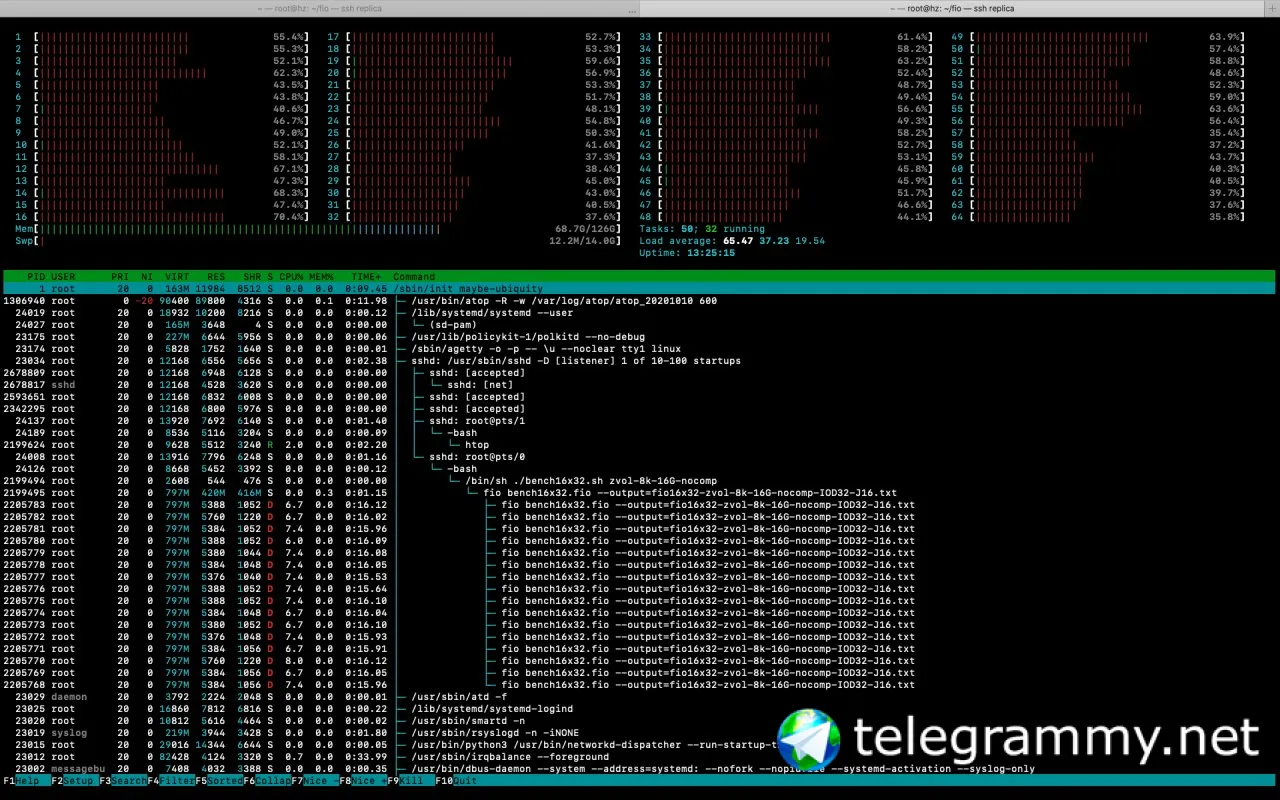
во время теста система совершенно была не загружена. Возможно под данный кейс нужно было тюнить
 Сергей
Сергей

 Сергей
Сергей
 Igor
Alexander
Сергей
Ivan
Ivan
Ivan
Ivan
Igor
Alexander
Сергей
Ivan
Ivan
Ivan
Ivan
 Roman
Alexandr
Roman
Alexandr
 Fedor
Fedor
 George
George
 Evgenii
Dmitry
Dmitry
George
Fedor
Fedor
George
George
Ivan
George
Ivan
George
Ivan
George
Ivan
Ivan
George
Ivan
Ivan
Ivan
Ivan
George
Ivan
Ivan
Ivan
George
George
George
George
George
George
Ivan
Ivan
Ivan
Ivan
George
Ivan
Ivan
George
George
Ivan
George
George
George
George
George
George
Ivan
Ivan
Ivan
Ivan
Evgenii
Dmitry
Dmitry
George
Fedor
Fedor
George
George
Ivan
George
Ivan
George
Ivan
George
Ivan
Ivan
George
Ivan
Ivan
Ivan
Ivan
George
Ivan
Ivan
Ivan
George
George
George
George
George
George
Ivan
Ivan
Ivan
Ivan
George
Ivan
Ivan
George
George
Ivan
George
George
George
George
George
George
Ivan
Ivan
Ivan
Ivan
 Nikolay
Nikolay
Fedor
Nikolay
Fedor
Nikolay
Nikolay
Nikolay
Fedor
Nikolay
Fedor
Nikolay
 Владимир
Владимир
George
Владимир
Владимир
George