 Иван
Иван


Кстати D3-S4610 норм? Выбираю между D3-S4610 и SM883 для небольшого филиального сервера.
 Сергей
Сергей
Кстати D3-S4610 норм? Выбираю между D3-S4610 и SM883 для небольшого филиального сервера.
я бы взял D3-S4610. У него получше с показателями и они ровнее
Сергей
допустим у меня будет ssd latency 1us, думаю огромной разницы заметно не будет, т.к. это только лог, а работа будет с хдд, в основном.
особенно разница будет заметна на fsync
Ivan
https://ark.intel.com/content/www/ru/ru/ark/products/134923/intel-ssd-d3-s4610-series-240gb-2-5in-sata-6gb-s-3d2-tlc.html
большое спасибо, по всем характеристикам гораздо интереснее самсунга. и дешевле при этом.
Сергей
интересно, если на гитхабе собирать такую коллекцию, бан не прилетит?
 Ivan
Ivan
интересно, если на гитхабе собирать такую коллекцию, бан не прилетит?
если брать модель, замерять и делиться результатами, то такое сложнее запретить
Ivan
а есть инфа по hba контроллерам подобная ?
Ivan
https://www.thomas-krenn.com/en/wiki/SAS_expander_backplane_performance_effects
Ivan
занятно, какраз с этим ссд и меряют
 George
George
допустим у меня будет ssd latency 1us, думаю огромной разницы заметно не будет, т.к. это только лог, а работа будет с хдд, в основном.
Проверять полезность slog можно отключив временно синхронную запись через sync=disabled и проверив разницу.
George
Плюс стоит смотреть на special allocation class для "взбадривания" hdd пула
Ivan
Плюс стоит смотреть на special allocation class для "взбадривания" hdd пула
вот только хотел спросить, можно ли его в прод )
George
вот только хотел спросить, можно ли его в прод )
Он в стейбле :) в issues по нему ничего особо нет по багам
Ivan
а как под него размер ссд посчитать ?
George
Технически это тот же vdev только с весами на запись конкретных типов инфы (меты, ddt, мелких блоков)
Сергей
а как под него размер ссд посчитать ?
если только для меты - до 1-3% от ёмкости пула будет достаточно, имхо
George
Был патчик чтобы через zdb можно было точные цифры посмотреть, не помню заехал ли уже
riv
да я если честно что-то начинаю возвращаться к мысли что програмный рейд + LVM отличный вариант)
Я, когда только начал изучать zfs и пробовал её, тестировпл производительность, с толкнулся с тем же самым и расстроился. Но по факту сравнения на боевой нагрузке я пришел к таким выводам:
- zfs по всем тестам сильно проигрывает mdadm + LVM связке.
- тем не менее, на реальной нагрузке, там где lvm уже давно лежит, zfs работает как ни в чем не бывало
- в реальной работе большой iops намного важнее большой линейной скорости
- чем больше vdev тем лучше всё работает. Но желательно чтобы их количество было кратно стемени двойки.
- raidzX не пригодны нигде, кроме как на сервере хранения резервных копий
Lvm + mdadm не используют контрольные суммы и транзакционную запись - это серьёзный оверхед. Контрольные суммы и транщакционностьтспасают от всего, вообще от всего: никаких разрушенеых баз данных, никаких рассыповшихся рейд-массивов, даже если у вас все диски с бед-блоками, вы узнаете об этом, но скорее всего данные не потеряете.
Lvm не управляет очередями из-за этого несколько линейных потоков записи могу поставить колом эту связку. А zfs очень мягко реагирует на рост многопоточной нагрузки.
LVM создает очень большой оверхед при резервном копировании. В zfs этой проблемы нет. Если вы не пробовали, то не знаете, что усилий по организации резервного копирования и нагрузки на оборудование будет буквально в 100 раз меньше.
В zfs есть кэширование на ssd и zfs разделяет нагрузку: линейное чтение происходит с дисков и не кешируется, мелкие файлы и базы данных осядут в кэше. Кроме того, можно использовать ввделенные устройства для метаданных и таблиц дедупликации.
Да, дедупликация в zfs может стать болью. Это хорошо работает только в редких специыических случаях. Но может очень сильно сократить потребление дискового пространства.
Ещё момент, если вы тестируете линейные нагрузки, поставьте recoredsize побольше: 64к, 128к или даже 1м.
