 riv
riv


в гипервизоре в свойствах диска vm
Ivan
всегда пользую cache=none
Ivan
сейчас погоняю fio, посмотрю что к чему.
riv
Хм. просадка в 0 появлятся ведь когда zfs сбрасывает данные на диск, если к этому моменту память на буфер кончилась.
riv
А сколько vdev в пуле?
Ivan
пул состоит из raid10 на 34 диска + special + log
Ivan
памяти свободной гигов 130
riv
Значит просадка - это поведение самой винды. Она быстро сбрасывает данные на диск (а он их быстро поглащает), а потом начинает читать и в како-то момент винда это интерпретирует как скорость 0
riv
Вообще я такое тоже наблюдаю, даже на ssd-пулах (кроме optane ssd, там не замечал) но я специально с этим не боролся. А какой тип диска в виртуальных машинах? virtio scsi?
Ivan
тип диска virtioscsi с discard
riv
Я всегда думал, что это из-за writeback, я его использую (уже давно и ничего не упало), и по этому не боролся с этой виртуальной просадкой, т.к. считал, что без writeback средняя производительность будет в любом случае меньше, т.к. очередь к диску не будет заполняться, а без очереди, по идее, и iops-ов диски меньше выдают.
riv
По моему, 10-ка и на реальном железе ведёт себя так-же.
Ivan
Я всегда думал, что это из-за writeback, я его использую (уже давно и ничего не упало), и по этому не боролся с этой виртуальной просадкой, т.к. считал, что без writeback средняя производительность будет в любом случае меньше, т.к. очередь к диску не будет заполняться, а без очереди, по идее, и iops-ов диски меньше выдают.
на обычном и тонком lvm я наблюдал что в виндовых машинах с writeback неприлично вырастает latency, поэтому я отказался от использования writeback везде.
riv
ПК с мех диском нет под рукой, но даже на SSD видны эти "волны", хоть и не до 0 в данном случае.
riv
 riv
riv
на обычном и тонком lvm я наблюдал что в виндовых машинах с writeback неприлично вырастает latency, поэтому я отказался от использования writeback везде.
в zfs все сильно не так как в lvm. Приведу пример. Была система виртуализации с дисковой подсистемой на на 8-ми 15k RPM-дисках. И там был mdadm+lvm, снепшоты делали обычные, но только на время бекапа, потом сразу удаляли. Система при многопоточной нагрузке стала тупить, причем очень сильно. Тогда была ещё 6-я версия zfsonlinux и просто смена lvm на zfs сняла все проблемы производительности. Так я и заинтересовался zfs.
Если включить writeback, то данные будут мгновенно передаваться в пул и задержки не будут. Writeback в случае с zfs означает, что виртуалка получит сигнал об окончании записи, до того как данные покинут writeback-кэш zfs. Но сама zfs загрузит очереди дисков по возможности максимально. При заполненном буфере многие диски могут делать больше одной опреации ввода-вывода за оборот диска и кол-во iops могут вырастать в разы относительно незаполненной очереди.
А может быть попробовать включить writeback в порядке эксперимента?
riv
Неее, именно writeback должен переключить на соотвествующем vdev значение sync в disabled - в этом смысл.
riv
Это нужно проверить. Вдруг баг в интерфейсе
riv
при этом значение sync файловой системы в которой лежат vdev не должно на них наследоваться
 Fedor
Fedor
Кстати, синк олвейс это же каждая операция записи становится по поведению с точки зрения пула синхронной?
Fedor
Если хороший слог поставить, можно отказаться от рисков врайтбека при сохранении надёжности и приемлемой отзывчивости. Или путаю? @gmelikov
riv
С sync=disablrd тоже безопасное сочетание с той лишь оговоркой, что безопасное в данном случае имеется в виду, что базы данных не будут разрушены. Но если вы будите записывать большой поток транзакций, то например система может успеть записать 1000 транзакций и сообщить об этом наружу (другой системе), а после неожиданного отключения питания с потерей writeback-буфера, с базой все будет нормально, но может оказаться, что зафиксировано только 948-транзакций, а данные за последнюю секунду откатились. Время принудительного сброса writeback-буфера на диск настраивается, чем больше интервал, тем больше производительность, но и возможный откат увеличивается.
