 Nikita
Nikita


Как поступить в случае с nfs?
 George
George
Огонь, спасибо огромное.
Т.е. насколько я понимаю, корректный сценарий следующий - создаем сабвольюм на zfs пуле, ставим на хост samba, выдаем пермишны системному юзеру на этот сабвольюм, шарим самбой.
Верно?
ну как вы самбу настроите, она же умеет и сопоставлять юзеров, хотя я не часто её конфигурю) тут от других ФС не отличается
George
Как поступить в случае с nfs?
А в чём вопрос? Так же как и на любой другой ФС поднимаете и настраиваете, zvol вы по ней всё равно не сможете отдать
Nikita
Интересовали нюансы и чужой опыт.
Славно, если сюрпризов не возникнет.
Спасибо Вам большое за консультацию.
George
Интересовали нюансы и чужой опыт.
Славно, если сюрпризов не возникнет.
Спасибо Вам большое за консультацию.
в nfs нюанс только если будете снапшоты шарить из snapdir, там параметр один надо поменять
George
в nfs
Nikita
Гуд, прогуглю отдельно, спасибо.
riv
#Проблема
root@htz-vm00 /etc/apt/sources.list.d # cat /sys/module/zfs/parameters/zfs_arc_max
4294967296
root@htz-vm00 /etc/apt/sources.list.d # echo $[ $(cat /sys/module/zfs/parameters/zfs_arc_max) / 1024 / 1024 / 1024 ]
4
Т.е. zfs_arc_max=4Гбайт, но в реальности он занимает почти всю свободную оперативку, которой не мало.
time read miss miss% dmis dm% pmis pm% mmis mm% arcsz c
11:30:42 0 0 0 0 0 0 0 0 0 125G 125G
total used free shared buff/cache available
Mem: 257832 207179 19503 67 31149 49011
Swap: 32767 0 32767
https://pastebin.com/raw/EWTStjsj
George
#Проблема
root@htz-vm00 /etc/apt/sources.list.d # cat /sys/module/zfs/parameters/zfs_arc_max
4294967296
root@htz-vm00 /etc/apt/sources.list.d # echo $[ $(cat /sys/module/zfs/parameters/zfs_arc_max) / 1024 / 1024 / 1024 ]
4
Т.е. zfs_arc_max=4Гбайт, но в реальности он занимает почти всю свободную оперативку, которой не мало.
time read miss miss% dmis dm% pmis pm% mmis mm% arcsz c
11:30:42 0 0 0 0 0 0 0 0 0 125G 125G
total used free shared buff/cache available
Mem: 257832 207179 19503 67 31149 49011
Swap: 32767 0 32767
https://pastebin.com/raw/EWTStjsj
если параметр задавался уже после заполнения ARC, то он не приводит к автоматическому уменьшению ARC.
George
ну и без надобности не советую ужимать ARC
riv
Параметр задан так:
root@htz-vm00 ~ # cat /etc/modprobe.d/zfs.conf
options zfs zfs_arc_max=0x100000000 zfs_txg_timeout=5
После перезагрузки он почему-то отображается в /sys/module/zfs/parameters/zfs_arc_max но не действует.
И я вспоминаю, что неделю назад тут проскакивал пост, где жаловались на тоже самое.
riv
ну и без надобности не советую ужимать ARC
Вопрос не в его размере, вопрос в том, что ограничение не работает.
Это proxmox свежеустановленный.
George
Параметр задан так:
root@htz-vm00 ~ # cat /etc/modprobe.d/zfs.conf
options zfs zfs_arc_max=0x100000000 zfs_txg_timeout=5
После перезагрузки он почему-то отображается в /sys/module/zfs/parameters/zfs_arc_max но не действует.
И я вспоминаю, что неделю назад тут проскакивал пост, где жаловались на тоже самое.
оно в хексе умеет принимать?) не пробовал, прикольно
nanomechanic
hugepages в коммандлайне ядра не резервируются ?
George
Вопрос не в его размере, вопрос в том, что ограничение не работает.
Это proxmox свежеустановленный.