 Владимир
Владимир
В zfs есть кэширование на ssd
Владимир
В LVMтоже
Сергей
да я если честно что-то начинаю возвращаться к мысли что програмный рейд + LVM отличный вариант)
а я вот собрал себе пул из 4xnvme (raid10) + i900p как slog и получил ~3-4Gb/s чтение и 2Gb/s на запись. Просто сказочные ощущения)). Postgres летает
riv
Ещё хочу заметить, что транзакционность, с одной стороны создаёт серьёзный оверхед, а с другой позволяет не использовать sync и можно перейти целиком на writeback-кеширование. Это приводик к неограниченному росту iops по записи. По сути, ваша запись становится всегда линейной. И это безопасно*
*Но надо понимать в каких случаях. Состояние на диске може откатится назад на несколько секунд. Если ваша система обменивается состоянием с другой системой, которая не сможет обработать такой откат, то от sync отказаться не получится.
Владимир
а я вот собрал себе пул из 4xnvme (raid10) + i900p как slog и получил ~3-4Gb/s чтение и 2Gb/s на запись. Просто сказочные ощущения)). Postgres летает
у меня пока не на столько серьёзные нагрузки на постгрес)). У меня в основном нагрузка на nginx))
riv
Zfs не всегда лучший выбор, но очень часто. Для меня основным приимущетвом являются: контрольные суммы - много раз это спасало и удобство тотального резервного копирования и управления резервными копиями.
Основным недостатком мне видится нарастание фрагментации на пулах, заполненных больше чем на 3/4. Дефрагментации нет.
Это отчасти компенсируется удобством и скоростью резервного копирования и восстановления: можно сделать копию прямо при работающей нагрузке, а потом слить накопившиеся изменения диференциально (в терминах microsoft такое копирование называется аддитивным). Восстанавливаются данные со скоростью копировпния на диск и часто в разы выше скорости сетевого соединения (за счет сжатия).
Вы можете просто уничтожить и восстановить пул из резервной копии вместо дефрагментации. Раз в год. Но для ssd-пулов это не актуально, зато очень актуален недавно появившийся trim
riv
Спасибо за очень ёмкий ответ), думаю он будет полезен не только мне
Незачто. Надеюсь, что информация будет полезна. Кстати, для вас, если иметьтв виду нагрузку postgres, как раз должен быть очень актуален writeback режим работы (отключение sync)
Прошу прощения за ошибки и опечатки.
Владимир
Это отчасти компенсируется удобством и скоростью резервного копирования и восстановления: можно сделать копию прямо при работающей нагрузке, а потом слить накопившиеся изменения диференциально
Владимир
но в LVMтоже так можно)
Владимир
Вот это в смысле?
Владимир
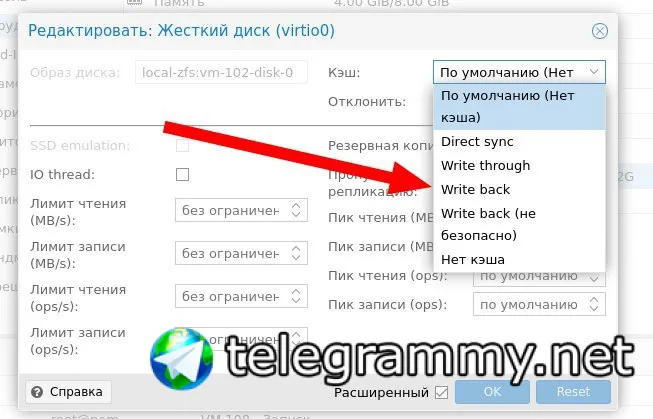 Владимир
Владимир
на сколько безопасно это проставить в уже созданном zvol
Владимир
Я так понимаю потребуется как минимум перезагрузка ОС? или это легко можно даже на живую?
Сергей
Владимир
только вы с этим по-аккуратнее. Тут важно чтобы у вас было понимание как поведёт себя система внутри виртуалки при внеплановом отключении. Если там живёт stateless система, то всё нормально.
там живут контейнеры с редисом и постгресом.Жестко привязанные к этой виртуалке из-за того что используют локальное хранилище
Владимир
И честно говоря я не до конца понимаю к чему это приведёт)
Владимир
Пока просто интересуюсь)
Сергей
И честно говоря я не до конца понимаю к чему это приведёт)
это приведёт к тому что ОС внутри ВМ будет считать что данные на диск уже записаны. А эти данные ещё не записаны на самом деле.
Владимир
в целом я могу поиграться на стейджинге)), если там не сломается попробовать на проде) С бекапами конечно)
Владимир
это приведёт к тому что ОС внутри ВМ будет считать что данные на диск уже записаны. А эти данные ещё не записаны на самом деле.
