 Sergei
Sergei


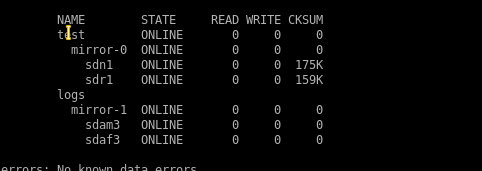
sdn и sdr входят в mirror
Sergei
 Ivan
Ivan
у меня такое было с одним диском когда тесты на нём через fio проводил )
Ivan
не выключая из зеркала
Ivan
после скраба и ресильвера всё залечилось. а что делать когда полностью зеркало побито - идти за бэкапами.
Ivan
или мб у тебя smr диск ?
Sergei
это ssd
Alexander
Поправлю Сергея вопрос чуть чуть в другом, после нескольких дней перестало попадать что либо в логс
Alexander
 Sergei
Sergei
 Sergei
Sergei
на slog дисках
Sergei
 Alexander
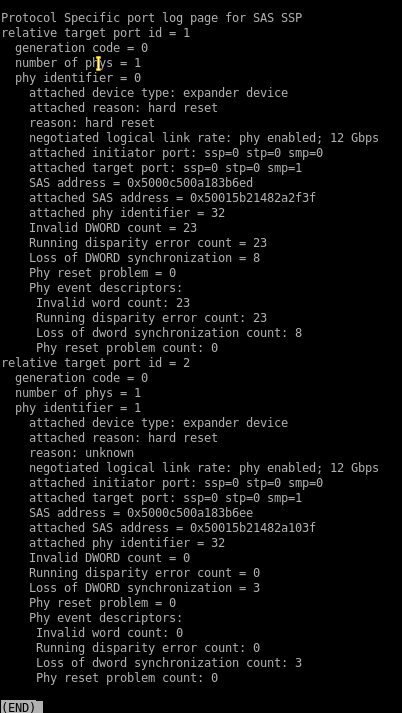
Alexander
при этом смарты дисков в порядке
Dmitry
а вот вопрос у меня созрел, как бы мониторить производительность - полосу, иопсы и латенси наилучшим способом? Желательно с высоким разрешением - несколько раз в секунду и под BSD. Нарыл на гитхабе скрипт для dtrace но он какие-то странные цифры показывает
Dmitry
 Dmitry
Dmitry
натравливал iostat на длительный промежуток, так тот изредка писал вот такое:
da0 8315 50976 292615.4 401.4 -1 -67 -16461 -58 0 0
 Vladislav
Dmitry
Vladislav
Dmitry
iops на дисках можно получить через bsnmpd
дык мне бы для начала их локально правильно снимать научиться, как отправлять я разберусь )
Vladislav
Dmitry
а более прямого и короткого пути нету? ))
Vladislav
Ну, посмотрите, как bsnmp снимает
Vladislav
Вот латенси я не видел на FreeBSD, на линуксе есть ioping
 Владимир
Владимир
https://habr.com/ru/post/344204/
 Fedor
Fedor
https://habr.com/ru/post/344204/
таблицы в целом сходятся с реальной практикой.
От себя скажу, для сетевых хранилищ в проксмоксе был выбран зфс, так как для требуемого функционала(снапшоты) его пенальти на тестах ниже, чем даже два снапшота в qcow.
Владимир
то есть ты не заметил что этот придурок сделал зфс с блоком 128к и тестировал его 4к запросами?))
Владимир
чёёёё
Fedor
заметил, конечно, но да хрен с ним)
Владимир
и то что он думает что в zraid есть 0
Fedor
я только циферки смотрел.
если не ошибаюсь, кстати, в блоках по 4к, пишушихся в неаллоцированные области объекта, пишутся не 128к, а 4. @gmelikov поправь, пожалуйста.
Fedor
ещё если посмотреть - интересно, зачем он пытался буферизировать мдадм. я на тестах у себя вообще отключал все слоги, арки и тому подобное
 George
George
я только циферки смотрел.
если не ошибаюсь, кстати, в блоках по 4к, пишушихся в неаллоцированные области объекта, пишутся не 128к, а 4. @gmelikov поправь, пожалуйста.
Iirc нет, размер блока файла меньше recordsize только в одном случае - когда размер файла меньше recordsize. Ну и частный случай с компрессией, оставшиеся 124к нулей она сожмёт, но это касается только записанного на диск, в озу будет всё равно момент, когда блок будет не сжатым и размером 128к.
