U can try C×× Android
thanks, i'll try it
 Noble Friend
Noble Friend


 Swara
Swara
Ya sure
Anonymous
overload170.pdf
Anonymous
 Babasaheb
Babasaheb
#include <iostream>
#include <string.h>
using namespace std;
//function to remove trailing blanks,tabs and new line
//from the end of a string
void trim(char s[])
{
int n = 0;
for(n = strlen(s) -1; n>=0; n--)
(s[n] == ' ' s[n] == '\t' s[n] == '\n')? continue : break;
s[n+1] = '\0';
}
int main() {
char a[] = "hello world ";
return 0;
}
Babasaheb
why " (s[n] == ' ' s[n] == '\t' s[n] == '\n')? continue : break; " is a wrong statement ?
 Aquatica
Aquatica
why " (s[n] == ' ' s[n] == '\t' s[n] == '\n')? continue : break; " is a wrong statement ?
Because there is no logical operator between comparisons
Babasaheb
i have used "||" operation,but it is still wrong
Aquatica
i have used "||" operation,but it is still wrong
Oh. Telegram interpreted it as a spoiler tag
Babasaheb
https://pastebin.com/s99iKc51
Babasaheb
maybe it's a language bug
 Saro
Saro
why " (s[n] == ' ' s[n] == '\t' s[n] == '\n')? continue : break; " is a wrong statement ?
because break and continue are not expressions, they are statements
Saro
You can’t use statement as expression
Saro
you can do the same thing just writing
Saro
if(YOUR_CONDITION) break;
else continue;
 Hermann
Hermann
since I am simulating two protocols and that for some things some operations are similar, it would be too "dirty" to have in some cases a single method in which I put an if (protocol1) {do something} else if (protocol2) {do something else}
Babasaheb
Ok , i never know this rule
Saro
continue and break don’t evaluate a value
Saro
https://medium.com/@guven.seckin.4/the-difference-between-expression-and-statement-89e74596e546
You can read this
Babasaheb
Oh ,thanks to clarify that
Babasaheb
you are a good man,thank you
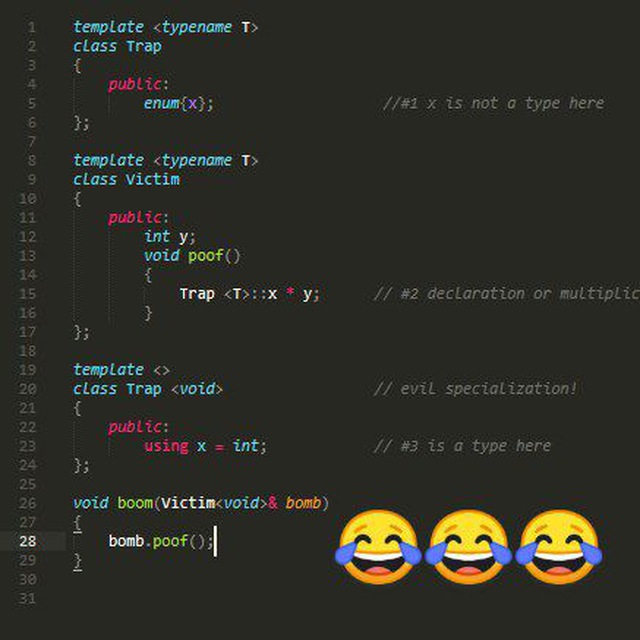 John
Anonymous
John
Anonymous
Can you recommend good Boot Camp of c /c++language !?
 Ludovic 'Archivist'
Ludovic 'Archivist'
The article on why std::unordered_map in the C++ standard library is slow because of the requirements placed by the standard (the bucket interface) and why the boost alternative is better is definitely worth reading.
The boost alternative is better only if you have no requirements on iterator invalidation and reference invalidation tho
Ludovic 'Archivist'
And personally, I kinda do not like the way the boost one works, it is not even that fast and doesn't even have good guarantees
Ludovic 'Archivist'
bytell is probably overall better but more annoying to implement https://github.com/skarupke/flat_hash_map/blob/master/bytell_hash_map.hpp
 Pavel
Pavel
I think the STL unordered map is good enough, in a sense that it's safe. If you go deep enough into optimization, you will choose 3rd party one anyway to match your needs.
Ludovic 'Archivist'
I think the STL unordered map is good enough, in a sense that it's safe. If you go deep enough into optimization, you will choose 3rd party one anyway to match your needs.
Yeah, it is just quite slow and it tends to fragment memory
******
Hello, how to read library pdf c++
BEHREDIN BIN NUREDIN
Ok
 0xJosh
0xJosh
Where can I get some sample Malwares source codes (if possible in c++) for studying?
I've searched the internet I couldn't find any..
If y'all have any ideas please help
 Stanislav
Anonymous
Stanislav
Anonymous
The boost alternative is better only if you have no requirements on iterator invalidation and reference invalidation tho
Why? How does any of boost's internal implementation change the requirements on invalidation rules?
