 Igor
Igor


тут да
riv
vdev removal работает только в пулах БЕЗ raidz, очень важно этот не забыть)
А что будет, если specia vdev удалён, а потом в пул добавили другой special меньшего объема чем предыдущее, но большего, чем на неё данных было?
Это не ради любопытства вопрос. У меня есть большой пул 30ТБ, под бэкапы. В принципе, эти бэкапы не очень критичны, но, разумеется просто так их стирать не хотелось бы. В пул, для срочного решения проблем производительности было добавлено 4 special vdev каждый из одного (не mirror и не raidz) SATA 100ГБ intel DCS3700.
Теперь проблема в том, что в сервере нет больше места под новые SSD. Кроме того, хотелось бы заменить 4 отдельных special vdev на один большой raidz1. Я готовлюсь к пересборке пула, но мне придётся куда-то деть 30ТБ данных. Через интернет в облака гонять долго, хотя в аренду диски бери 😊. Но может быть можно опереться на vdev removal? Но как это сработает? Я не понимаю механики возврата vdev и ни разу не пробовал.
 George
George
А что будет, если specia vdev удалён, а потом в пул добавили другой special меньшего объема чем предыдущее, но большего, чем на неё данных было?
Это не ради любопытства вопрос. У меня есть большой пул 30ТБ, под бэкапы. В принципе, эти бэкапы не очень критичны, но, разумеется просто так их стирать не хотелось бы. В пул, для срочного решения проблем производительности было добавлено 4 special vdev каждый из одного (не mirror и не raidz) SATA 100ГБ intel DCS3700.
Теперь проблема в том, что в сервере нет больше места под новые SSD. Кроме того, хотелось бы заменить 4 отдельных special vdev на один большой raidz1. Я готовлюсь к пересборке пула, но мне придётся куда-то деть 30ТБ данных. Через интернет в облака гонять долго, хотя в аренду диски бери 😊. Но может быть можно опереться на vdev removal? Но как это сработает? Я не понимаю механики возврата vdev и ни разу не пробовал.
- vdev removal работает хитро и с оверхедом (он пишет таблицу сопоставлений по блокам, которые были на старом диске iirc), учитывайте это
- новые блоки, соответствующие условиям записи на special, поедут на него
- special vdev из raidz НИ В КОЕМ СЛУЧАЕ) да и мб он и не позволит сейчас такое собрать, не помню. Просто весь смысл iops побольше получить пропадает, raidz не про иопсы ни разу
George
Я бы по возможности vdev removal не пользовался, с ним всё ок, но это немного костыль, честно говоря, со своим оверхедом
riv
- vdev removal работает хитро и с оверхедом (он пишет таблицу сопоставлений по блокам, которые были на старом диске iirc), учитывайте это
- новые блоки, соответствующие условиям записи на special, поедут на него
- special vdev из raidz НИ В КОЕМ СЛУЧАЕ) да и мб он и не позволит сейчас такое собрать, не помню. Просто весь смысл iops побольше получить пропадает, raidz не про иопсы ни разу
Я знаю все проблемы raidz, я работал с ним и отказался от использования raidz для механических дисков. Но вот последнее утверждение, я думаю, имеет смысл проверить. Может быть это будет работать на удивление хорошо. Я так говорю, по тому, что бывают случай иногда нам нужно или пойти на компромисс, или, условно потратить пол миллиона рублей. Понятно, что лучше делать лучше, и не делать хуже. Но в данном случае, быть может, производительности vdev хватить и реальное снижение быстродействия не повлияет на функции хранилища. Почему я так считаю? raid-z нормально работает с ssd. Оверхед я не мерял. Но со cpecial ситуация другая. Если его производительности хватает, то не важно сколько iops ещё есть в запасе, от увеличения этого запаса, хранилище не ускорится. А медленное место там raidz1 и 5 х 8ТБ дисков. При создание 4-х special vdev, zfs мне сообщила, что special vdev должен быть _того же_ уровня что и основные, т.е. в моем случае raid-z1. С другой стороны, на special падает такая нагрузка, которая для SSD просто детская.
