ну то есть такое в целом реально?
в целом все реально ))
 Dmitry
Dmitry


 Nikolay
Nikolay
SSD - 1.92Tb Samsung PM963 порезан на 1.6Тб, на нем 32Гб SLOG и остатки - L2ARC
а зачем доавляли ? без него было хуже ?
Dmitry
а зачем доавляли ? без него было хуже ?
ну прям на 100% уверенности нет, но вроде как стало лучше, вместо 10 вм повесили 11
Dmitry
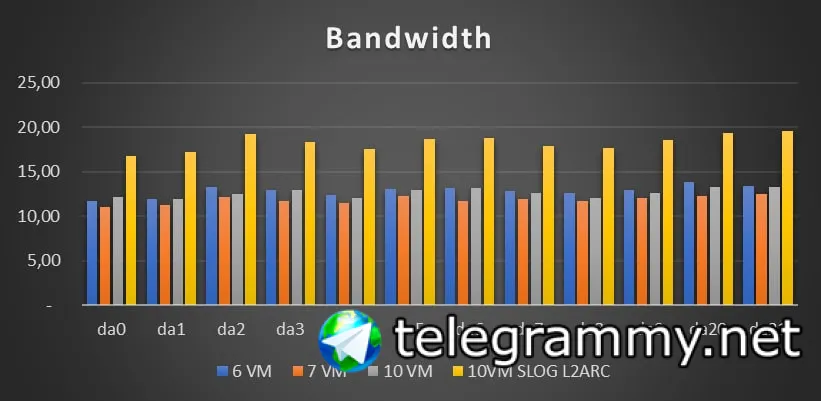
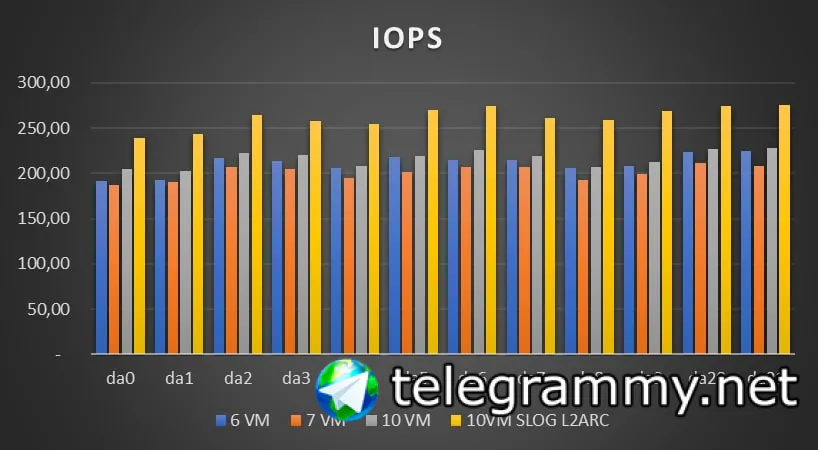
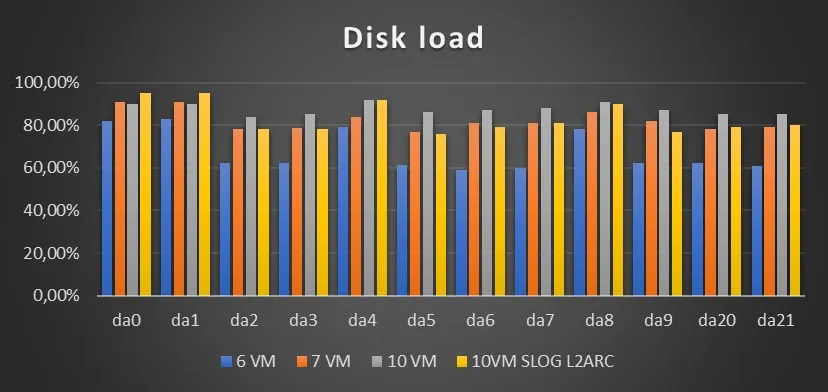
сравнили iostat
Dmitry
 Dmitry
Dmitry
 Dmitry
Dmitry
это чтение
Dmitry
 George
George
Всем привет! Даже когда на zfs нет нагрузки в /proc/spl/kstat/zfs/dmu_tx
dmu_tx_assigned постоянно увеличивается каждую секунду. Откуда эти транзакции. TxG по дефолту должна отрабатывать каждые 5 сек (zfs_txg_timeout)
- zfs_txg_timeout это МАКС таймаут, есть другие лимиты для сброса txg на диск раньше
- единомоментно существует минимум iirc 3 txg, одна уже закрыта и сбрасывается на диск, одна в процессе закрытия, одна открытая для наполнения, т.е. чтобы раз в 5 секунд она появлялась - должно повезти
George
обсуждали же уже, там очень круто звезды должны сойтись, чтобы это привело к краху ФС
ага, только если в коде баг, штатно потеря l2arc не критична, на нём нет ничего важного для пула, только кеш
 Владимир
Nikolay
Владимир
Nikolay
@gmelikov Можно спросить по special vdev. Примерно 1,2 -1,3% от размера пула. Ну допустим.