Anonymous
bytell is probably overall better but more annoying to implement https://github.com/skarupke/flat_hash_map/blob/master/bytell_hash_map.hpp
Boost is working on a flat map implementation as well according to that article that I pointed out. This won't be burdened by the restrictions in the standard and I presume it will be much faster. But I haven't read about it or seen it to be able to comment on it.
Anonymous
And personally, I kinda do not like the way the boost one works, it is not even that fast and doesn't even have good guarantees
The point was that it is faster than the standard library implementations. Not the fastest overall.
Ludovic 'Archivist'
Why? How does any of boost's internal implementation change the requirements on invalidation rules?
It has quite a lot to do. The fact that it is a flatmap means that for example insertions may invalidate every single iterator. Some algorithms rely on stable iterator to work. I don't remember is deleting may also resize an under-filed map but that operates the same way.
Boost implementation of flatmap also has a not very good threshold, and hence a pretty bad memory efficiency. On large maps it also is susceptible to choking on long collisions due to its open addressing design with no mitigation against that except resizing to a bigger map and praying. I don't remember if it has Robinhood hashing to limit that a bit tho
Ludovic 'Archivist'
(I checked, it doesn't have Robin hood hashing)
Ludovic 'Archivist'
The last hash map I made mitigated that with geometric series for addressing instead of linear probing but even then it was only moderately better
Anonymous
It has quite a lot to do. The fact that it is a flatmap means that for example insertions may invalidate every single iterator. Some algorithms rely on stable iterator to work. I don't remember is deleting may also resize an under-filed map but that operates the same way.
Boost implementation of flatmap also has a not very good threshold, and hence a pretty bad memory efficiency. On large maps it also is susceptible to choking on long collisions due to its open addressing design with no mitigation against that except resizing to a bigger map and praying. I don't remember if it has Robinhood hashing to limit that a bit tho
The implementation that I am talking about (boost::unorderd_map) is not a flat map. It is just like the standard library ones using closed addressing and separate chaining. Instead of maintaining a link between all nodes in the map (like the standard library versions), it instead maintains a link between non empty buckets (the nodes within a bucket are linked because of separate chaining)...this is not a flat map exactly because of the non empty buckets inbetween (maybe your definition and my definition of a flat map are different). It does add some overhead in terms of the 64 bit mask for each bucket.
I still don't see how erasing invalidates existing iterators or references (except for the node that was deleted). A deletion would call for just updating the links in the nodes and if the element happens to be the last element in the bucket (which can be detected by on the fly hash computation of the next element), a traversal to the first element in the next bucket and returning an iterator to the same is still amortized constant time operation.
Anonymous
The last hash map I made mitigated that with geometric series for addressing instead of linear probing but even then it was only moderately better
Well if you use open addressing then your unordered map is not standard compliant because the standard requires a bucket interface for your map. This is exactly what Boost is gonna do with their flat map implementation using probing and hence I expect that to be faster
Ludovic 'Archivist'
Well if you use open addressing then your unordered map is not standard compliant because the standard requires a bucket interface for your map. This is exactly what Boost is gonna do with their flat map implementation using probing and hence I expect that to be faster
It is definitely faster on smaller sets but lags behind on maps of millions of elements due to collision clusters. But they don't seem to plan on implementing mitigations like I said before
Anonymous
Oh I thought you meant the Boost flatmap (which is already published AFAIK)
From the Overload journal that I shared earlier
<quote>In parallel, we are working on the future boost::unordered_flat_
map, our proposal for a top-speed, open-addressing container beyond
the limitations imposed by std::unordered_map interface. Your
feedback on our current and future work is very welcome</quote>
I don't see a unordered_flat_map in the Boost version that I am using (69)
Ludovic 'Archivist'
Oh fuck I am mixing it with the Google one
Ludovic 'Archivist'
I need to delve into the code of the mold linker
Ludovic 'Archivist'
And I do not want to
Ludovic 'Archivist'
I need to check how that shuffling works
Anonymous
I need to check how that shuffling works
Check it because you want to see if a particular section layout causes problems? I don't understand the reason behind that option unless you want to benchmark your code with randomised section layout in the executable just to ensure that the effects of the layout are taken away.
Anonymous
Just went through their documentation and also the code in passes.cc under elf to try and understand what the option does. But I got lost and realized that I need to spend more time on it than just a couple of clicks on my phone. The code is well organized but and also knowing that the author was the guy who implemented lld calls for more respect on my part.
Ludovic 'Archivist'
Check it because you want to see if a particular section layout causes problems? I don't understand the reason behind that option unless you want to benchmark your code with randomised section layout in the executable just to ensure that the effects of the layout are taken away.
That is exactly what I want. Since metacall is fairly big, it is to be expected that section layout will have consequences
Ludovic 'Archivist'
Consequences enough to make lots of benchmarks imprecise
Kriss
Can using pointers can fix my segmentation error?
Pavel
Can using pointers can fix my segmentation error?