Посмотрите на средние iops
root@plt-backup:~# zpool iostat -v hdd-big2
capacity operations bandwidth
pool alloc free read write read write
--------- ----- ----- ----- ----- ----- -----
hdd-big2 33,2T 3,33T 12 436 83,1K 4,10M
raidz1 32,9T 3,30T 3 252 39,5K 3,04M
sdl - - 0 54 7,87K 622K
sdh - - 0 49 7,95K 623K
sdj - - 0 49 7,90K 623K
sdn - - 0 49 7,89K 623K
sdm - - 0 49 7,90K 623K
special - - - - - -
special1 86,1G 6,44G 3 57 17,6K 344K
special2 81,2G 11,3G 2 57 12,8K 348K
special3 58,5G 5,04G 1 31 6,31K 175K
special4 58,3G 5,23G 1 38 6,86K 216K
cache - - - - - -
cache 6,33G 19,7G 3 0 23,9K 50,6K
--------- ----- ----- ----- ----- ----- -----
root@plt-backup:~# uptime
15:58:26 up 19 days, 10:06, 1 user, load average: 0,02, 1,46, 3,05
 Nikolay
Nikolay
Можно подвести итог: для special, slog. cache можно/желательно использовать 2 nvme или ssd (nvme мой сервер не видит) эти два диска в zfs mirror и делить на партиции.
Я правильно резюмировал ?)
Nikolay
@Riv1329 У нас файловый сервер есть, ~50Тб. С него фильмы смотрят. И стало не хватать на отдачу в какой-то момент. Тогда и добавили cache в пул, он "нагревается" и наиболее часто используемые данные отдаёт быстрее, нагрузка с hdd снизилась. Фильмы перестали лагать при просмотре. Потому я и сказал что он для ускорения чтения предназначен. И ваш ответ выше что "на него пишется в основном, а читается редко" меня смутил. И сейчас я тоже в непонятках )
riv
Можно подвести итог: для special, slog. cache можно/желательно использовать 2 nvme или ssd (nvme мой сервер не видит) эти два диска в zfs mirror и делить на партиции.
Я правильно резюмировал ?)
Хочу добавить. Для special вам точно хватить SATA или SAS, лучше обратите внимание на то cколько записи может пережить SSD. И ещё, special очень маленький, всего 1% с не большим запасом, возьмите 1,1%, а пользы от него намного больше чем от гигантского cache. log тоже очень маленький, и он почти всегда будет у вас пустым. Он тоже менее важен чем special.
И ещё про NVME. Нагрузка на SSD у вас будет ограничена средней производительность дисков, а так как по iops она не большая, вы никогда не упретесь в потолок по iops SATA или SAS. Я думаю, что nvme тут избыточен. Может быть если бы у вас основные vdev были на SATA SSD, тогда, да, для ускорения нужен был бы optane nvme.
Но! Есть такие SSD которые рассчитаны на чтение, и у них очень низкая производительность по записи, например 5 000 iops, но высокая по чтению (90 000 iops) и низкая наработка на отказ по TBW - это не ваш выбор, лучше взять SSD меньшего объема, но true enterprice типа S3700 или P3700 (если говорить о NVME)
riv
@Riv1329 У нас файловый сервер есть, ~50Тб. С него фильмы смотрят. И стало не хватать на отдачу в какой-то момент. Тогда и добавили cache в пул, он "нагревается" и наиболее часто используемые данные отдаёт быстрее, нагрузка с hdd снизилась. Фильмы перестали лагать при просмотре. Потому я и сказал что он для ускорения чтения предназначен. И ваш ответ выше что "на него пишется в основном, а читается редко" меня смутил. И сейчас я тоже в непонятках )
Извините, я вас запутал. cache - для чтения. У вас всё правильно. а special для ускорения всего и особенно записи, но сам работает почти исключительно на запись, причем он маленький, а ускоряет сильно, т.к. снимает случайную нагрузку по записи метаданных с основных дисков. Ускорение многократное. Но сам special не сильно то напрягается почему-то. десятки, или 200 -300 iops в среднем, или до 1000 в пике.
