорее всего, вы столкнулись не с фрагментацией. Т.к. вы не делали тримм, zfs фактически занял весь объём накопителя данными и контроллер ssd перевел ячейки памяти из 1-битного режима работы в 3-х или 4-х битный, в котором скорость работы памятм понижается на попядки (10-100 раз!), также сильно увеличивается износ.
Попробуйте, ради эксперемента, сделать security erase, затем разметить 1/4 объёма ssd и там создать zfs. Скорее всего, с падпнием производительности вы не столкнётесь, кроме падения производительности записи при длительном непрерывном потоке из-за изчерпания буфера.
Alexander
Скорее всего, вы столкнулись не с фрагментацией. Т.к. вы не делали тримм, zfs фактически занял весь объём накопителя данными и контроллер ssd перевел ячейки памяти из 1-битного режима работы в 3-х или 4-х битный, в котором скорость работы памятм понижается на попядки (10-100 раз!), также сильно увеличивается износ.
Попробуйте, ради эксперемента, сделать security erase, затем разметить 1/4 объёма ssd и там создать zfs. Скорее всего, с падпнием производительности вы не столкнётесь, кроме падения производительности записи при длительном непрерывном потоке из-за изчерпания буфера.
Так без воздействия на Trim я пересоздавал пул репликацией из бэкапа и после этого работало значительно быстрее, причем тут Trim?
Василий
Это ж должно в три раза больше места стать, не?
Василий
Так без воздействия на Trim я пересоздавал пул репликацией из бэкапа и после этого работало значительно быстрее, причем тут Trim?
Ну на дешманских ссд трим таки нужен
Василий
Хотя его можно заменить на оверпровизион или как оно там называется
 Aleksandr
Aleksandr
 Ivan
Aleksandr
Ivan
Aleksandr
Услышал. Спасибо большое
Ivan
есть еще компромиссный вариант. самоделкины умеют менять механику на некоторых типах hdd. соответственно после этой операции добыть данные с вылетевших дисков будет проще. стоит работа самоделкиных дешевле, чем в лабах, но и рисики повыше.
Aleksandr
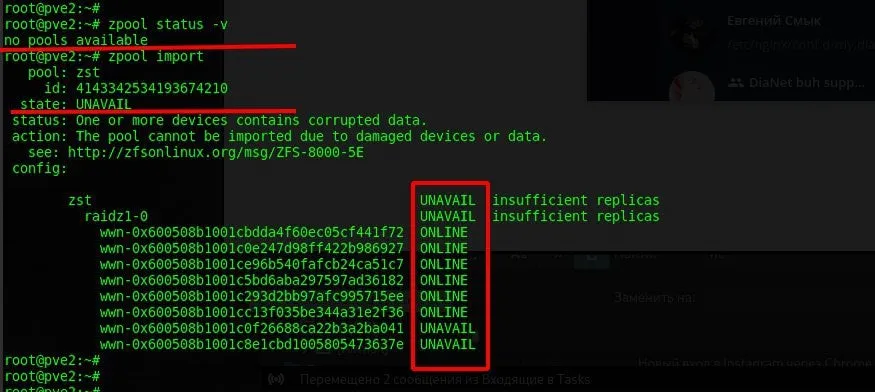
Ну там не настолько ценная инфа, думали мож у зфс есть какие то инструменты что позволят достать данные при потере 2х дисков. Понимание есть того что нужно было raidz2 использывать, тогда бы пережили смерть 2х дисков.
Не спросить за наличие волшебной кнопки "восстановить все данные, починить диски, никогда не ломаться" стоило =)
nikolay
менять механику?))) про перепаивание контроллеров слышал, про замену механики - это что-то из области фантастики, те кто примерно знает как устроен современный hdd и какие там допуски меня поймут
Alexander
Услышал. Спасибо большое
Можно узнать какой был промежуток времени между выходом из строя первого и второго диска и насколько они были новыми, из одной ли партии и т.п.?
Alexander
Относительно недавно были гадания на кофейной гуще, что произойдет при аналогичной ситуации нехватки реплик данных при достаточном количестве реплик метаданных на separated mirror special vdev.
Никто не пробовал? Когда метаданные отдельно, как ZIL на SLOG.
Ivan
менять механику?))) про перепаивание контроллеров слышал, про замену механики - это что-то из области фантастики, те кто примерно знает как устроен современный hdd и какие там допуски меня поймут
ну мб не только механику. но прилипшие/кривые головв чинят их заменой, например
nikolay
ну мб не только механику. но прилипшие/кривые головв чинят их заменой, например
дайте ссылочку на кулибиных
nikolay
та не надо, не верю я что в кустарных условиях можно разобрать hdd, поменять головки и собрать так чтобы он работал.
Ivan
та не надо, не верю я что в кустарных условиях можно разобрать hdd, поменять головки и собрать так чтобы он работал.
однако можно. знакомый свой вд 500гиговый понёс в какую-то сомнительную фирму, там ему сказали что за 7к сделают. разобрали винт и сказали что теперь это будет стоить 20к. я уж засомневался что после транспортировки вскрытого винта вообще можно что-то починить будет. но по знакомым отыскали человека умеющего, всего за 5к с донором вытащили все важные данные.
Ivan
возможно старые винты проще ковырять, чем современные.
nikolay
однако можно. знакомый свой вд 500гиговый понёс в какую-то сомнительную фирму, там ему сказали что за 7к сделают. разобрали винт и сказали что теперь это будет стоить 20к. я уж засомневался что после транспортировки вскрытого винта вообще можно что-то починить будет. но по знакомым отыскали человека умеющего, всего за 5к с донором вытащили все важные данные.
где здесь сказано что меняли головки? понятие "разобрали" очень растяжимое. донор - это диск с которого снимают плату контроллера и ставят на сбойный. иногда это помогает иногда нет.. даже у дисков выпущенных в нулевых очень прецензионная механика чтобы починить ее "на коленке". впрочем это оффтоп, не будем развивать тему.
George
George
ну или пытаться хотя бы один диск воскресить и слить даже с потерями его, и с ним импортировать в readonly
Aleksandr
Можно узнать какой был промежуток времени между выходом из строя первого и второго диска и насколько они были новыми, из одной ли партии и т.п.?
Внезапно как оказалось не так прочто ответить на этот вопрос =)
Aleksandr
Aleksandr
ну или пытаться хотя бы один диск воскресить и слить даже с потерями его, и с ним импортировать в readonly
Кто то сталкивался как sas винт подключить без рейд контроллеров? Мож переходник какой то есть pci на sas?
nikolay
Aleksandr
Sas HBA
Есть такой, но там hba - m2 и переходник m2 pci. Не работал...
Диск жолжен как устройство определяться?
nikolay
Есть такой, но там hba - m2 и переходник m2 pci. Не работал...
Диск жолжен как устройство определяться?
Нет, гугл покажет море ссылок например по модели lsi9305