В неаллоцированные области без сжатия должно писаться полным размером блока, не видел исключений на эту тему
Олег
День добрый. Есть реккомендации по использованию планировщика диска в zfs? сейчас mq-deadline, 50\50 read\write
nikolay
немного наивный вопрос, но на всякий случай хочу уточнить. верно же то, что я могу как расширять так и уменьшать размер zvol "налету", при условии что fs которая создана на нем поддерживает сжатие /расширение?
 Алексей
Алексей
Действительно интересно
Олег
немного наивный вопрос, но на всякий случай хочу уточнить. верно же то, что я могу как расширять так и уменьшать размер zvol "налету", при условии что fs которая создана на нем поддерживает сжатие /расширение?
Расширять да, сжимать не было, может допилили хз, это прям аж ад что нельзя, т/е/ структуру на этапе проектирования лет на 5 должен продумать, что обычно нереально
Ivan
а зачем сжимать когда есть тонкое размещение и дискард ?
 ivdok
ivdok
а что, толстое где-то сразу аллоцирует участок ?
По крайней мере могу сделать send на другой массив, scrub, и receive чтобы привести в чувство пул. С тонким размещением это не прокатило, когда в последний раз пробовал
George
По крайней мере могу сделать send на другой массив, scrub, и receive чтобы привести в чувство пул. С тонким размещением это не прокатило, когда в последний раз пробовал
send/recv для тонкого работает аналогично. Вообще, толстый zvol отличается только резервированием свободного места в пуле (именно места, он не аллоцирует ничего заранее)
George
День добрый. Есть реккомендации по использованию планировщика диска в zfs? сейчас mq-deadline, 50\50 read\write
обычно рекомендация "планировщик попроще, аля noop". А так по нагрузке смотреть и тестить
ivdok
send/recv для тонкого работает аналогично. Вообще, толстый zvol отличается только резервированием свободного места в пуле (именно места, он не аллоцирует ничего заранее)
Даже так лучше, потому что с тонким может быть неждан с заполненностью пула
ivdok
Хотя вообще странно, что CoW, а проблема фрагментации всё ещё есть
George
немного наивный вопрос, но на всякий случай хочу уточнить. верно же то, что я могу как расширять так и уменьшать размер zvol "налету", при условии что fs которая создана на нем поддерживает сжатие /расширение?
увеличивать можно, уменьшать не пробовал, но гугл подсказывает что аналогично можно, надо потестить zfs set volsize=50T
George
Даже так лучше, потому что с тонким может быть неждан с заполненностью пула
проблему верно называете, вопрос чисто в мониторинге, thin zvol никак на оверкоммит не проверяет
George
Хотя вообще странно, что CoW, а проблема фрагментации всё ещё есть
так с cow от фрагментации никуда особо и не денешься
ivdok
так с cow от фрагментации никуда особо и не денешься
А почему бы при, допустим, инвалидации старых блоков, не считывать contiguous пространство, и если места в пуле больше чем фрагментированный zvol, то делать рефы на новое пространство, в фоне копировать блоки и инвалидировать старые, а по-окончаннии не повторить этот цикл?
Ivan
Даже так лучше, потому что с тонким может быть неждан с заполненностью пула
уменьшил раздел внутри вм и нет нежданчика. кмк годный костыль.
ivdok
уменьшил раздел внутри вм и нет нежданчика. кмк годный костыль.
Аллокацию это не изменит, только гость себя зажмёт в рамки
ivdok
А волюм как был на стороне гипервизора раздутый, так и останется
Ivan
А волюм как был на стороне гипервизора раздутый, так и останется
если только виртуально раздутый. т.к. реального места будет занимать меньше за счет дискарда.
ivdok
если только виртуально раздутый. т.к. реального места будет занимать меньше за счет дискарда.
Меньше для гостя внутри, но аллокацию это не сократит
Ivan
чейто ?
Ivan
 Ivan
Ivan
вот эти параметры вполне работают в сторону уменьшения с дискардом
Ivan
или я неправильно понимаю всё ?
George
А почему бы при, допустим, инвалидации старых блоков, не считывать contiguous пространство, и если места в пуле больше чем фрагментированный zvol, то делать рефы на новое пространство, в фоне копировать блоки и инвалидировать старые, а по-окончаннии не повторить этот цикл?
у zfs сейчас нет никакого механизма изменения старых блоков на лету
George
А волюм как был на стороне гипервизора раздутый, так и останется
нет, просто надо сделать trim внутри гостя, в таком случае zfs не используемые блоки отпустит
nikolay
увеличивать можно, уменьшать не пробовал, но гугл подсказывает что аналогично можно, надо потестить zfs set volsize=50T
вот я тоже не нашел явного запрета на уменьшение. ок, проверю на тестовом пуле..