Alexandr
@banofboot
 Владимир
Владимир
 Владимир
Владимир
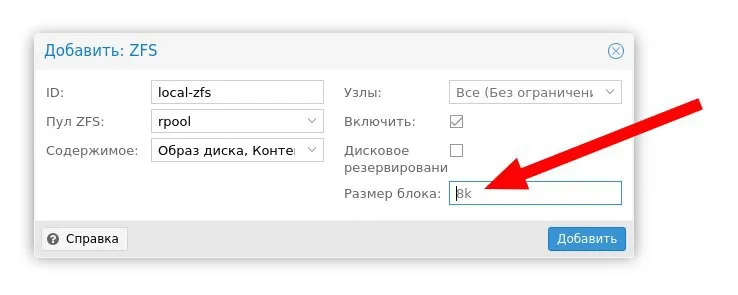
Размер блока оказывается задаётся при создании хранилища)
Владимир
Может кто даст рекомендацию есть ли смысл менять размер блока. На виртуалках будут крутиться контейнеры, nginx, мускуль, php
George
Может кто даст рекомендацию есть ли смысл менять размер блока. На виртуалках будут крутиться контейнеры, nginx, мускуль, php
обычно есть смысл подумать о 16к или больше блоке, но надо понимать, что чем больше блок - тем выше latency, но меньше накладных расходов и выше пропускная способность. Плюс write amplification - изменение даже 1 бита потребует вычитать весь блок и записать его.
Нормальный размер arc обычно оверхед на вычитывание успешно покрывает. Write amplification придётся учитывать, он на синхронной записи будет во всей красе.
А так - тестируйте вашу нагрузку и средний размер блока, после этого решайте
 Сергей
Сергей
Может кто даст рекомендацию есть ли смысл менять размер блока. На виртуалках будут крутиться контейнеры, nginx, мускуль, php
т.е. сначала будет ВМ, а уже внутри её будут контейнеры? И точно также с mysql - он будет работать внутри ВМ?
Владимир
да
 ivdok
ivdok
лёгких путей вы не ищите.... добавлять слой виртуализации, особенно для СУБД)))
А почему нет, собственно говоря, если сценарий использования - по инстансу СУБД для каждого клиента?
ivdok
Не делать же одну большую монолитную БД, и всем по учёточке?
Сергей
А почему нет, собственно говоря, если сценарий использования - по инстансу СУБД для каждого клиента?
если речь про проксмокс - то есть контейнер, в котором СУБД будет работать быстрее чем внутри ВМ. Вы просто ради интереса померяйте pg_bench для PG на хосте, внутри контейнера и внутри VM.
ivdok
если речь про проксмокс - то есть контейнер, в котором СУБД будет работать быстрее чем внутри ВМ. Вы просто ради интереса померяйте pg_bench для PG на хосте, внутри контейнера и внутри VM.
Я знаю про разницу в производительности, но нужна изоляция данных. Даже теоретической вохможности залезть в область памяти чужой БД у тенантов быть не должно. А у контайнеров пока не всё так радужно с безопасностью и изолированностью от хоста и других контейнеров
Сергей
Я знаю про разницу в производительности, но нужна изоляция данных. Даже теоретической вохможности залезть в область памяти чужой БД у тенантов быть не должно. А у контайнеров пока не всё так радужно с безопасностью и изолированностью от хоста и других контейнеров
я вас могу понять как "продавца" виртуальных машин (и полностью с вами наверное соглашусь). Только под свои задачи я не буду брать СУБД внутри ВМ, или придётся "озолотить" провайдера за требуемые мне показатели. Кластер из бареметалл дешевле будет собрать.