Но читал что (не могу найти только где:( ) что допустим при слишком маленьком recordsize а сильно увеличивается фрагментация и (!) количество метадаты.
С фрагментацией вроде, если система оперирует большим размером, от сюда и фрагментация.
А вот про метадату это правда ? Количество метадаты которую может породить пул не константная величина ? От чего её кол-во зависит ?
Спасибо!
George
@gmelikov Можно спросить по special vdev. Примерно 1,2 -1,3% от размера пула. Ну допустим.
Но читал что (не могу найти только где:( ) что допустим при слишком маленьком recordsize а сильно увеличивается фрагментация и (!) количество метадаты.
С фрагментацией вроде, если система оперирует большим размером, от сюда и фрагментация.
А вот про метадату это правда ? Количество метадаты которую может породить пул не константная величина ? От чего её кол-во зависит ?
Спасибо!
да, на каждый блок генерится метадата, чем меньше размер блока тем, теоретически, её больше.
 Sergey
Sergey
- zfs_txg_timeout это МАКС таймаут, есть другие лимиты для сброса txg на диск раньше
- единомоментно существует минимум iirc 3 txg, одна уже закрыта и сбрасывается на диск, одна в процессе закрытия, одна открытая для наполнения, т.е. чтобы раз в 5 секунд она появлялась - должно повезти
Георгий, спасибо за ответ. С 3-мя TxG все понятно, насколько я понимаю, отработка TxG срабатывает по достижении порога грязных буферов или по таймауту. Если у хоста 32Гб памяти, по дефолту порог срабатывания около 2ГБ, и если нагрузка на запись меньше (я имею в виду запись в файл или zvol) то раз в 5 секунд и появляется новая закрытая транзакция. Частенько это наблюдал в /proc/spl/kstat/zfs/<>/txgs. А вопрос я задавал про полное отсутствие к-либо нагрузки.... Есть ли возможность посмотреть, что вызвало отработку TxG?
Ivan
разве так бывает, когда нет абсолютно никакой нагрузки ?
Sergey
разве так бывает, когда нет абсолютно никакой нагрузки ?
Иван, в проде - нет ))) но я сейчас тестирую сигейтовские 16ТБ диски, а они себя очень странно ведут под zfs.
nikolay
Иван, в проде - нет ))) но я сейчас тестирую сигейтовские 16ТБ диски, а они себя очень странно ведут под zfs.
они не черепичные случаем?)
Sergey
они не черепичные случаем?)
Николай, не черепичные. И если диск использовать, как стандартное устройство нормально работает. Но вот под zfs, да еще при записи блоком 4К время отработки транзакции выходит за 200 сек и zfs ложиться... И это устойчиво воспроизводимый эффект
Dmitry
у меня 4*Exos 14Тб в домашнем NAS никаких проблем
nikolay
Николай, не черепичные. И если диск использовать, как стандартное устройство нормально работает. Но вот под zfs, да еще при записи блоком 4К время отработки транзакции выходит за 200 сек и zfs ложиться... И это устойчиво воспроизводимый эффект
Интересный эффект. Он как то зависит от конфигурации пула и/или vdev?
Ivan
Dmitry
Обновление прошивки на сайте сигейта не смотрели?