 Andrew
Andrew
Чатик, доброго.
Подскажите.
Есть машинка с xigmanas, используется для хранения бэкапов.
В процессе первичного zfs send/recv с нового сервера она сдохла.
Поменяли машинку, загрузился с той-же флешки, отработал scrub, пытаюсь ещё раз запустить туда-же копию.
Источник -- proxmox
zfs send -Rv rpool/data@2020-10-27-16T23 | ssh root@xigmanas.local "zfs recv -vF tomb/np"
full send of rpool/data/vm-101-disk-1@2020-10-27-16T23 estimated size is 154G
total estimated size is 559G
Password for root@xigmanas.local:TIME SENT SNAPSHOT rpool/data@2020-10-27-16T23
19:08:50 48.7K rpool/data@2020-10-27-16T23
19:08:51 48.7K rpool/data@2020-10-27-16T23
и вот эти 48.7K постоянно.
Если шлю поток в /dev/null с источника, то всё хорошо.
Пробовал делать recv в новый dataset, с тем-же эффектом.
Что почитать/сделать, чтобы понять почему перестало копироваться?
Vladislav
А что там с дисками после "падения"?
Andrew
Нормально, диски в полке MD1000. Через hba, lsi2008.
Vladislav
ну, так изучайте rpool/data на полке.
судя по снапшотам, данные уже есть
Sergey
обычно рекомендация "планировщик попроще, аля noop". А так по нагрузке смотреть и тестить
я issue открывал не заметив, что выставление шедулера выпилили из зфс:
https://github.com/openzfs/zfs/issues/9778
и behlendorf вроде сказал, что mq-deadline нынче считается safe для zfs
Sergey
Вот латенси я не видел на FreeBSD, на линуксе есть ioping
среднюю лейтенси для мониторинга можно высчитывать из статистики по блочным устройствам, что б иопингом дополнительное ио не создавать)
Andrew
на приёмнике ничего не создаётся, выглядит вот так:
xigmanas: ~# zfs list -t all
NAME USED AVAIL REFER MOUNTPOINT
tomb 13.1T 7.99T 141K /mnt/tomb
tomb/backup 13.1T 10.1T 10.9T -
tomb/np 141K 800G 141K /mnt/tomb/np
xigmanas: ~# zfs list -t snapshot
no datasets available
до падения, когда процесс шел, одномоментно было вот так:
xigmanas: tomb# zfs list -t all
NAME USED AVAIL REFER MOUNTPOINT
tomb 13.1T 7.99T 141K /mnt/tomb
tomb/backup 13.1T 10.0T 11.0T -
tomb/nnp 593M 699G 166K /mnt/tomb/nnp
tomb/nnp@2020-10-26-15T49 0 - 166K -
tomb/nnp/subvol-102-disk-0 593M 7.42G 593M /mnt/tomb/nnp/subvol-102-disk-0
tomb/nnp/subvol-102-disk-0@2020-10-26-15T49 0 - 593M -
по статистике, которую я вижу в загрузке интерфейса назначения, не видно активной отправки данных.
в /dev/null с источника данные читаются.
root@pve01-nnp:~# zfs send -Rv rpool/data@2020-10-27-16T23 > /dev/null
full send of rpool/data@2020-10-27-16T23 estimated size is 46.6K
...
full send of rpool/data/vm-101-disk-1@2020-10-27-16T23 estimated size is 154G
total estimated size is 559G
TIME SENT SNAPSHOT rpool/data@2020-10-27-16T23
TIME SENT SNAPSHOT rpool/data/subvol-102-disk-0@2020-10-27-16T23
16:36:00 25.2M rpool/data/subvol-102-disk-0@2020-10-27-16T23
16:36:01 77.3M rpool/data/subvol-102-disk-0@2020-10-27-16T23
Vladislav
Хочется поднять распределенное S3 хранилища поверх серверов с ZFS. Кроме minio есть варианты?
Олег
Vladislav
на инфраструктуру Амазона нет бюджета :)
Владимир
Всем привет. а volblocksize нужно указывать при создании пула?
 Сергей
Владимир
Сергей
Владимир
то есть только при создании волюма?
Владимир
я наверное не верно вопрос задал. Перефразирую, а volblocksize можно указывать при создании пула?
Владимир
я нашёл вот только такой пример
zfs create -V 64G -o compression=lz4 -o volblocksize=128k pool2/myvol_root