Alexandr
ну если нет возможности вынести БД за пределы VM то хотябы сделайте отдельный пулл для БД с маленьким размером блока
Igor
Может кто даст рекомендацию есть ли смысл менять размер блока. На виртуалках будут крутиться контейнеры, nginx, мускуль, php
если база не громадная - плевать. Вообще что єто за размер блока? recorsize? Разве вы не создаете сначала датасеты, а потом добавляете их в прокс?
Владимир
громандная
Владимир
неколько десятков гб
Сергей
если база не громадная - плевать. Вообще что єто за размер блока? recorsize? Разве вы не создаете сначала датасеты, а потом добавляете их в прокс?
это zvol на котором лежит образ виртуальной машины, там не recsize, а vol block. recsize можно было бы использовать для датасетов, которые созданы под размещение файлов СУБД (если бы СУБД была в контейнере или на самом хосте)
 Fedor
Fedor
Должно зависеть от запросов, по хорошему
Fedor
Вдруг там джойны с перемножением весом под сотню гб 😁
riv
Может кто даст рекомендацию есть ли смысл менять размер блока. На виртуалках будут крутиться контейнеры, nginx, мускуль, php
Фактически это значение записывается в настройки проксмокс, а не zfs. А потом, когда проксмокс создаёт zvol, она исползует это значение для выбора размера блока, который эквивалентен значению recordsize для файловых систем и задается в момент создания zvol для каждого zvol индивидуально. Таким образом, эта настройка в proxmox сделана концептуально не правильно. Что поделаешь, программисты - не админы 😞
Вы можете поменять эту настройки и новые zvol будут создаваться в этом хранилище с другим размером блока.
Большинство файловых систем и баз данных работаю с размером блока 8к, включая ntfs, mssql и 1с файловый вариант, они выравнивают структуры данных на границу 8к блока. Если вы измените этот параметр на 16к, то надо и в ntfs указывать unitsize=16k (Это можно сделать для системного диска во время инсталляции, после создания разделов через повторное форматирование из командной строки вызванной по shift-f10).
Если для базы данных, расположенной на хорошей SSD (intel optane серверный или обычный вариант), вы измените zvol blocksize с 8k на 16k, переформатируете ntfs на unitsize =16k и измените размер страницы в файловой базе данных 1с, то задержка загрузки снизится как минимум в 2 раза, но снимки станут потреблять больше места. Лично я, когда есть возможность, заморачиваюсь и так и делаю, ставлю везде 16k. В остальных случаях надо тестировать, может и медленнее сделать, ведь и кэш диска в ОЗУ расходуется быстрее и его может на что-то важно не хватить. Тут надо пробовать и экспериментировать.
Nikolay
т.е. сначала будет ВМ, а уже внутри её будут контейнеры? И точно также с mysql - он будет работать внутри ВМ?
у меня есть vm -> docker -> mssql :)
Nikolay
Поправьте если я ошибаюсь, после вникания в базовые понятия zfs:
1) disk-based sector size - физический размер сектора у диска (512б, 4кб, 8кб ...) зависит от диска. Тут ничего сделать не можем.
дальше идут абстракции zfs так понимаю:
2) zfs sector size - zfs использует свой размер сектора когда пишет/читает данные. zfs sector - минимальный размер данных для чтении/записи на диск (атомарный так скажем). Определяется свойством ashift. zfs sector может включать несколько hdd sector в себе.
3) zfs block size - собственно размер (кусок) данных, которым zfs непосредтвенно пишет/читает наши данные. определяется свойством recordsize. Допустим: 128кб, значит будет считано 32 4кб zfs sector-ов (при ashift = 12) и 8*32=256 hdd-sector-ов по 512б.
Вот )
Сергей
Поправьте если я ошибаюсь, после вникания в базовые понятия zfs:
1) disk-based sector size - физический размер сектора у диска (512б, 4кб, 8кб ...) зависит от диска. Тут ничего сделать не можем.
