Hello everyone, i have a question since there is no database migration, available right now in pony orm, how do i go about making changes after my database is already in product, because i think manually altering the database can be dangerous
If you don't mind writing the migrations itself as code, try https://github.com/luckydonald/pony_up
 Lucky
Lucky

 Lucky
Lucky
 Tori
Tori
 Alexander
Alexander
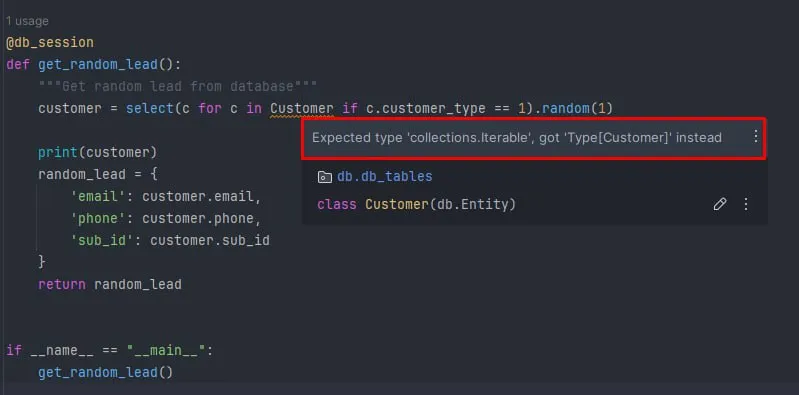
Hi! Indeed, PyCharm does not understand PonyORM query syntax. There are two ways to fix it: write a specific PyCharm plugin that deals with PonyORM queries (similar to how PyCharm handles non-standard specifics of Pytest, etc.), or add full support of modern Python typing to PonyORM. The second way looks better, as it is more general and can be used by other IDEs and tools, not only by PyCharm and IntelliJ IDEA.
PonyORM does not play well with modern Python typing because the PonyORM API was developed long ago for Python2 before Python got its current typing system. Adding proper typing support to PonyORM without breaking API compatibility is difficult.
Nevertheless, a slightly different ORM API that is fully compatible with Python typing is possible. I made a prototype of it, and it works perfectly. So, I want to implement Pony2 with a proper API that fully supports typing. Unfortunately, the last two years were pretty harsh to me, and I was out of resources to work on it, but it should change soon.
For now, you can use some helper functions like the following:
import typing
E = typing.TypeVar('E', bound=db.Entity)
def q(entity_class: typing.Type[E]) -> typing.Iterable[E]:
return typing.cast(typing.Iterable[E], entity_class)
If you wrap entities with q() call in queries, PyCharm should understand query syntax better:
customer = select(c for c in q(Customer) if c.customer_type == 1)
Note that your query select(...).random(1) returns not a customer but a list of customers that can contain zero or one item. So, your code should be like:
customer_list = select(...).random(1)
if not customer_list:
return None # handle the case when no customers were found
customer: Customer = customer_list[0]
Tori
 Alexander
Alexander
What Python version do you use?
Tori
python 3.12
Alexander
python 3.12
Pony currently do not support Python 3.12 yet. Consider switching to 3.11 for now if possible. I hope we can add 3.12 support soon.
Tori
 Jesus
Jesus
Helllo, everyone its posible work with a existing view withouth PK , I don have permissions to modify the view
Alexander
Helllo, everyone its posible work with a existing view withouth PK , I don have permissions to modify the view
Hi! Each entity should have an unique key, it may be a combination of columns. If a view does not have unique key at all, you can work with it using raw SQL queries, like
cursor = db.execute("select ...")
for row in cursor.fetchall():
...
Tori
Hi, everyone!
I have a question about writing query in Pony? I got syntax, but can't understand is there query like 'SELECT *'? I need query without writing about all columns, maybe there is query like 'SELECT * FROM ...' to get all info about client, but not only specific info.
I write methods to work with database (MySQL) and I need one to get all info about customer. All info from all columns, but not only specific. And I don't sure it's good idea to write about each column.