Я считаю, что если у вас файловое хранилище профилей пользователе, например, то writeback не только безопасен но и рекомендуется, чтобы снизить нагрузку и оставить запас для других операций по производительности. В случай с одиночной 1с, взаимодействующей с человеком - тоже 1-2 сек активности ничего не мешает. Но если это кластер, нужно уточнить как он относится или протестировать.
Fedor
Насколько слышал, во время сброса грязных страниц пул не обрабатывает другие операции.
riv
Кстати, синк олвейс это же каждая операция записи становится по поведению с точки зрения пула синхронной?
Да, верно. И, по помему, это вредная и часто бесполезная настройка. Вот в каком случае это нужно?
 George
George
Кстати, синк олвейс это же каждая операция записи становится по поведению с точки зрения пула синхронной?
sync=always только про целостность, не стоит пытаться при этом перформанс выжать. Да и нужно оно в редких случаях
Fedor
Fedor
Надо будет сесть смоделировать это вот все.
riv
Если хороший слог поставить, можно отказаться от рисков врайтбека при сохранении надёжности и приемлемой отзывчивости. Или путаю? @gmelikov
А что за риски, как вы их себе представляете? По моему, если не понятно как это работает, лучше оставить enable - оно так по умолчанию и настроено.
 Сергей
Сергей
Неее, именно writeback должен переключить на соотвествующем vdev значение sync в disabled - в этом смысл.
когда в последний раз вы видели чтобы опция настройки диска для ВМ в проксе меняла тип синхронизации для zvol? (writeback -> sync=disabled)
Fedor
Физический оборудования или питания
riv
И ещё. Если вы пишите линейно, то это при sync=enable не попадает в slog, но это и не страшно, т.к. переключение на slog не даст выигрыша, в линейной скорости массив и дисков часто не уступает, а бывает и превосходит при долговременной нагрузке SSD
riv
когда в последний раз вы видели чтобы опция настройки диска для ВМ в проксе меняла тип синхронизации для zvol? (writeback -> sync=disabled)
Я, честно говоря не понмню. У меня смутное воспоминание, что я это проверял, на заре знакомства с zfs и proxmox. Если это не так, то это для меня сюрприз. Щас проверю. АИ в чем тогда смысл writeback? Я всегда считал что это только к синхронных операциям и относится.
Сергей
когда в последний раз вы видели чтобы опция настройки диска для ВМ в проксе меняла тип синхронизации для zvol? (writeback -> sync=disabled)
и второй вопрос, вытекающий из этого. Если у меня для диска в ВМ задано writeback, а сам диск организован как LVM thin - то что по-вашему изменит опция "writeback" в части настроек LVM thin? (я исхожу из утверждения что эта опция меняет параметр sync для zvol)
Сергей
Я, честно говоря не понмню. У меня смутное воспоминание, что я это проверял, на заре знакомства с zfs и proxmox. Если это не так, то это для меня сюрприз. Щас проверю. АИ в чем тогда смысл writeback? Я всегда считал что это только к синхронных операциям и относится.
нет. это никогда к zfs и не относилось
riv
и второй вопрос, вытекающий из этого. Если у меня для диска в ВМ задано writeback, а сам диск организован как LVM thin - то что по-вашему изменит опция "writeback" в части настроек LVM thin? (я исхожу из утверждения что эта опция меняет параметр sync для zvol)
я только про zfs говорил, не про lvm Я так понимаю, что для каждого хранилища отдельная реакция. Но я сейчас проверю...
Сергей
я только про zfs говорил, не про lvm Я так понимаю, что для каждого хранилища отдельная реакция. Но я сейчас проверю...
нет. "Реакция на опцию" происходит на уровне взаимодействия между KVM/QEMU и файловой системой:
https://pve.proxmox.com/wiki/Performance_Tweaks
это не мешает KVM/QEMU например отказаться от выполния fsync и тем самым достичь того о чём вы пишите, но не через изменение параметров zvol
riv
нет. "Реакция на опцию" происходит на уровне взаимодействия между KVM/QEMU и файловой системой:
https://pve.proxmox.com/wiki/Performance_Tweaks
это не мешает KVM/QEMU например отказаться от выполния fsync и тем самым достичь того о чём вы пишите, но не через изменение параметров zvol
Вы полностью правы, оно не влияет на sync вообще. Тут есть о чем подумать...