дальше идут абстракции zfs так понимаю:
2) zfs sector size - zfs использует свой размер сектора когда пишет/читает данные. zfs sector - минимальный размер данных для чтении/записи на диск (атомарный так скажем). Определяется свойством ashift. zfs sector может включать несколько hdd sector в себе.
3) zfs block size - собственно размер (кусок) данных, которым zfs непосредтвенно пишет/читает наши данные. определяется свойством recordsize. Допустим: 128кб, значит будет считано 32 4кб zfs sector-ов (при ashift = 12) и 8*32=256 hdd-sector-ов по 512б.
Вот )
volblock != recsize. не забывайте что zfs умеет делать блочные устройства, размер блока в которых задаётся через volblock. А в остальном - всё верно
George
Если кому интересны подкасты - поговорили о zfs, её внутренностях, проекте openZFS https://sdcast.ksdaemon.ru/2020/09/sdcast-122/
Fedor
Если кому интересны подкасты - поговорили о zfs, её внутренностях, проекте openZFS https://sdcast.ksdaemon.ru/2020/09/sdcast-122/
Супер, с удовольствием послушаю.
Олег
https://3dnews.ru/1020105 забавно
Сергей
https://3dnews.ru/1020105 забавно
осталось только скорость передачи с диска сделать функцией зависимой от маркетинга. Покупаешь годовую подписку на сервис - скорость считывания 500Мб/с. Покупаешь на 3Года - 1000Гб/с. Прикольненько так....
riv
riv
Но, если отбросить эмоциональное возмущение от обмана, в чем-то они правы. Конкретнее, они правы в том смысле, что их шаг идет на пользу потребителям. Продукция действительно становится дешевле, а уж как они прибыль переспределяют от разных сегментов не очень то и важно. Виноваты в этом потребители. Приведу, возможно более очевидный пример.
Я планировал для своего микробизнеса сделать сайт, продающий VPS. И конечно, я стал оценивать сложность создания конструктора. В моем понимание, конструктор должен честно передать смысл той или иной тарифной единицы и показать за что именно заплатит клиент. Я подумал, что у услуги должен быть примерно такой ряд параметров: производитель ядер процессора (amd/intel), тактовая частота, количество вычислительных потоков и ... такой важный параметр, как допустимая нагрузка на гипервизор в час пик. Условно, кому важнее больше и дешевле, могут потерпеть снижение производительности в это время, а кто-то может заплатить за то, чтобы размещение виртуальных машин было менее плотное, далее к виртуальной машине подключались дисковые устройства с разного рода ограничениями: для системы, для баз данных, для профилей и т.д. Более жесткие ограничения, например по iops позволяли сделать услугу дешевле для тех кому она подходила... в общем, получался такой инструмент, где над каждым параметром надо было подумать, все спланировать и можно было сильно сэкономить. Сильно - это в 2 раза, например...
Но меня осадили маркетологи, реальность оказалась такова: людям не интересно в этом во всем разбираться. Тариф должен быть простым: 2 ядра, 2 гига, 50 SSD или 4 ядра, 4 гига 100 SSD все. Никаких емких но медленных HDD, в крайнем случае, добавь линейку тарифов где будет 2 ядра 4 гига и 100 SSD например. И всё - это работает, а конструктор нужен единицам, на которых денег не сделаешь, а остальных он отпугнёт.
И с дисками так-же. Люди привыкли смотреть на RPM, думать ото, что сочетание (это просто предположение, я на само деле не знаю), например 7200RPM и черепичной записи - примерно тоже самое что и 5400RPM и обычной записи, никто не будет. По этому они пошли по пути AMD, начали создавать виртуальные параметры не связанные с тех. характеристиками дисков. Ну помните, AMD когда-то заявили, что частота не важна, и стали маркировать процессоры неким индексом производительности.