 Radim
Radim
data = db.YourModel.select()
Radim
gets you all data from table
Alexander
Hi, by default Pony selects all columns from the table
Tori
Hi, by default Pony selects all columns from the table
yes, but it returns objects. isn't it? like: <pony.orm.core.Query object at 0x000001BBA0C46B10>
it'll probably be easier if I explain my method. I want to write method which cand find client by email/phone etc. so i need condition. And I get correct result only if i write about all columns like this:
@db_session
def get_client_info_by(self, **criteria) -> Union[dict, None]:
"""Return client's info from database by specified criteria"""
if not criteria: # If no criteria provided, return None
return None
query = select(c for c in self.clients)
for attr, value in criteria.items(): # Add filters to the query based on the criteria
query = query.filter(lambda c: getattr(c, attr) == value)
lead = query[:]
if lead:
client_info = {
'id': lead[0].id,
'first_name': lead[0].first_name,
'last_name': lead[0].last_name,
'type': lead[0].type,
'language_id': lead[0].language_id,
'country_id': lead[0].country_id,
# a lot of other columns ... (about 50)
'created_at': lead[0].created_at,
'updated_at': lead[0].updated_at
}
return client_info
else:
return None
and i call it this way:
data_base = DataBaseManager()
data_base.get_client_info_by(email='natali2040@example.com') # return dict
data_base.get_client_info_by(phone='6213787876', id='6402) # return dict
So I takl about this client_info dict, maybe I can get it easier?
 Vitaliy
Vitaliy
yes, but it returns objects. isn't it? like: <pony.orm.core.Query object at 0x000001BBA0C46B10>
it'll probably be easier if I explain my method. I want to write method which cand find client by email/phone etc. so i need condition. And I get correct result only if i write about all columns like this:
@db_session
def get_client_info_by(self, **criteria) -> Union[dict, None]:
"""Return client's info from database by specified criteria"""
if not criteria: # If no criteria provided, return None
return None
query = select(c for c in self.clients)
for attr, value in criteria.items(): # Add filters to the query based on the criteria
query = query.filter(lambda c: getattr(c, attr) == value)
lead = query[:]
if lead:
client_info = {
'id': lead[0].id,
'first_name': lead[0].first_name,
'last_name': lead[0].last_name,
'type': lead[0].type,
'language_id': lead[0].language_id,
'country_id': lead[0].country_id,
# a lot of other columns ... (about 50)
'created_at': lead[0].created_at,
'updated_at': lead[0].updated_at
}
return client_info
else:
return None
and i call it this way:
data_base = DataBaseManager()
data_base.get_client_info_by(email='natali2040@example.com') # return dict
data_base.get_client_info_by(phone='6213787876', id='6402) # return dict
So I takl about this client_info dict, maybe I can get it easier?
You can do it like this lead[0].to_dict(only=('first_name', 'last_name', 'type', 'language_id', 'country_id', ...))
https://docs.ponyorm.org/api_reference.html#Entity.to_dict