Ivan
https://bsdio.com/fio/
а что с fio случилось ? он просто ни на что не реагирует, хоть fio ekjheuheirufherigfhe ему пиши
riv
нет. "Реакция на опцию" происходит на уровне взаимодействия между KVM/QEMU и файловой системой:
https://pve.proxmox.com/wiki/Performance_Tweaks
это не мешает KVM/QEMU например отказаться от выполния fsync и тем самым достичь того о чём вы пишите, но не через изменение параметров zvol
Интересно, если kvm убивает fsync в очереди то zfs о нем и не узнает и порядок записи может быть перепутан, а это может вызовать повреждение файловой системы.
Ivan
что-то с новыми билдами не так или пользоваться разучился ?
Сергей
то что вы описываете через sync=disabled достигается тем, что KVM/QEMU "забывает" про fsync и пишет всё по-сути асинхронно
Сергей
Интересно, если kvm убивает fsync в очереди то zfs о нем и не узнает и порядок записи может быть перепутан, а это может вызовать повреждение файловой системы.
я думаю что это учтено и там не будет ошибок. Просто на zvol с опцией writeback не будет операций требующих синхронную запись. Поэтому эффект будет достигнут, но без необходимости менять свойства zvol
riv
то что вы описываете через sync=disabled достигается тем, что KVM/QEMU "забывает" про fsync и пишет всё по-сути асинхронно
Но, вероятно это лучше, чем на уровне qemu. Например, если виртуалка "навернулась", записанные в пул данные будут записаны на диск, при sync=disabled, но с отключенным writeback. А если сделать наоборот, умрут вместе с процессом qemu?
George
Writeback это не про синхронность, а про o_direct же
Сергей
Writeback это не про синхронность, а про o_direct же
про оба:
cache=writeback
host do read/write cache
guest disk cache mode is writeback
Warn : you can loose datas in case of a powerfailure
you need to use barrier option in your linux guest fstab if kernel < 2.6.37 to avoid fs corruption in case of powerfailure.
This mode causes qemu-kvm to interact with the disk image file or block device with neither O_DSYNC nor O_DIRECT semantics,
so the host page cache is used and writes are reported to the guest as completed when placed in the host page cache,
and the normal page cache management will handle commitment to the storage device.
Additionally, the guest's virtual storage adapter is informed of the writeback cache,
so the guest would be expected to send down flush commands as needed to manage data integrity.
Analogous to a raid controller with RAM cache.
Сергей
Writeback это не про синхронность, а про o_direct же
qemu не ставит ни O_DIRECT ни O_DSYNC при операциях записи.
George
А, тю, writethrough без o_direct
riv
я думаю что это учтено и там не будет ошибок. Просто на zvol с опцией writeback не будет операций требующих синхронную запись. Поэтому эффект будет достигнут, но без необходимости менять свойства zvol
Вообще к тому в каком порядке эти операции применяются надо внимательно относится. Приведу другой пример: тестировал ceph vs sheepdog на слабых серверах, еще с ddr2. На гигабитной сети производительность у ceph была так себе а sheepdog получше работало. Разница была в том как они были настроены: ceph отдавал информацию о завершении записи после того как получал сигнал от всех osd что данные записаны. А sheepdog можно настроить так, что данные будут считаться записаны после того как они оказались во writeback буфуре удаленных нод, но не на диске. Т.к. единовременное отключение целого датацентра представляется маловероятным, это, на мой взгляд не плохой компромисс. Жаль что sheepdog выпилили из qemu недавно. И вообще, на фоне многочисленных потерь данных в ceph мне на понятно почему никто не пробует вернутся к sheepdog, он не показался мне настолько плохим.
