 Karsten
Karsten


Thank you, I'll test it and get back to you later.
Karsten
I think you need to check the resulted SQL of your query
... as expected, the last value is used everywhere for all variables. Here is the output:
WHERE ((r.event_time >= ?) AND (r.event_time <= ?) AND (r.net = ?) AND ((r.code = ?) OR (r.code = ?)) AND (r.action = '')) ORDER BY r.event_time
['2021-01-01 00:00:00.000000', '2021-03-02 00:00:00.000000', 'TDM', '100', '100']
 Alexander
Alexander
Now I understand what you mean
Alexander
No problem, you English is pretty good
Alexander
You can do something like:
Alexander
elif cnt > 1:
sel_str += " AND ("
for i in range(0, len(code_lst)):
if len(code_lst[i]) > 0 and code_lst[i][0] != '-':
new_code = code_lst[i]
sel_str += "(r.code = $(code_lst[%d][0])) OR " % i
sel_str = sel_str[:-4] + ')'
(You need to have code_lst avaiable in scope at the point you pass resulted SQL to Pony)
Karsten
...I agree ! and only the last entry in new_code is available for transfer. Thanks, I'll try later.
Karsten
elif cnt > 1:
sel_str += " AND ("
for i in range(0, len(code_lst)):
if len(code_lst[i]) > 0 and code_lst[i][0] != '-':
new_code = code_lst[i]
sel_str += "(r.code = $(code_lst[%d][0])) OR " % i
sel_str = sel_str[:-4] + ')'
(You need to have code_lst avaiable in scope at the point you pass resulted SQL to Pony)
... that's how it works! Many Thanks
 Jeff
Jeff
So im new to ponyorm, and using the diagram tool. Its different from other tools ive used and a bit confounded because im used to connecting other tables via foreign keys. So i need some validation on my schema if anyone cares to review.
Jeff
i see that the resulting sql tables match the initial design
Jeff
but still want some review: https://editor.ponyorm.com/user/adempus/WorldChaseTag/designer
Jeff
i was trying to connect columns team_a and team_b to foreign keys of the same table, but was confused because I couldn't set both to the same PK column.
Alexander
Hi! It looks correct. Physically the team_a column keeps id of a team (and has a foreign key which connected to the primary key of the Team table), but on the diagram it linked with the opposite side of relationship, a virtual attribute matches which allow to select a collection of all matches related to the same team
Jeff
okay, that explanation drove it home for me. Thanks!
Jeff
so if I were to do something like team.matches_won() it would give me the team's list of won matches where the team's id is present in winning_team in the match table.
Alexander
yes. You can do stuff like:
for match in team.matches_won:
...
won_this_year = team.matches_won.select(
lambda match: match.date.year == date.today().year
)
good_dates = team.matches_won.date # attribute lifting
Jeff
brilliant! Thank you.
Jeff
Also, is it possible to integrate ponyorm with graphene for graphql support? I have not seen any examples of this and wondering if it's doable?
Alexander
We don't have a ready solution for that
Jeff
ok
 Genesis Shards Community
Genesis Shards Community
hi, tengo este error:
Genesis Shards Community
pony.orm.dbapiprovider.OperationalError: (1205, 'Lock wait timeout exceeded; try restarting transaction'),
Alexander
pony.orm.dbapiprovider.OperationalError: (1205, 'Lock wait timeout exceeded; try restarting transaction'),
https://stackoverflow.com/a/5837308/1706814
 Henri
Henri
I have a ltree column in my Symptom table:
class Symptom(db.Entity):
description = Required(str)
rubric = Required(Rubric)
path = Required(str, sql_type="ltree", unique=True)
So the path can have values like "1.2" or "1.2.3".
In the first case Pony returns a number instead of a string.
The second case works as expected.
For testing I use sqlite for now. ATM I don't expect ltree to work.
Any way to fix that?
Henri
Here is part of the error diff:
E 'id': 6,
E 'description': 'pulse',
E 'rubric': 105,
E - 'path': '105.6',
E ? - -
E + 'path': 105.6,
E 'id': 7,
E 'description': 'weak',
E 'rubric': 105,
E 'path': '105.6.7',
 Queso Di Pesto
Queso Di Pesto
Hello!
I have a problem that I can't find a solution to.
