 George
George


ну и параметры fio которым тестили
George
В существующий пул добавить ещё один диск?
можно и так, но только учтите что удалить нельзя, только пул пересоздать
George
вдруг там у gcp есть какой прикол
George
просто из опыта - жирные диски в облаках - зло
 Fedor
Fedor
или вдруг у гцп просто бёрст такой
Fedor
а фактический ниже
 Dmitry
Dmitry
просто из опыта - жирные диски в облаках - зло
Лучше raidz делать из дисков поменьше? Что-то мне кажется что это и так Страйп из дисков
George
George
ни в коем случае для вас
George
вам только страйпы
George
т.е. vdevs из одного диска
Fedor
райдз вроде как даёт пенальти, сопоставимый с райд5-6
George
райдз вроде как даёт пенальти, сопоставимый с райд5-6
он даёт iops одного самого медленного диска в первую очередь, то есть для БД противопоказан
 Сергей
Сергей
Лучше raidz делать из дисков поменьше? Что-то мне кажется что это и так Страйп из дисков
raid0 вам предлагают - запись и чтение будет идти параллельно на оба диска
George
если нужно резервирование - миррор, если не нужно - страйп=raid0
George
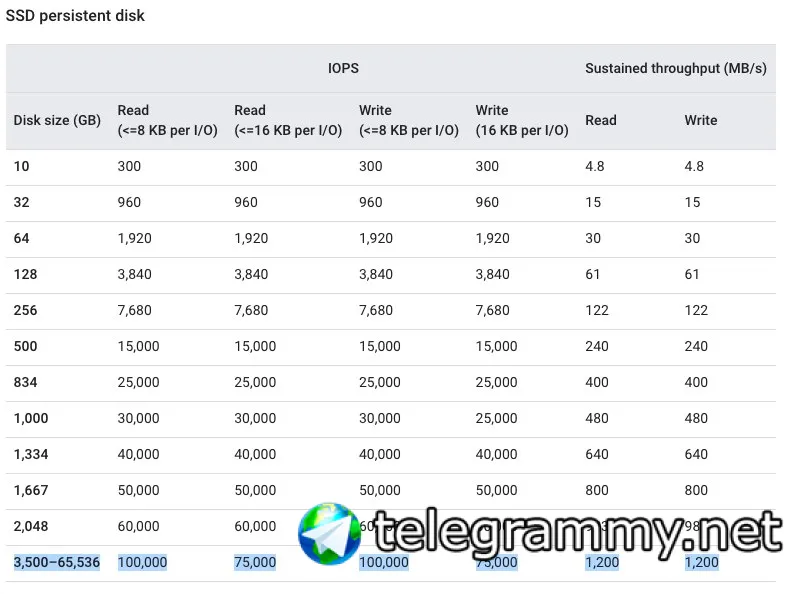 George
George
вот кстати из gcp пример почему несколько дисков лучше одного
George
после 3.5ТБ они не дадут бОльший перформанс
George
а с ext нужно сравнивать что iostat показывает и каким блоком там доступ идёт
Сергей
Dmitry
Те лучше сделать страйп из 3 3,5тб дисков? И это может дать больше iops?
George
и от этого плясать - каким блоком zfs может работать чтобы быть похожим
George
как бы гугл тоже не оказался хитрым - и общая скорость по всем дискам тоже может оказаться не более 1200
только если в сеть до стораджа упереться, тут да
Сергей
только если в сеть до стораджа упереться, тут да
не только, они могут резать и скорость инстансу. Т.е. 3.5+3.5 могут иметь общую скорость такую же как и 7тб
George
Те лучше сделать страйп из 3 3,5тб дисков? И это может дать больше iops?
it depends от реализации доступа до хранилища, если сеть позволит - то теоретически да. Но за gcp я тут ничего не скажу
George
George
но по умолчанию можно придерживаться правила что несколько дисков дадут лучший результат, т.к. их можно эффективнее на инфраструктуру размазать. Это я как разраб облака говорю ))
George
захотят, уверен))). Это они кого хочешь скорее на деньги нагреют
ага, всё же QoSами обмазано для этого в частности
George
ну и для защиты от злого соседа
Dmitry
fio гонял вот такое sudo fio --name=random-write --ioengine=libaio --rw=readwrite --bs=8k --numjobs=1 --size=4g --iodepth=1 --runtime=60 --time_based --end_fsync=1 --filename=/dev/disk
Dmitry
менял кол-во джобов и размер блока для экспериментов
Fedor
bs=8k это как раз ashift=13
George
--rw=readwrite это не randwrite , хотя назвали джобу вы именно так)
George
т.е. тестили вы на поточные чтение+запись 50 на 50%
Dmitry
--rw=readwrite это не randwrite , хотя назвали джобу вы именно так)
вы правы, настройки менял а название нет
George
вы правы, настройки менял а название нет
это не ошибка в копипасте? если нет, то стоит перепрогнать отдельно randwrite и randread
Сергей
т.е. тестили вы на поточные чтение+запись 50 на 50%
Дмитрий предполагает что проигрывание валов на реплике носит характер последовательных операций
Dmitry
Дмитрий предполагает что проигрывание валов на реплике носит характер последовательных операций
да я уже ни в чем не уверен)
Сергей
прошлый раз я точно так же указал что нужно тестировать randrw
Dmitry
вы правы надо проверить именно так
George
Дмитрий предполагает что проигрывание валов на реплике носит характер последовательных операций
я с постгре постольку поскольку, но по идее применение wal логов на данные, которые хранятся не в виде log-like структур сильно рандомный процесс
Сергей
да я уже ни в чем не уверен)
я имею дело с GCP. И у меня были проблемы с ПГ на их инстансе. Поэтому я бы не стал доверять рекламным листовкам от гугла по их цифрам)
George
от ext4 zfs может отставать минимум на 10%, но точно не на 50 и более просто
George
и почему стоит тестить чтение и запись отдельно - потому что для zfs чтение всегда рандомно, зато ARC более эффективен чем pagecache
George