в 0.8.4 не помню такого открытого бага, надо копаться
Ivan
nanomechanic
Кстати, есть решение или патчи, чтобы треды zfs и буфера припинить к контретному NUMA узлу ?
riv
hugepages в коммандлайне ядра не резервируются ?
root@htz-vm00 ~ # cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-5.4.65-1-pve root=/dev/mapper/vg--host-root ro nomodeset consoleblank=0
Ivan
Кстати, есть решение или патчи, чтобы треды zfs и буфера припинить к контретному NUMA узлу ?
в идеале к тому же, к которому hba привязан )
riv
а если выдать чуть больше 4ГБ ?
Смогу вечером проверить. Но тут пул то всего 4ТБ, у меня есть машина, где 32ТБ и ограничение работает, тоже проксмокс, установлен год назад. Но со всеми обновлениями.
nanomechanic
в идеале к тому же, к которому hba привязан )
да хотя бы к другому а не тому, на котором постгресс или виртуалки
Sergei
Кстати, есть решение или патчи, чтобы треды zfs и буфера припинить к контретному NUMA узлу ?
неа, zfs в numa не может
nanomechanic
root@htz-vm00 ~ # cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-5.4.65-1-pve root=/dev/mapper/vg--host-root ro nomodeset consoleblank=0
а что произойдет с памятью после echo 3 > /proc/sys/vm/drop_caches ?
riv
а что произойдет с памятью после echo 3 > /proc/sys/vm/drop_caches ?
Все стало прекрасно
root@htz-vm00 ~ # free -m
total used free shared buff/cache available
Mem: 257832 83032 174338 67 461 173640
Swap: 32767 0 32767
riv
Я вот нарыл топик аж от 2015 года https://forum.proxmox.com/threads/zfs_arc_max-does-not-seem-to-work.21315/
И там утверждается, что
Hi,
thanks you for showing this problem.
after changing this value you must update the init ram disk.
update-initramfs -u
zfs modules will load when the zfs.conf is not mounted.
so it will ignored.
that's why you must update it.
We will update the wiki.
Похоже сам дурак.
nanomechanic
неа, zfs в numa не может
это понятно, что не может. Я все жду, когда человек, которого оно анноит больше чем меня, напишет патч =)
nanomechanic
дак а то
 Nikolay
Nikolay
Я вот нарыл топик аж от 2015 года https://forum.proxmox.com/threads/zfs_arc_max-does-not-seem-to-work.21315/
И там утверждается, что
Hi,
thanks you for showing this problem.
after changing this value you must update the init ram disk.
update-initramfs -u
zfs modules will load when the zfs.conf is not mounted.
so it will ignored.
that's why you must update it.
We will update the wiki.
Похоже сам дурак.
кстати да, это где-то в вики прокса написано )
nanomechanic
если zfs.ko грузится в initramfs то не все параметры из /etc/modprobe.d поменяются
riv
кстати да, это где-то в вики прокса написано )
Чет я не подумал, раньше в дебиане и убунте оно точно в initram не попадало. Но, возможно это было давно.
nanomechanic
ну если zfs не корневая система, то и не поподало. для вкорячивания в initramfs у дебиана специальный апт-пакет
nanomechanic
а у прокса zfs.ko вместе с pve-ядром...
riv
ну если zfs не корневая система, то и не поподало. для вкорячивания в initramfs у дебиана специальный апт-пакет
Похоже при установки proxmox на debian это меняется. Для меня это неожиданность, т.к я никогда не использую zfs под root и всегда накатываю его на debian
George
это понятно, что не может. Я все жду, когда человек, которого оно анноит больше чем меня, напишет патч =)
а там выигрыш минимальный, потому никого и не анноит. pagecache тоже не особо куда привязан, т.к. доступ то может идти с любого проца. С zfs похожая история
riv
а что произойдет с памятью после echo 3 > /proc/sys/vm/drop_caches ?