А по факту, нужно либо быть инженером-экспертом во все более сложных технология механических накопителей или просто послушать что говорит производитель про диски. Если диск предназначен для RAID то он так и промаркирован, кроме отсутствия черепичной записи, там ещё и устойчивость к вибрациям должна быть и, например по умолчанию отключен механизм вычитки плохо читающихся секторов и т.д., а с другой стороны, т.к. он в серверной, нагрев не так важен.
Я не одобряю их поведение, просто высказал мысль, почему их решения логичны и, что подобное поведение обосновано, к моему сожалению.
Igor
осталось только скорость передачи с диска сделать функцией зависимой от маркетинга. Покупаешь годовую подписку на сервис - скорость считывания 500Мб/с. Покупаешь на 3Года - 1000Гб/с. Прикольненько так....
Мне кажется что вброс и фейк. Я вскрыл указанные в статье коробочки всех видов и масте й за 2 года 20+. Там кругом все гелиевые хитачи (сейчас ВД). Они ОЧЕНЬ ТИХИЕ, ОЧЕНЬ ХОЛОДНЫЕ и выдают 200-220мег в сек в начале диска, что нереально мало для такой плотности на 7200
Alexandr
а мы сокро проверим этот "вброс"
Alexandr
там используется обычный 3х фазный двигатель, и не составит никакого труда измерить частоту сигнала поступающую на одну обмотку
Alexandr
и вычислить обороты
riv
Мне кажется что вброс и фейк. Я вскрыл указанные в статье коробочки всех видов и масте й за 2 года 20+. Там кругом все гелиевые хитачи (сейчас ВД). Они ОЧЕНЬ ТИХИЕ, ОЧЕНЬ ХОЛОДНЫЕ и выдают 200-220мег в сек в начале диска, что нереально мало для такой плотности на 7200
Кстати, а известно ли что-нибудь на сегодняшний момент про диффузию гелия? Я до сих пор избегаю гелиевых дисков, т.к. обычные могут проработать и 5 и 8 лет, а вдруг гелиевые превратятся в тыкву ровно через месяц после окончания гарантии?
Alexandr
на некторых дисках (в том числе WD Red) есть даже параметр в смарте, котрый показывает состояние гелия, обычно с ним ничего не происход, если диск не имеет механических повреждений (вмятин, даже маленьких)
Alexandr
мне еще недоводилось вскрывать геливы диск, но подозреваю что там есть датчик газа (гелия)
Fedor
я телефоном с включённым спектроанализатором дома гудение дисков мерял. даже подцепляться никуда не надо. кладёшь телефон на коробочку, и всё.
Fedor
мне еще недоводилось вскрывать геливы диск, но подозреваю что там есть датчик газа (гелия)
проще константное давление с завода, с которым сравнивается текущее. при разгерметизации давление к точным цифрам вернуть непросто
Alexandr
да, или так, возможно просто там датчик давления
Alexandr
это значительно дешевле чем датчик газа
Fedor
именно
Alexandr
но руки так и чешется распилить... но пока нечего)
Nikolay
#Вопрос Доброго. special vdev можно же присоединить после создания пула ? ssd для него пока в пути. А то насоздаю виртуалок, а окажется что нельзя и всё куда-то сливать придётся.
Nikita
Добрый день.
Прошу прощения, вопрос возможно глупый, но хочется экспертной оценки.
В усреднённой ситуации, добавление nvme ssd в какой роли даст наибольший выйгрыш в производительности?
- special
- кэш
- лог
И допустимо ли использование условного зеркала из двух nvme ssd, попиленного на три раздела под все три эти сущности сразу? Или при таком сценарии влияние на производительность будет скорее негативное?
На данный момент использую попиленный на два раздела nvme под лог и кэш, special пока нигде не применял. Насколько я понимаю, падение special-девайса приведет к потере всех данных, в отличие от потери выделенных девайсов под лог и кэш, и использовать носители без избыточности - крайне дурацкая затея.