I have a database, that when I try to launch a SQL statement, it only returns the "id", but when I try to get some value belonging to the database (SELECT name FROM data WHERE age ='30') I get the following error:
ValueError: Primary key attribue Url.id was not found in query result set
I'm using sqlite
Queso Di Pesto
And sorry for my english ^.^'
Queso Di Pesto
And this is my structure:
db = Database()
class Data(db.Entity):
id = PrimaryKey(int, auto=True)
vote = Optional(int, default=0)
v_hard = Required(LongStr, unique=True)
v_soft = Optional(LongStr, unique=True)
gender = Optional(str, default='M')
db.bind(provider='sqlite',filename='database/data.sqlite', create_db=True)
db.generate_mapping(create_tables=True)
Jeff
Is there a way to generate JSON of the schema from my entity mapping?
I'm trying to do this: https://pydantic-docs.helpmanual.io/datamodel_code_generator/
Alexander
I have a ltree column in my Symptom table:
class Symptom(db.Entity):
description = Required(str)
rubric = Required(Rubric)
path = Required(str, sql_type="ltree", unique=True)
So the path can have values like "1.2" or "1.2.3".
In the first case Pony returns a number instead of a string.
The second case works as expected.
For testing I use sqlite for now. ATM I don't expect ltree to work.
Any way to fix that?
Hi Henri!
Instead of normal datatypes, SQLite columns have type affinities:
https://www.sqlite.org/datatype3.html
SQLite automatically converts text values to numeric values for columns with NUMERIC, INTEGER or REAL affinities.
Your column path has ltree column type name, which, according to SQLite rules, has NUMERIC affinity (see "3.1. Determination Of Column Affinity")
You need to remove sql_type="ltree" in SQLite or replace it to something like sqltype="ltreetext"
Alexander
Hello!
I have a problem that I can't find a solution to.
I have a database, that when I try to launch a SQL statement, it only returns the "id", but when I try to get some value belonging to the database (SELECT name FROM data WHERE age ='30') I get the following error:
ValueError: Primary key attribue Url.id was not found in query result set
I'm using sqlite
If you use SomeEntity.select_by_sql(some_raw_sql), Pony tries to return list of SomeEntity objects. For that, resulted SQL should return all columns of SomeEntity's primary key.
If instead of SomeEntity objects you want to return some arbitrary data (like SomeEntity.name), then instead of SomeEntity.select_by_sql(some_raw_sql) you should use db.select(some_raw_sql) or db.execute(some_raw_sql)
Alexander
Is there a way to generate JSON of the schema from my entity mapping?
I'm trying to do this: https://pydantic-docs.helpmanual.io/datamodel_code_generator/
Currently we don't have a good way to do this
Queso Di Pesto
If you use SomeEntity.select_by_sql(some_raw_sql), Pony tries to return list of SomeEntity objects. For that, resulted SQL should return all columns of SomeEntity's primary key.
If instead of SomeEntity objects you want to return some arbitrary data (like SomeEntity.name), then instead of SomeEntity.select_by_sql(some_raw_sql) you should use db.select(some_raw_sql) or db.execute(some_raw_sql)
Hi! Thanks Alexander =)
Actually I use this sentence:
Database.select_by_sql(SELECT * FROM data WHERE age='30')
And this only returns me the Primary Key, but if I change the
*
to
v_soft
(or whatever) this returns me the ValueError commented previously.
Then... if I want to see all my info, should i change my sentence for:
Database.select(SELECT * FROM data WHERE age='30')
????
Alexander
In Pony there is no Database.select_by_sql method, only Entity.select_by_sql.
If you called one of your entity as Database it looks confusing :)
Entity.select_by_sql method expects that entity primary key is presented in the column list. Don't use this method if you want to get not entity instances, but raw column values
Queso Di Pesto
In Pony there is no Database.select_by_sql method, only Entity.select_by_sql.
If you called one of your entity as Database it looks confusing :)
Entity.select_by_sql method expects that entity primary key is presented in the column list. Don't use this method if you want to get not entity instances, but raw column values
"Database" name is not my real database name is only a example 😋
Queso Di Pesto
In Pony there is no Database.select_by_sql method, only Entity.select_by_sql.
If you called one of your entity as Database it looks confusing :)
Entity.select_by_sql method expects that entity primary key is presented in the column list. Don't use this method if you want to get not entity instances, but raw column values
Done! Thanks a lot Alexander!! 🥳
Henri
Hi Henri!