Кстати, не думал, что это может сработать. Я считал, что zfs не подчиняется этому механизму linux
Sergei
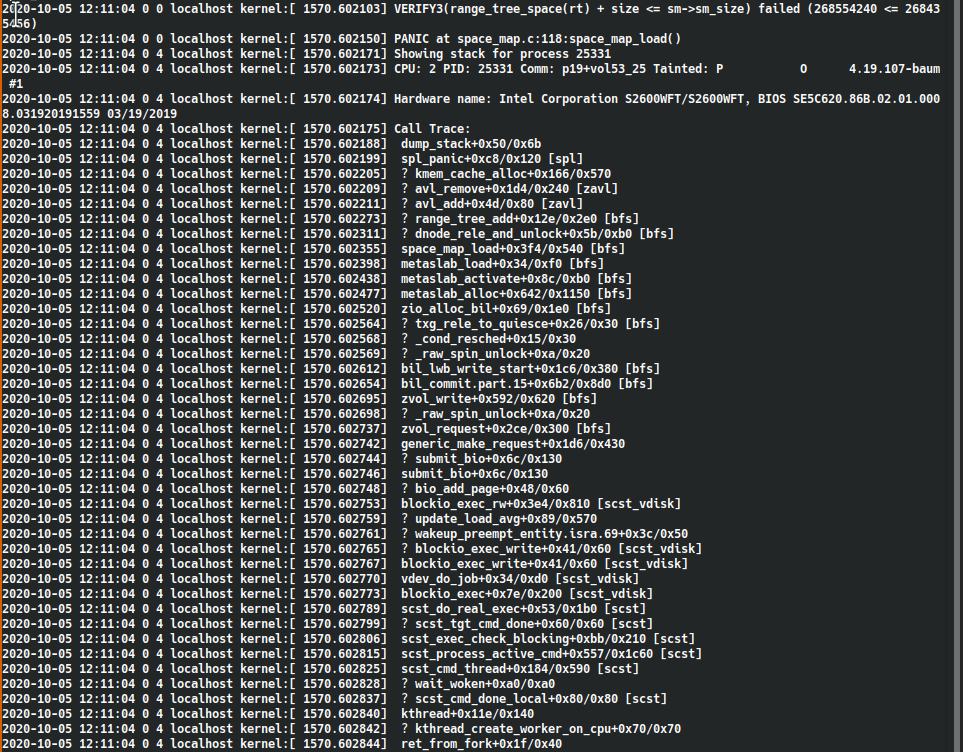
0.8.4 стабильнее 0.7.13 ?
Sergei
 Sergei
Sergei
https://github.com/openzfs/zfs/issues/8918 stale 😑
Sergei
нет, swap вовсе нет
George
0.8.4 стабильнее 0.7.13 ?
Там много фиксов было так то https://github.com/openzfs/zfs/releases
George
Можете откатиться потом, если что, главное zpool upgrade не делайте
George
В 0.8.4 лично для меня фикс один задевающий был, я бы рекомендовал обновляться без апгрейда пула. Выстрелит что - откат просто.
nanomechanic
а там выигрыш минимальный, потому никого и не анноит. pagecache тоже не особо куда привязан, т.к. доступ то может идти с любого проца. С zfs похожая история
я специально тестировал, что будет с производительностью постгресса в виртуалке, если поотрубать mitigations и в конце-концов запинил vCPU треды на pCPU ядро, в итоге, у меня pgbench постгресса в виртуалке выдавал производительность на 10% меньше чем на хосте (постгресс упирался в проц), последний шаг с cpu pinning дал прирост процентов 20. Если у тебя в это время zfs конкурирует за ресурсы, такого эффекта, понятно не будет. Будет совершенно непредсказуемая latency
nanomechanic
Больше всего анноит фрагментация памяти при наличии zfs
nanomechanic
Ну и проблемы с выделением максимальной памяти с одного нума узла одной жирной виртуалке: драйвера и потомков systemd я могу изолировать на тех ядрах, где они моим виртуалкам не помешают, а zfs - не могу :(
riv
Вот.
riv
Хочу всем напомнить, что никогда, даже так НИКОГДА нельзя доверять аппаратным рейдам, даже если это дорогущий сервер от HP.