Sergey
fio на отдельном диске пробовали запускать ?
Я больше люблю vdbench. Нагружал и в хвост и в гриву, работают норм, без нареканий. И с включенным и выключенным кэшом записи
Sergei
ашифт какой? 12? и на датасете какой блок?
Sergey
Интересный эффект. Он как то зависит от конфигурации пула и/или vdev?
Да, эффект наблюдается, если ashift=9. Raidsz2. Группа ложиться прям за пару минут при записи 4К блоком
Ivan
Я больше люблю vdbench. Нагружал и в хвост и в гриву, работают норм, без нареканий. И с включенным и выключенным кэшом записи
как планируете сравнивать попугаев vdbench с попугаями fio ?
Sergei
Sergei
он же 512е/4kn
 Сергей
Сергей
SSD - 1.92Tb Samsung PM963 порезан на 1.6Тб, на нем 32Гб SLOG и остатки - L2ARC
а какой у вас размер основного пула? 14Tbx4? Или всего 14Тб из 4х дисков?
Sergey
он же 512е/4kn
Сергей, если ashift=12 при записи блоком 4К дикий перерасход места - по логике raidz2 под 4к блок уйдет 12К
Dmitry
а какой у вас размер основного пула? 14Tbx4? Или всего 14Тб из 4х дисков?
там другой пул. Там 12*6Tb
Sergei
Сергей, если ashift=12 при записи блоком 4К дикий перерасход места - по логике raidz2 под 4к блок уйдет 12К
там же эмуляция 512. Пишется же все равно в блок 4к? или я не прав?
 Fedor
Fedor
Но если надо записать 4к, будет 8 операций по записи 4к со стороны систем диска
Fedor
Они могут смержиться, конечно - но кто знает
Fedor
Низкоуровнево при фиксации данных
Sergey
там же эмуляция 512. Пишется же все равно в блок 4к? или я не прав?
Эмуляция 512е не запрещает писать блок 512б, понятное дело, при записи одиночного блока будет read-modify-write внутри диска. Ну и zfs по одному блоку не пишет на диск. Я смотрел iostat средний размер запси на диск 4К
Sergei
то есть 4к блок бьётся на 8 блоков по 512к, + несколько копий меты в другие сектора ещё писаться будут?
Sergei
а тут special devices не помогут?
Sergey
то есть 4к блок бьётся на 8 блоков по 512к, + несколько копий меты в другие сектора ещё писаться будут?
мету я и так пишу в special на ssd
Sergei
а сразу захлёбывается или есть какой-то порог насыщения?
nikolay
Сергей, если ashift=12 при записи блоком 4К дикий перерасход места - по логике raidz2 под 4к блок уйдет 12К
Серег, мне казалось что ashift=9 , это для совсем старых дисков актуально. а расход места будет зависеть в первую очередь от recordsize или volblocksize ну и от компрессии еще..
Sergei
 Sergei
Sergei
есть ещё такое
Sergey
а сразу захлёбывается или есть какой-то порог насыщения?
Там начинает количество грязных буферов расти (транзакция прям самая первая с начала нагрузки не может завершиться) zfs начинает задержку увеличивать, скорость записи падает практически до 0 , потом 3 сообщения про превышение допустимого времени отработки транзакции и zfs ложиться
nikolay
Серег, мне казалось что ashift=9 , это для совсем старых дисков актуально. а расход места будет зависеть в первую очередь от recordsize или volblocksize ну и от компрессии еще..
т. е. если ты точно знаешь что будешь писать блоками по 4к, то выбираем recordsize=4k, а ashift для пула ставим =12
Sergei
оверхед же большой при размере блока датасета в 4к
nikolay
оверхед же большой при размере блока датасета в 4к
при рекордсайз = 4к тоже будет оверхед? не совсем понятно откуда..
Sergey
т. е. если ты точно знаешь что будешь писать блоками по 4к, то выбираем recordsize=4k, а ashift для пула ставим =12
Коля, прикинь, прилетает блок 8К, raidz2 аллоцирует количество блоков, кратное 3-м. Т.е. 4+4 (8К) да еще 2 блока четности и еще впустую расходуются 2 блока чтобы получилось 6. Это при ashift12. А при ahift9 все более-менее гуманно с точки зрения пространства. Добавлю, что такая фигня с зависанием zfs только на этой модели, то же самое пробовал на других вендорах, все норм
Sergey
А с 4К на ahift12 еще хуже
Sergei
может с wce=0 попробовать?