ЗЫ: Я в фоновом режиме читаю переписку в русскоязычном канале ceph. Читаю и радуюсь что отказался от этого "счастья" в пользу zfs. Как же хорошо что мне эти муки с рассыповшимися пулами не касаются, как же хорошо спроектирована zfs 😊
Сергей
А, тю, writethrough без o_direct
а разве o_direct уже поддерживается? вроде его в 2.0 собирались добавить или я что-то пропустил?
https://github.com/openzfs/zfs/pull/10018
George
а разве o_direct уже поддерживается? вроде его в 2.0 собирались добавить или я что-то пропустил?
https://github.com/openzfs/zfs/pull/10018
я не в контексте zfs, это то верно, ещё не притащили
Сергей
я не в контексте zfs, это то верно, ещё не притащили
я понял. в части qemu/kvm - O_DIRECT используется при режиме cache=none
Сергей
а directsync ставит и O_DIRECT + O_DSYNC
Ivan
https://bsdio.com/fio/
а что с fio случилось ? он просто ни на что не реагирует, хоть fio ekjheuheirufherigfhe ему пиши
короч тут виндовые билды fio битые.
взял с другого сайта.
fio на чтение и запись малыми блоками показывает красоту неописуемую по сравнению с lvm на тех же hdd + аппаратный контроллер с кэшем и батарейкой.
riv
я понял. в части qemu/kvm - O_DIRECT используется при режиме cache=none
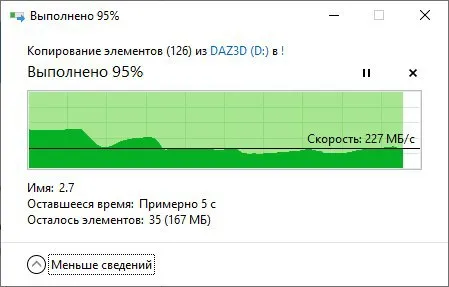
Ну а если вернуться к вопросу с которого началась дискусия. Может быть вы знаете, чем вызвана просадка в 0 при копировании файла проводником в вирутальной машине в пределах одного диска (да и разных по помему тоже)? И как этого избежать и чем придётся пожертвовать? Пользователи действительного говорят о подвисаниях в таком случае, имея в виду подвисание копирования.
riv
короч тут виндовые билды fio битые.
взял с другого сайта.
fio на чтение и запись малыми блоками показывает красоту неописуемую по сравнению с lvm на тех же hdd + аппаратный контроллер с кэшем и батарейкой.
Это не "бесплатно", если вы понимаете о чем я 😊
Ivan
Это не "бесплатно", если вы понимаете о чем я 😊
не понимаю о чем конкретно речь )
riv
не понимаю о чем конкретно речь )
zfs объективно сложен. Нужно изучить 300-страничное руководство по администрированию, кроме того, вырастает пиковая производительность, но сырая средняя все-же падает, без slog и special. Ещё нужна опративка в больших количествах, и во многих сценариях возникает двойное кэширование.
Сергей
Ну а если вернуться к вопросу с которого началась дискусия. Может быть вы знаете, чем вызвана просадка в 0 при копировании файла проводником в вирутальной машине в пределах одного диска (да и разных по помему тоже)? И как этого избежать и чем придётся пожертвовать? Пользователи действительного говорят о подвисаниях в таком случае, имея в виду подвисание копирования.
например ОС может делать flush и тем самым на хосте будет происходить сброс на диск. При опции writeback ОС внутри ВМ знает что на хосте использовался такой тип записи "writeback". Вот последний абзац:
Additionally, the guest's virtual storage adapter is informed of the writeback cache,
so the guest would be expected to send down flush commands as needed to manage data integrity.
Analogous to a raid controller with RAM cache.
Если ОС внутри ВМ заставить забыть про flush, то можно проверить действительно ли такая просадка связана с этим
riv
например ОС может делать flush и тем самым на хосте будет происходить сброс на диск. При опции writeback ОС внутри ВМ знает что на хосте использовался такой тип записи "writeback". Вот последний абзац:
Additionally, the guest's virtual storage adapter is informed of the writeback cache,
so the guest would be expected to send down flush commands as needed to manage data integrity.
Analogous to a raid controller with RAM cache.