 Konstantin
Konstantin
Если кому интересны подкасты - поговорили о zfs, её внутренностях, проекте openZFS https://sdcast.ksdaemon.ru/2020/09/sdcast-122/
я бы предложил закрепить сообщение в шапке
Fedor
Хорошая идея
Nikita
К сожалению, зачастую это 2-6 десктопных хдд на 1-2tb в raidz2.
К ним как правило добавляю вышеописанный nvme на 120 гиг, попиленный на два раздела - под log и кэш.
Пытаюсь оценить целесообразность и схему использования special.
Сергей
Олег
https://www.opennet.ru/opennews/art.shtml?num=53680
Олег
не знал)
George
https://www.opennet.ru/opennews/art.shtml?num=53680
опеннет в своём духе, 20+ комментов и ни один по теме)))
Nikita
памяти сколько на хосте?
В среднем - от 16-ти гигов, но есть исключения. От 8 до 64 разбежки.
George
Добрый день.
Прошу прощения, вопрос возможно глупый, но хочется экспертной оценки.
В усреднённой ситуации, добавление nvme ssd в какой роли даст наибольший выйгрыш в производительности?
- special
- кэш
- лог
И допустимо ли использование условного зеркала из двух nvme ssd, попиленного на три раздела под все три эти сущности сразу? Или при таком сценарии влияние на производительность будет скорее негативное?
На данный момент использую попиленный на два раздела nvme под лог и кэш, special пока нигде не применял. Насколько я понимаю, падение special-девайса приведет к потере всех данных, в отличие от потери выделенных девайсов под лог и кэш, и использовать носители без избыточности - крайне дурацкая затея.
- special - обязательно резервирование (потеря vdev приведёт к потере пула), снимает с основных vdevs нагрузки по записи/чтению метадаты (io мелким блоком)
- l2arc чисто про чтение, обычно сначала стоит ОЗУ докинуть нежели l2arc, т.к. он тоже на каждый блок отъест до 300байт ОЗУ
- slog чисто про синхронную запись
выбирайте что вам нужно, тестите, решайте
Сергей
В среднем - от 16-ти гигов, но есть исключения. От 8 до 64 разбежки.
для 16Гб - да, l2arc будет нелишним на пулах из ссд. Ну и в целом - идея достаточно разумная, сейчас nvme достаточно хорошо держат параллельную нагрузку. Поэтому разбивайте на разделы и подключайте. Но лучше всего делать зеркало, особенно для спешл и для SLOG
 Vladislav
Vladislav
https://www.opennet.ru/opennews/art.shtml?num=53680
А зачем? Все что нужно узнать о zfs и ее "контрибьюторах" понятно уже из формата представленной информации.
Я только не понимаю, почему какие-то древние "подкасты" вместо нормального тиктока?
Ну или если ценное знание вообще невозможно донести за 15 секунд - нормального ролика на ютубе, с хорошей монетизацией?
Alexander
- special - обязательно резервирование (потеря vdev приведёт к потере пула), снимает с основных vdevs нагрузки по записи/чтению метадаты (io мелким блоком)
- l2arc чисто про чтение, обычно сначала стоит ОЗУ докинуть нежели l2arc, т.к. он тоже на каждый блок отъест до 300байт ОЗУ
- slog чисто про синхронную запись
выбирайте что вам нужно, тестите, решайте
Вот с Озу почему то не работает))все время разное у нас
Олег
А зачем? Все что нужно узнать о zfs и ее "контрибьюторах" понятно уже из формата представленной информации.
Я только не понимаю, почему какие-то древние "подкасты" вместо нормального тиктока?
Ну или если ценное знание вообще невозможно донести за 15 секунд - нормального ролика на ютубе, с хорошей монетизацией?
тик ток это дичь, по хорошему его вообще забанить нужно. Никакого фильтра адекватности
Vladislav
с таким же успехом, можно это отнести к "подкастам"
Alexander
не работает что?