Tori
but it returns the same that my version wuth client_info dict.
I have about 55-57 columns in table and want to get all. well, I see it's impossible🥲
Radim
if the client info is unique, in case of email and number it should be
Radim
you can do db.Client.get(email='natali2040@example.com').to_dict()
Radim
if it is not unique, you can specify other attributes as well and when combined, it is like unique key
Radim
if not, it will raise an Error that multiple objects were found
Tori
yes, I got it earlier, this is my second problem to solve😅 okay, thank every one, maybe to get result that i need, I should use my last way
 Долли
Долли
Hi, please, tell me, what I am doing wrong???
I've just started study PonyORM, and have such code:
from pony.orm import *
db = Database()
db.bind('sqlite', filename='db.sqlite', create_db=True)
class User(db.Entity):
id = PrimaryKey(int, auto=True)
name = Required(str, unique=True)
pass_hash = Required(str)
somebool = Required(bool, default=False)
db.generate_mapping(create_tables=True)
SQLite file already created by this code and have such content:
>>>User.select().show()
id|name |pass_hash |somebool
--+------+----------+--------
1 |John |<PASSWORD>|True
2 |Smith |<PASSWORD>|False
3 |John2 |<PASSWORD>|True
4 |Smith2|<PASSWORD>|False
When I try to do something like this
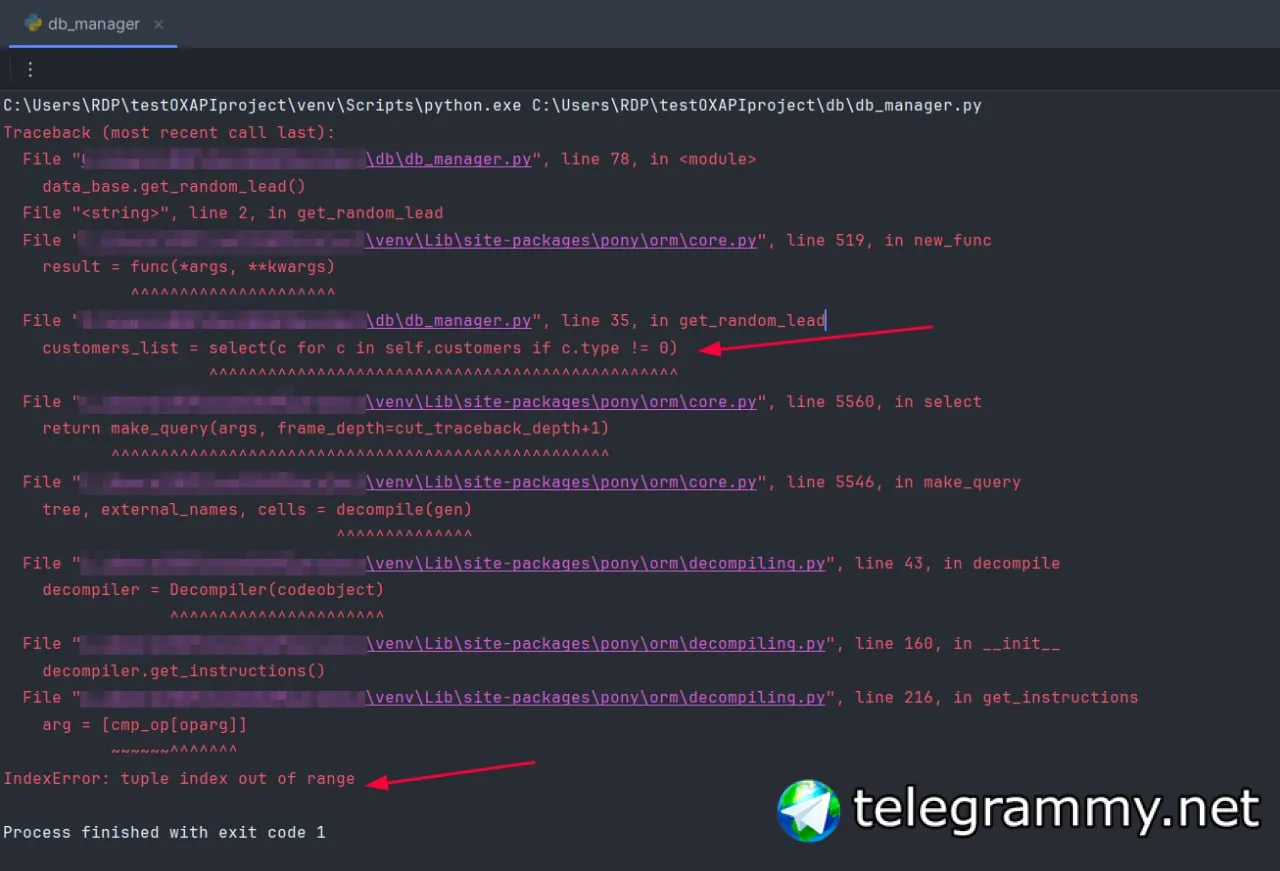
>>>select((u.id, u.name) for u in User)[:]
It doesn't works and tells me :
IndexError: tuple index out of range
And this code:
>>>select(u for u in User)[:]
Raises :
TypeError: Decompiler.YIELD_VALUE() takes 1 positional argument but 2 were given
PLEASE!! What I'm doing wrong??? Help noobie!!
 Alexander
Alexander
Heelo is it python 3.12?
Alexander
Pony only supports versions up to 3.11
Долли
Pony only supports versions up to 3.11
thanx, I'll try just now
Долли
Pony only supports versions up to 3.11
Great! It Really works! By the way, tell me , please, if I run one application , for exampe web-interface for tg-bot, and another aiogram-app , with the only file for them, whether collision or db lock from Pony side in both of them?
 Santosh
Santosh
When does support for python3.12 will be available
Tori
Hi there!
Can somebody help me please to create new query for my project? I need method which would find customers in specific date range. My question is how to create query with operator 'between' or smth like that.
For example, in MySQL i can use 'between' like that:
SELECT * FROM 'customers' WHERE `created_at` BETWEEN '2024-05-21 00:00:00' AND '2024-05-31 23:59:59'
How I can find values with this "filter" in Pony?
Alexander
When does support for python3.12 will be available
I'll try to do it next weekend, but probably it will take a few more weeks
Tori
Hahah, it's genius! I've read documentation and cound'n find something about 'between'. Thank you, thank you very much!
aldo
good morning, working with entity inheritance. i see that there is a 'classtype' attribute on the table, but is not indexed. ¿shouldn't be? ¿how may have it indexed?