Если ОС внутри ВМ заставить забыть про flush, то можно проверить действительно ли такая просадка связана с этим
Там не было writeback, а пул аж из 8 mirror как я понял + slog + special + 128GB RAM свободно. Я сомневаюсь, что одна виртуалка прогрузила такой пул.
Сергей
 Ivan
Ivan
zfs объективно сложен. Нужно изучить 300-страничное руководство по администрированию, кроме того, вырастает пиковая производительность, но сырая средняя все-же падает, без slog и special. Ещё нужна опративка в больших количествах, и во многих сценариях возникает двойное кэширование.
разбираюсь потихоньку. с вашей помощью )
про оперативку понятно. всё же рискну её несколько ограничить и создать кэшдевайс, посмотрю какова разница будет.
Ivan
кстати, log имеет смысл в зеркале держать ?
riv
Кэшироаться тоже будет только случайный io причем не так как linux это делает, запихивая в кэшь все подряд, вымывая часто используемые данные, а только после неоднократного чтения с диска и случайного io.
Сергей
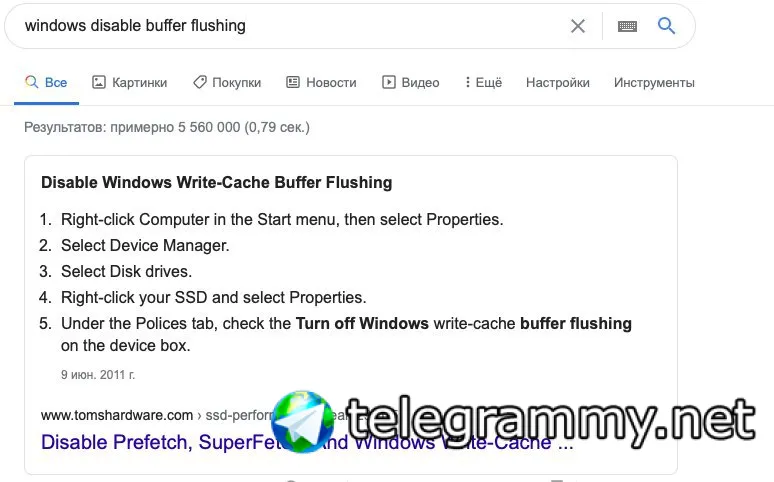
@simubishi, а вы попробуйте отключить buffer flushing в видне и проверить ещё раз копирование для разных параметров cache= для диска ВМ
riv
кстати, log имеет смысл в зеркале держать ?
Обязательно как и special, а вот кэш не нужно в mirror делать, можно два устройства отдать под кэш как два самостоятельных vdev
Сергей
Там не было writeback, а пул аж из 8 mirror как я понял + slog + special + 128GB RAM свободно. Я сомневаюсь, что одна виртуалка прогрузила такой пул.
и даже в таком случае виртуалка может послать flush на хост. Там какой размер файла копировался?
Ivan
Сергей
4г
есть возможность отключить buffer flushing на винде (скриншот выше, либо погуглить) и проверить ещё раз?
Ivan
сейчас сделаю. а тестировать со всеми видами кэширования вм диска ?
riv
Так как меня это тоже волнует я сейчас на своем пуле протестирую.
Сергей
сейчас сделаю. а тестировать со всеми видами кэширования вм диска ?
хотя бы для начала с двумя: cache=none и cache=writeback
Сергей
сейчас сделаю. а тестировать со всеми видами кэширования вм диска ?
ну и настройки zvol оставить по умолчанию sync=standard, logbias=latency, volblock=8K
Сергей
если возможно - выложить сюда результаты, у меня +2МСК, и я с дороги. Прошу понять и простить) - хочу немного поспать. Утром посмотрю
Ivan
раз уж мы наблюдлаем за поведением виндового проводника, дам текстовый комментарий с результатами.
riv
раз уж мы наблюдлаем за поведением виндового проводника, дам текстовый комментарий с результатами.
А сколько оперативки выделили виртуальной машине? Просто я сейчас подумал о кэшировании, наверное надо копировать файл больше чем размер ОЗУ в виртуальной машине.
Ivan
8 гигов выдал
riv
выдам тогда 4, для разнообразия.