zpool status -v
pool: VM
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://zfsonlinux.org/msg/ZFS-8000-8A
scan: scrub repaired 0B in 0 days 00:25:08 with 0 errors on Sun May 10 00:49:09 2020
config:
NAME STATE READ WRITE CKSUM
VM DEGRADED 0 0 0
scsi-3600508b1001037383941424344451400 DEGRADED 0 0 96 too many errors
errors: Permanent errors have been detected in the following files:
VM/vm-102-disk-0@backup-2020.06.13-09.30:<0x1>
<0x500>:<0x1>
<0x3700>:<0x1>
<0x2c01>:<0x1>
<0x3201>:<0x1>
<0x4401>:<0x1>
<0x1f02>:<0x1>
<0x2603>:<0x1>
<0xa04>:<0x1>
<0x1a05>:<0x1>
<0x2905>:<0x1>
<0x3d05>:<0x1>
...
VM/vm-102-disk-0:<0x1>
...
Это меня попросили посмотреть zfs с ошибками. Даю 99.9 гарантию, что даже если беды на обоих дисках, но рейд-массив был бы собран средствами zfs, а дорогущий рейд был бы использован как обычный HBA, то и данные были бы целы и работало все, скорее всего быстрее.
Грустно.
nanomechanic
если это хулетовская встройка, то да. дискии отпадают из-за каких-то багов с кэшем
 ivdok
ivdok
Собственно, поэтому и перешёл на LVM на время, потому что риски перевесили преимущества на текущем конфиге
Dmitry
пинаем провайдеров со всех сторон. Попробовали другого прова - там вообще 60Мбит )) при заявленном 1Гбит канале ))) Боль и печаль ((
Dmitry
Москва реально отделилась от России )) с хетцнером спокойно 1Гбит, с Красноярском - 150Мбит ))
Ivan
а через какой-нибудь wireguard та же скорость ?
 Vadim "Oxyd"
Vadim "Oxyd"
Москва реально отделилась от России )) с хетцнером спокойно 1Гбит, с Красноярском - 150Мбит ))
Ну не просто-же так существует это расхожее выражение, про «Москва не Россия» 😉
Dmitry
а через какой-нибудь wireguard та же скорость ?
на том конце там прод сервер, никто не будет туда его ставить
ivdok
Москва реально отделилась от России )) с хетцнером спокойно 1Гбит, с Красноярском - 150Мбит ))
Пробуйте мультипоток, реально какая-то хрень на трансграничном трафике
Dmitry
Пробуйте мультипоток, реально какая-то хрень на трансграничном трафике
каким образом можно zfs send/recv мультипотоком передать? Это был собственно мой первый вопрос несколько дней назад ))
Dmitry
И еще - на обоих концах FreeBSD 12.1
ivdok
каким образом можно zfs send/recv мультипотоком передать? Это был собственно мой первый вопрос несколько дней назад ))
Если один - хз, но если несколько - одновременно их запустить
ivdok
Так и пришлось мигрировать
Dmitry
Было бы еще круто с двух хостов с одинаковыми датасетами тянуть одновременно, но это уже совсем фантастика )
ivdok
В итоге для миграции Exchange пришлось поднимать DAG и делать реплику
ivdok
Ибо несколько тб баз я йопнусь с дедлайном переносить
ivdok
Gnu parallel не получилось заюзать, а надежды были
Mikhail
welcommen =)
 Алексей
Алексей
ребята всем привет. Мы все прекрасно знаем, что зфс медленно пишет когда у него в пуле заканчивается место. #Вопрос а что будет с записью в zvol если в нем заканчивается место, а в пуле его 50%? В zvol ntfs или ext
 Vladislav
Vladislav
тоже самое
Алексей
Вай вай печаль
Алексей
Зфс поверх зфс это вы месье знаете толк в извращениях
Vladislav
zvol, выделенная на виртуалку заполнилась почти на 95%
Vladislav
внутри виртуалки была ZFS
Алексей
Ну это не показатель
Vladislav
это показатель
Nikolay
а если на zvol не zfs ?
Алексей
Мене интересует если внутри ntfs или ext