Alexander
Hello! Practically classtype will have very limited number of values (names of entities) indexing would be not efficient imo
aldo
so I have base class Communication with derived Chat, Email, Call. ¿would be efficient to obtain page(42, 1000) of Call? ¿or perform a search on date (indexed) just on Email?
aldo
apart for obj in orm.select(x for x in Model):
obj.foo() the table is enormously huge, ¿is there a generator alternative?
Alexander
Hi! Databases store table content in pages. For an index to be useful, it should allow loading fewer pages than the entire table has. Otherwise, the full scan should be more efficient.
If a table contains objects of different subtypes, usually, each table page contains a mix of different subtypes, and the index just on the classtype column does not reduce the number of pages that need to be loaded for further analysis. Hence, it is not efficient to use such an index.
In your case, for an index to be useful, it should:
- order table rows in the same way as your typical query
- contains not only the classtype column but also other columns used during the filtering.
Alexander
In your example, you mentioned an Email subtype that should be filtered in date. Then, the best index for this query should be:
CREATE INDEX idx_communication_email_date
ON Communication(date, classtype);
Note that I put classtype at the end, so index entries are sorted by the date column, allowing efficient ordering and queries like date between x and y'. If I place `classtype in the first position, it will not work with these types of queries.
Alexander
To create such an index in Pony, you can define your entities as:
class Communication(db.Entity):
classtype = Discriminator(str)
date = Required(datetime, default=datetime.utcnow)
composite_index(date, classtype)
...
class Chat(Communication):
message = Required(str)
...
class Email(Communication):
subject = Required(str)
body = Required(str)
...
class Call(Communication):
duration = Required(int)
...
Alexander
or, if the date column is specific to the Email subclass:
class Communication(db.Entity):
...
class Chat(Communication):
message = Required(str)
class Email(Communication):
date = Required(datetime, default=datetime.utcnow)
composite_index("date", "classtype")
subject = Required(str)
body = Required(str)
class Call(Communication):
duration = Required(int)
Alexander
You can also use a partial index that only keeps Email entries:
CREATE INDEX idx_communication_email_date
ON Communication(date) WHERE classtype = "Email";
It should be even more efficient if you only need this index for Email objects. Pony currently can't define partial indexes, but you can do it manually.
Alexander
> the table is enormously huge, ¿is there a generator alternative?
If you can iterate objects ordered by id, the most efficient you can do is to remember the last processed id, and then do
@db_session
def process_batch(last_id=0, size=1000):
batch = Email.select(
lambda obj: obj.id > last_id
).order_by(
lambda obj: obj.id
).limit(size)[:]
if not batch:
return
for obj in batch:
process(obj)
last_id = batch[-1].id
return last_id
For iterating over a huge table, it can be much more efficient than pagination
aldo
thank you for the explanation, i was having a misconception on how the indexes worked (more like the partial index kind)
would need some testing to decide which solution works best
aldo
ah, i see the optimization in the iteration, would see to change it
Alexander
Each batch should be in a separate db_session to not store all loaded objects in memory. You should not wrap the entire process into a single db_session
Daniel
good day everyone, how do i do database migration with pony orm
Jasper
Is it possible to do composite keys from the GUI editor? I can't figure it out
Lucky
Is it possible to do composite keys from the GUI editor? I can't figure it out
If I remember right from years ago, you just mark more than one key as primary key
Jasper
oh you're right, that was easy
Jasper
thanks!
Radim
hey, any progress on py3.12 support?
 Oualid
Oualid
good day everyone, how do i do database migration with pony orm
this is the most Pony need for now , including async support. still in demand
 Henri
Henri
I have some problems when switching from SQLite to Postgresql.
The first thing, I cannot add new instances to the model.
When doing e.g.
def add(self, shortname, rate, countries):
tax = Tax(
shortname=shortname,
rate=Decimal(rate),
countries=[Country.get(code=country) for country in countries],
)
tax.flush()
return tax
When executing tax.flush() it throughs
E pony.orm.core.TransactionIntegrityError: Object Tax[new:1] cannot be stored in the database.
IntegrityError: duplicate key value violates unique constraint "tax_pkey"
E DETAIL: Key (id)=(1) already exists.
Similar with other models.
Lucky
That's probably an issue with the serial in posgres.
ID columns have a counter which tells them which would be the next ID number. If that is lower than existing IDs, it might cause some overlap.
Lucky
I have some problems when switching from SQLite to Postgresql.