Alexander
может с wce=0 попробовать?
12 лучше для ssd, 9 возможно! для 7200 HDD будет лучше, много раз тут это обсуждалось)
 Николай Орлов
Николай Орлов
мне посоветовали 12 на диски с 512б (((
Николай Орлов
блин опять переделывать е мое
Sergei
512 всего лишь размер логический, в любом случае 4к читаться будет и как писали будет много rmw
Николай Орлов
так как все таки гуманнее 9 или 12
Sergei
наверное, исходя из ТТХ диска)
Sergei
ну кто щас пишет блоком <4к?
nikolay
Коля, прикинь, прилетает блок 8К, raidz2 аллоцирует количество блоков, кратное 3-м. Т.е. 4+4 (8К) да еще 2 блока четности и еще впустую расходуются 2 блока чтобы получилось 6. Это при ashift12. А при ahift9 все более-менее гуманно с точки зрения пространства. Добавлю, что такая фигня с зависанием zfs только на этой модели, то же самое пробовал на других вендорах, все норм
разве под четность выделяются блоки по 4к? и почему обязательно должно именно 6 блоков? я видимо чего-то не понимаю)
George
Георгий, спасибо за ответ. С 3-мя TxG все понятно, насколько я понимаю, отработка TxG срабатывает по достижении порога грязных буферов или по таймауту. Если у хоста 32Гб памяти, по дефолту порог срабатывания около 2ГБ, и если нагрузка на запись меньше (я имею в виду запись в файл или zvol) то раз в 5 секунд и появляется новая закрытая транзакция. Частенько это наблюдал в /proc/spl/kstat/zfs/<>/txgs. А вопрос я задавал про полное отсутствие к-либо нагрузки.... Есть ли возможность посмотреть, что вызвало отработку TxG?
надо смотреть нагрузку, zpool iostat в помощь, т.е. кто-то что-то всё же пишет
Nikolay
мне посоветовали 12 на диски с 512б (((
Вообще правильно посоветовали. Даже на 512 дисках расход будет маленький, пользы больше
Николай Орлов
Фуух, успокоили, спасибо
George
Георгий, спасибо за ответ. С 3-мя TxG все понятно, насколько я понимаю, отработка TxG срабатывает по достижении порога грязных буферов или по таймауту. Если у хоста 32Гб памяти, по дефолту порог срабатывания около 2ГБ, и если нагрузка на запись меньше (я имею в виду запись в файл или zvol) то раз в 5 секунд и появляется новая закрытая транзакция. Частенько это наблюдал в /proc/spl/kstat/zfs/<>/txgs. А вопрос я задавал про полное отсутствие к-либо нагрузки.... Есть ли возможность посмотреть, что вызвало отработку TxG?
вообще порогов срабатывания там несколько, пока есть к примеру https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Module%20Parameters.html#zfs-dirty-data-sync , который по дефолту 68МБайт
Николай Орлов
Вообще правильно посоветовали. Даже на 512 дисках расход будет маленький, пользы больше
А рекордсайз на что влияет, если по простому
Николай Орлов
И какой лучше , по дефолту 128кб
Nikolay
А рекордсайз на что влияет, если по простому
recordsize определяет размер блока данных которых zfs пишет в дата сетах.
Для ознакомления с основами вам сюда:
https://habr.com/ru/post/504692/
Николай Орлов
Спасибо
Николай Орлов
Вот это не понял
Николай Орлов
Свойство ashift устанавливается для каждого виртуального устройства vdev, а не для пула, как многие ошибочно думают — и не изменяется после установки. Если вы случайно сбили ashift при добавлении нового vdev в пул, то вы безвозвратно загрязнили этот пул устройством с низкой производительностью и, как правило, нет другого выхода, кроме как уничтожить пул и начать всё сначала.
Николай Орлов
К примеру у меня 4 блочных диска