Not enough information provided to answer your question
 Michel
Michel
Hi, I have this code here and I get this error when I compile using g++ 3.cpp -o 3.exe -Iodeint:
odeint/steppers/rk4.hpp:18:51: error: no match for ‘operator*’ (operand types are ‘double’ and ‘std::array<double, 4>’)
18 | variable_type k2 = f(x + 0.5 * dt * k1, t + 0.5 * dt);
| ~~~~~~~~~^~~~
(just an extract)
But clearly the operator is implemented as seen in line 17. Moreover, if I send the includes in lines 5,6 to lines just above main() I get the expected result.
What is happening there?
 itsmanjeet
itsmanjeet
Hey all,
I have a template class
template <typename... Ts>
class config{}
holds the map of string and variant of Ts...
Now i need to do
template<typename T>
T& config::get()
Is there any way i can check if T is in Ts...
Pavel
Hey all,
I have a template class
template <typename... Ts>
class config{}
holds the map of string and variant of Ts...
Now i need to do
template<typename T>
T& config::get()
Is there any way i can check if T is in Ts...
The first answer looks like a good solution
https://stackoverflow.com/questions/56720024/how-can-i-check-type-t-is-among-parameter-pack-ts
itsmanjeet
The first answer looks like a good solution
https://stackoverflow.com/questions/56720024/how-can-i-check-type-t-is-among-parameter-pack-ts
Exactly that one, thanks
Template pack is what I am missing in my google search
 /
/
What do it mean when you write if (!file) when file is not a boolean?
/
Is it to check if is null
/
Because i don't know what to search on internet
/
So it's to check if a variable is null
Pavel
What do it mean when you write if (!file) when file is not a boolean?
file can be an object with overloaded implicit operator bool, or it can be a pointer
/
file can be an object with overloaded implicit operator bool, or it can be a pointer
So it isn't always
/
file can be an object with overloaded implicit operator bool, or it can be a pointer
And what means when it's a pointer
Pavel
And what means when it's a pointer
Then it will be false, if the pointer is nullptr (NULL in C), or true otherwise.
It doesn't guarantee that it points to a valid object though. Depends on where you've got the pointer from
/
Then it will be false, if the pointer is nullptr (NULL in C), or true otherwise.
It doesn't guarantee that it points to a valid object though. Depends on where you've got the pointer from
So when it's an object without overloaded operator it always means not null
Pavel
So when it's an object without overloaded operator it always means not null
If it's an object without an overloaded operator bool, then this code shouldn't compile, I think
/
If it's an object without an overloaded operator bool, then this code shouldn't compile, I think
It doesn't mean the object is not null
Pavel
It doesn't mean the object is not null
Object can't be null, a pointer to an object can be
class A {};
A a; // object
A* a; // pointer
/
/
Anonymous
https://wtools.io/paste-code/bDWv Hello, I had a code question about creating 2D dynamic array by using realloc and without knowing sizes at start. Could you help me?
the best for everyone
#include <stdio.h>
//#define 1 true
//#define 0 false
int lower_case (char ch);
int upper_case (char ch );
int to_upper_case (char );
int to_lower_case (char );
int lower_case (char ch)
{
if(ch>='a' && ch<='z')
return 1 ;
else return 0 ;
}
int upper_case (char ch ) // with one parameter (argument)
{
if(ch >='A' && ch<='Z')
return 1 ;
else return 0 ;
}
int to_lower_case (char ch)
{
if(upper_case(ch))
return ch + 32; // ASCII Code table
else return ch;
}
int to_upper_case (char ch )
{ // form small to big
if(lower_case(ch))
return ch - 32; // ASCII Code table
else return ch;
}
int main ()
{
int g,f;
int b,i;
printf("enter a big litter to change it /n");
scanf("%d to change it to lower case %c " ,&g,to_lower_case(f));
printf("enter e small litter to change it to upper case ");
scanf("%d to change it to upper case %c",&b, to_upper_case(i));
return 0;
}
the best for everyone
can anyone tell me about the error ?
 klimi
klimi
#include <stdio.h>
//#define 1 true
//#define 0 false
int lower_case (char ch);
int upper_case (char ch );
int to_upper_case (char );
int to_lower_case (char );
int lower_case (char ch)
{
if(ch>='a' && ch<='z')
return 1 ;
else return 0 ;
}
int upper_case (char ch ) // with one parameter (argument)
{
if(ch >='A' && ch<='Z')
return 1 ;
else return 0 ;
}
int to_lower_case (char ch)
{
if(upper_case(ch))
return ch + 32; // ASCII Code table
else return ch;
}
int to_upper_case (char ch )
{ // form small to big
if(lower_case(ch))
return ch - 32; // ASCII Code table
else return ch;
}
int main ()
{
int g,f;
int b,i;
printf("enter a big litter to change it /n");
scanf("%d to change it to lower case %c " ,&g,to_lower_case(f));
printf("enter e small litter to change it to upper case ");
scanf("%d to change it to upper case %c",&b, to_upper_case(i));
return 0;
}
why don't you use bool for lower_case when you return only 1 or 0 ? also if you write
if (condition is true) { return true} else {return false} It is the same as
return condition