The first thing, I cannot add new instances to the model.
When doing e.g.
def add(self, shortname, rate, countries):
tax = Tax(
shortname=shortname,
rate=Decimal(rate),
countries=[Country.get(code=country) for country in countries],
)
tax.flush()
return tax
When executing tax.flush() it throughs
E pony.orm.core.TransactionIntegrityError: Object Tax[new:1] cannot be stored in the database.
IntegrityError: duplicate key value violates unique constraint "tax_pkey"
E DETAIL: Key (id)=(1) already exists.
Similar with other models.
Hence it would fail.
Check out the following, to see if that's the issue, and for a possible solution.
See https://stackoverflow.com/a/244265/3423324
Henri
This happens when executing tests. Before I create
Tax(
id=1,
shortname="MwSt",
rate=Decimal("7.0"),
countries=[Country.get(code="DE")],
)
Tax(
id=2,
shortname="VAT",
rate=Decimal("8.0"),
countries=[Country.get(code="PL")],
)
When removing the ids here it seems to work
Lucky
This happens when executing tests. Before I create
Tax(
id=1,
shortname="MwSt",
rate=Decimal("7.0"),
countries=[Country.get(code="DE")],
)
Tax(
id=2,
shortname="VAT",
rate=Decimal("8.0"),
countries=[Country.get(code="PL")],
)
When removing the ids here it seems to work
For tests i can think of a few solutions:
a) grab the ids after inserting,
b) clear the database before tests and reset the id serial to 1
c) use negative ids, e.g. id = -2 etc.
Lucky
For tests I usually go with c)
Makes it really easy to see if something is test data, too.
Additionally you can do some raw sql in your setup like DELETE FROM "table_name" WHERE id < 0 to make sure there's no test data before starting. Same sql can be executed in the cleanup method too.
Henri
Actually the setup function is
def setup_function():
db.drop_all_tables(with_all_data=True)
db.create_tables()
with db_session:
Tax(
id=1,
shortname="MwSt",
rate=Decimal("7.0"),
countries=[Country.get(code="DE")],
)
Tax(
id=2,
shortname="VAT",
rate=Decimal("8.0"),
countries=[Country.get(code="PL")],
)
Henri
And when trying to add tax in the test it tries to add again id=1. So the ID count seems to be wrong.
Henri
So I think solution c should work. Still strange that it doesn't count.
Henri
Any way to adjust the id counter? There are tons of tests and changing all to negative ids would be quite some work.
Besides c.get("/taxes/-1") or Tax[-1].delete() looks quite strange...
Henri
The other problem with postgresql, maybe more serious because in production:
I have this query:
def query(self):
query = Product.select()
# products not containing active variations are only returned to the shop owner
if not self.is_shop_owner:
query = query.where(lambda p: (v.active for v in p.variations))
with sql_debugging(show_values=True): # log with query params
result = query[:]
return result
Henri
The resulting SQL is:
SELECT "p"."id", "p"."slug", "p"."name", "p"."shop", "p"."created_at", "p"."updated_at"
FROM "product" "p"
WHERE (
SELECT DISTINCT "v"."active"
FROM "productvariation" "v"
WHERE "p"."id" = "v"."product"
)
Henri
And the resulting error is
File ".venv/lib/python3.11/site-packages/pony/orm/dbapiprovider.py", line 64, in wrap_dbapi_exceptions
raise ProgrammingError(e)
pony.orm.dbapiprovider.ProgrammingError: more than one row returned by a subquery used as an expression
Henri
This happens when there is more then one active variation for one product. In SQLite it works fine.
Henri
Ok. I found a solution.
query = query.where(lambda p: (True in p.variations.active))
seems to work :)
Henri
Yesterday I spent several hours on this one...
Henri
BTW the SQL is now
SELECT "p"."id", "p"."slug", "p"."name", "p"."shop", "p"."created_at", "p"."updated_at"
FROM "product" "p"
WHERE true IN (
SELECT "productvariation"."active"
FROM "productvariation" "productvariation"
WHERE "p"."id" = "productvariation"."product"
)
Henri
And for testing I switch back to SQLite...
 М
М
Hello.
Is there a way to make a PostgreSQL constraint deferrable inside PonyORM, or the only way to do that is to alter table after db.generate_mapping(create_tables=True)?
香港保險經理人
I really need examples as well xD
 Artemiy
Artemiy
Hi. Is this project still alive? Can I use it with py3.12?
Radim
py3.12 support not yet available
Radim
py3.11 is supported