ну это я догадывался)). Аналогичным образом ведёт себя кеширование на LVM
Сергей
ну это я догадывался)). Аналогичным образом ведёт себя кеширование на LVM
ну если для вашей ОС и приложений (внутри ВМ) - это нормально переживаемая ситуация, то всё ок
Владимир
ну если для вашей ОС и приложений (внутри ВМ) - это нормально переживаемая ситуация, то всё ок
Ну если я буду упираться в скорость накопителя попробую). Пока у меня нет с этим проблем
George
но в LVMтоже так можно)
вопрос перформанса, у классического lvm очень большой оверхед на снапшоты
Владимир
ну так ты сделай клон, забыл как он там называется правильно и с него снимай снапшот
Ivan
вопрос перформанса, у классического lvm очень большой оверхед на снапшоты
и очень кэш не очень быстрый в lvm
George
ну так ты сделай клон, забыл как он там называется правильно и с него снимай снапшот
а как в такой схеме потом инкрементально второй снапшот собрать?
riv
но в LVMтоже так можно)
В LVM не ТАК :) представьте что вы делаете регулярно снимки тома и отправляете это все на сервер хранящий резервные копии. В zfs есть встроенные утилиты которые не дадут вам сделать что-то не так. Они проверяю что вы шлете, подходит ли это к уже переданным данным, есле передача прервется, вы (или скрипт) сможете её возобновить. Поддерживается сквозная консистентность.
George
В LVM не ТАК :) представьте что вы делаете регулярно снимки тома и отправляете это все на сервер хранящий резервные копии. В zfs есть встроенные утилиты которые не дадут вам сделать что-то не так. Они проверяю что вы шлете, подходит ли это к уже переданным данным, есле передача прервется, вы (или скрипт) сможете её возобновить. Поддерживается сквозная консистентность.
это ещё нативное шифрование не упоминали, в такой схеме сервер бекапов может работать без ключей, и при этом обеспечивать проверку целостности данных по чексуммам (да, scrub работает без ключей:)
riv
это приведёт к тому что ОС внутри ВМ будет считать что данные на диск уже записаны. А эти данные ещё не записаны на самом деле.
Важно ещё и то как эти данеые из кеша записыааются. В случае с LVM это обсалютно не безопасно. В случае с ZFS, поряжок записи таков, что восстановлпние будет точно таким же как и при отключенном writeback. Но разница в том, что zfs произведет небольшой откат. Т.е условно, 1с в виртуальной машине считает что проводка сохранена, а данные ещё в кеше. После неожиданного перезапуска гипервизора, окажется, что 1с база не повреждена, но проводка не сделана. Если у вас есть вторая сущность, например интернет-магазин со своей базой данных, с этого момента между ними может возникать недопонимание.
Если же вторая сущность - бухгалтер. Она должна проверить последние 5 сек до сбоя, что её операции отражены в базе даных.
Или, например, контроллер домена active directory в случае такого отката без проблем получит новые данные от домена. Он устойчив к откату.
Таким образом эта опция безопасна с точки зрения целосности данных, но безопасность её применения зависит от вышестоящей системы.
Сергей
Важно ещё и то как эти данеые из кеша записыааются. В случае с LVM это обсалютно не безопасно. В случае с ZFS, поряжок записи таков, что восстановлпние будет точно таким же как и при отключенном writeback. Но разница в том, что zfs произведет небольшой откат. Т.е условно, 1с в виртуальной машине считает что проводка сохранена, а данные ещё в кеше. После неожиданного перезапуска гипервизора, окажется, что 1с база не повреждена, но проводка не сделана. Если у вас есть вторая сущность, например интернет-магазин со своей базой данных, с этого момента между ними может возникать недопонимание.
Если же вторая сущность - бухгалтер. Она должна проверить последние 5 сек до сбоя, что её операции отражены в базе даных.
Или, например, контроллер домена active directory в случае такого отката без проблем получит новые данные от домена. Он устойчив к откату.
Таким образом эта опция безопасна с точки зрения целосности данных, но безопасность её применения зависит от вышестоящей системы.
всё верно. Уровень приложений должен понимать во что выльется такой "сбой". Вряд ли это ограничится одной проводкой - при выполнении операции в 1С это может быть несколько действий (если они не обёрнуты в одну транзакцию). В любом случае использовать writeback - это должно быть крайне осознанное решение
riv
всё верно. Уровень приложений должен понимать во что выльется такой "сбой". Вряд ли это ограничится одной проводкой - при выполнении операции в 1С это может быть несколько действий (если они не обёрнуты в одну транзакцию). В любом случае использовать writeback - это должно быть крайне осознанное решение
Я ещё хочу подчеркнуть. С точки зрения самой 1С все будет ок в случае с zfs и не ок (разрушенная база данных) в случае с LVM.
Но с точки зрения нескольких систем, возникнет впечатление, что одну из них восстановили из бекапа 5 секудного возраста. По умолчанию именно через 5 секунд zfs принудительео сбрасывает данные на диск, это можно настроить.
Одиночные 1с ки вседа нужно запускать с writeback. Если система работае в связке с другими системами, надо уточнять. Но, как правило, восстановление из резервной копии предусматривается в большинстве случаев.