вы правы надо проверить именно так
можете ещё ashift проверить, если у вас только постгря внутри и сжатие не используете, то ashift=13 ничем не помешает, зато может помочь, и у локальных ssd, и у программных решений размер блока обычно сильно больше 4К
Сергей
и почему стоит тестить чтение и запись отдельно - потому что для zfs чтение всегда рандомно, зато ARC более эффективен чем pagecache
там весьма специфичный характер нагрузки, где кэш можно сказать вообще не используется. Читаем базу и применяем к ней журнал, пишем на диск новое состояние. И так до посинения, пока синк не произойдёт
George
там весьма специфичный характер нагрузки, где кэш можно сказать вообще не используется. Читаем базу и применяем к ней журнал, пишем на диск новое состояние. И так до посинения, пока синк не произойдёт
ну я к тому что взяв просто 50/50 чтение-запись сложно сопоставить всё равно
Dmitry
Dmitry
ну я к тому что взяв просто 50/50 чтение-запись сложно сопоставить всё равно
да согласен прогоню отдельно рандрид и рандрайт
Сергей
ну я к тому что взяв просто 50/50 чтение-запись сложно сопоставить всё равно
это да. я вообще например думаю что проведя тест на случайных операциях Дмитрий вообще на гугл обидится))). Так как ожидаемых цифр может и не увидит
George
сжатие используем дефолтное lz4
ммм, вообще lz4 на поток до 800МБ/сек должен выдавать, скорее всего не упираетесь в него
Dmitry
ммм, вообще lz4 на поток до 800МБ/сек должен выдавать, скорее всего не упираетесь в него
процессы которые сжатием занимаются ядра свои не выедают тоже
Dmitry
убрать сжатие может дать какой-то эффект?
George
процессы которые сжатием занимаются ядра свои не выедают тоже
по этой причине можете пока не убирать
George
но тогда учтите, что fio будет показывать чушь, если со сжатием мерять попробуете
Dmitry
это да. я вообще например думаю что проведя тест на случайных операциях Дмитрий вообще на гугл обидится))). Так как ожидаемых цифр может и не увидит
мне надо хоть чучелом хоть тушкой но разогнать реплику) либо вот прям объяснить почему ext4 реплика живет без проблем а zfs нет
George
мне надо хоть чучелом хоть тушкой но разогнать реплику) либо вот прям объяснить почему ext4 реплика живет без проблем а zfs нет
пути есть, поставить нужные ashift+recordsize, xattr=sa, atime=off, sync=disabled, сжатие для начала можно не включать даже, покрутить для такого специфичного случая write throttle мб, использовать несколько дисков. Что-то из этого))))
George
а что вы для zfs настраиваете вообще? вы там случаем параметры модуля не крутили? арк не уменьшали?
Dmitry
параметры модуля крутил
options zfs zfs_vdev_scrub_min_active=24
options zfs zfs_vdev_scrub_max_active=64
# sync write
options zfs zfs_vdev_sync_write_min_active=8
options zfs zfs_vdev_sync_write_max_active=32
# sync reads (normal)
options zfs zfs_vdev_sync_read_min_active=8
options zfs zfs_vdev_sync_read_max_active=32
# async reads : prefetcher
options zfs zfs_vdev_async_read_min_active=8
options zfs zfs_vdev_async_read_max_active=32
# async write : bulk writes
options zfs zfs_vdev_async_write_min_active=8
options zfs zfs_vdev_async_write_max_active=32
Dmitry
арк не трогал
Dmitry
Dmitry
почему? они давали прирост
George
а как покрутить write throttle
там всё не просто, можете начать с https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/ZFS%20Transaction%20Delay.html
но это последнее, куда стоит лезть сейчас
Dmitry
т.е. план примерно следующий убрать кастомные настройки модуля, выставить параметры пула, которые вы дали выше, погонять фио при разных значениях рекордсайза и ашифт, попробовать страип из 3 или 4 х дисков по 3.5ТБ
Dmitry
обычно дефолтных параметров хватает
да вроде уже все перебробовал поэтому полез уже туда, потом мне вот дали этот канал
George
плюс сравнить с рандомными тестами самих дисков и ext4
Dmitry
да 0 шаг фио на сыром диске
George
посмотреть в iostat как ext4 смог нагрузить диск
Dmitry
спасибо большое - попробую отпишусь
George
по постгре мне эта преза нравилась, увы в жизни не применял, но вещи по делу https://people.freebsd.org/~seanc/postgresql/scale15x-2017-postgresql_zfs_best_practices.pdf
Dmitry