Ещё момент. Если обе взаимодействующие системы на одном пуле, то все будет ок. Они откатятся вместе.
Ivan
При writeback игнорируется прямой запрос на запись от pg ?
Ivan
 Ivan
Ivan
насколько я понимаю, в таком режиме если pg захочет чтоб данные были обязательно записаны, он их запишет и убедится что это так. нет ?
George
насколько я понимаю, в таком режиме если pg захочет чтоб данные были обязательно записаны, он их запишет и убедится что это так. нет ?
нет, NEITHER o_dsync nor o_direct used
George
вообще я не уверен, что через gui прокс где-то ставит sync=disabled, выше именно про него говорилось
 ivdok
ivdok
ivdok
ivdok
 ivdok
ivdok
 George
George
ну вот, поймал толи дохнущий sata на матери, толи хреновый sata кабель, zfs конечно же спас данные. А на другой ФС бы и не узнал.
Ещё одна железобетонная причина не использовать что-то другое 🙈
Ivan
ну вот, поймал толи дохнущий sata на матери, толи хреновый sata кабель, zfs конечно же спас данные. А на другой ФС бы и не узнал.
Ещё одна железобетонная причина не использовать что-то другое 🙈
обычно ext4 становится ro.
не помню чтоб при подобных случаях терялись данные. возможно silent corruption и приключалось, но явных потерь заметно не было.
 Fedor
George
Fedor
George
обычно ext4 становится ro.
не помню чтоб при подобных случаях терялись данные. возможно silent corruption и приключалось, но явных потерь заметно не было.
Не, там только checksum errors были, ext4 бы не поймал сразу
 Nikolay
Nikolay
Это я удачно заглянул почитать. Посты выше очень интересные 👍
riv
насколько я понимаю, в таком режиме если pg захочет чтоб данные были обязательно записаны, он их запишет и убедится что это так. нет ?
Хочу дополнить про sync. Proxmox задает свойство sync zvol, в котором размещен диск виртуальной машины. Проще его вручную проверить. Он может быть: allways - как раз каждая операция завершается после непосредсвенной записи на диск; enable - данные сбрасываются по требованию sync, то есть writeback польностью не отключается. И вот тут надо ещё расказать про log-vdev. Если у вас есть ssd-диски под vdev для log, данные будут немедленно сброшены туда, это произойдет без задержки, т.к обычный write io не перенаправляется на log-vdev и он обычно рагружен, сразу после быстрой записи на ssd операция будет завершена и уже потом, эти данные будут перерапределены по обвсным vdev пула; и disabled в котором полный writeback и log-vdev бесполезен и простаивает (если нет других датасетов с sync=enable)
riv
обычно ext4 становится ro.
не помню чтоб при подобных случаях терялись данные. возможно silent corruption и приключалось, но явных потерь заметно не было.
Становится ro если получена writeerror. Я несколько раз видел, как диски enterprice-уровня перед смертью вместо write error или UNC при чтении записывали или считывали не верные данные. Тогда любая фс, в том числе и zfs с отключенными контрольными суммами, аппаратные и программные рейды умирают тихо и не заметно. Кроме того, ещё контрольные суммы помогут обнаружить умирающий контроллер, редкие ошибки в оперативной памяти и др.
Fedor
Периодический ресильвер может задетектить такой хард заблаговременно
riv
Да, может. Но без включенных контрольных сумм не сможет выбрать верную реплику данных.
Кстати, ещё одно отличие поведения zfs-реализации подсистемы raid от обычных программных и аппаратных масивов в том, что если контрольные суммы включены, то, обнаружив ошибочные данные в секторе, zfs их исправляет без сканирования всего пространства дискового массива, что может добить умирающие диски. И вообще, в zpool на всех дисках могу быть многочисленные ошибки, но вероятность потери данных всеравно очень мала. Для потери данных, надо чтобы относительные lba-адреса плохих секторов вточности совпали, а как правило, этого не происходит.
Что же касается обычных прграммных и аппаратных reid-массивов, то без сканировпния, они вообще не обнаружат такие ошибки, т.к для увеличения iops читается только одна реплика с каждого диска.
Fedor
Мне казалось, никто контрольные суммы не отключает.
Fedor
Иначе зачем это все - лучше уж лвм тогда 😁
Ivan
интересно, например для raid10 аппаратные контроллеры ведут какие-то контрольные суммы ?
Fedor
Ни разу не слышал такого
Владимир
они и не тримят)
Владимир
не то что контрольные суммы))
Fedor
Они другим способом ссд берегут
Владимир
без трима SSD проседают в производительности
Fedor
Не без трима, а когда остаётся мало неразмеченного пространства