Instead of normal datatypes, SQLite columns have type affinities:
https://www.sqlite.org/datatype3.html
SQLite automatically converts text values to numeric values for columns with NUMERIC, INTEGER or REAL affinities.
Your column path has ltree column type name, which, according to SQLite rules, has NUMERIC affinity (see "3.1. Determination Of Column Affinity")
You need to remove sql_type="ltree" in SQLite or replace it to something like sqltype="ltreetext"
Thanks Alexander!
I switched now to postgreSQL for testing and it works.
Henri
And thanks for the background. Don't think I would have find that quickly... 😉
 Volbil
Volbil
Hello @metaprogrammer, I have question regarding splitting select. In terms of performance which approach is better?
Single select:
query = Candle.select(
lambda c: c.pair == pair and c.time >= start and c.interval == resolution
)
Select with filter:
query = Candle.select(lambda c: c.interval == resolution)
query = query.filter(
lambda c: c.pair == pair and c.time >= start and c.time < stop
)
I prefer second option since it's easier to read, but not sure if it will affect performance.
 Alexander
Alexander
They are the same
Alexander
No problem
Volbil
I suspected that but decided to ask just in case :)
Alexander
Until you start iterate over query object or call limit()\first() - it doesnt produce SQL so you free to modify it
Volbil
Oh, I see. That's interesting insight 👍🏻
Queso Di Pesto
HI!!
I have a question, can i made a list usign this command --> db.select(sql_raw_sentence) If i do, for example: test = db.select(sql_raw_sentence) this give me a list with range 0, with all the "columns" separate by ","
Queso Di Pesto
Ok, i have to change to db.get() :D
 Ben
Ben
 Lucky
Lucky
 Andreas
Andreas
Hello,
is it possible to search for case insentitive strings?
F.e. my database contains the string "Football", I want to be able to search for "Football" and "football" and receive the same results.
El Mojo
Andreas
Oh, I see. And then a lambda expression.
Thanks! :)
Jim
Hi,
Anyone ever tried pony with pydantic from_orm method ?
El Mojo
Hi,
Anyone ever tried pony with pydantic from_orm method ?
Yes, I'm using pydantic with pony, what's the question exactly?
Jim
the conversion between pony object et pydantic model : https://pydantic-docs.helpmanual.io/usage/models/#orm-mode-aka-arbitrary-class-instances
Jim
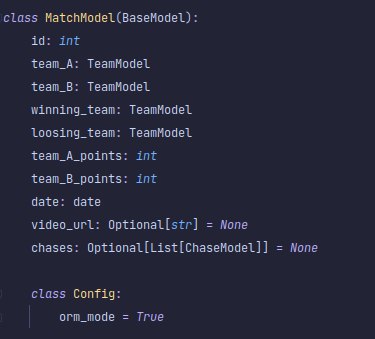
does MyPydanticModel.from_orm(myponyInstance) works ?
Alexander
Yeah it seems it does
El Mojo
the conversion between pony object et pydantic model : https://pydantic-docs.helpmanual.io/usage/models/#orm-mode-aka-arbitrary-class-instances
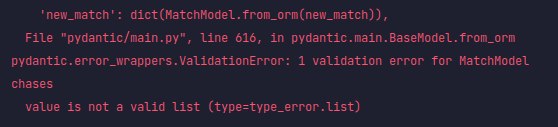
yes it works except if you have a relationship (pony set/multiset) inside your pony object ; then you need to add a validator for your pydantic model or a GetterDict to your pydantic config class model. example:
class PonyGetterDict(GetterDict):
def get(self, key: Any, default: Any = None):
res = getattr(self._obj, key, default)
if isinstance(res, SetInstance):
return list(res)
return res
class ObjectOut(UpdateObject):
id: int
...
impacts: List[FearedEventImpact] = []
...
class Config:
orm_mode = True
getter_dict = PonyGetterDict
Jim
ok thanks
Jeff
 Jeff
Jeff
 Jim
Jim
funny I asked the same question today
Jim
yes it works except if you have a relationship (pony set/multiset) inside your pony object ; then you need to add a validator for your pydantic model or a GetterDict to your pydantic config class model. example:
class PonyGetterDict(GetterDict):
def get(self, key: Any, default: Any = None):
res = getattr(self._obj, key, default)
if isinstance(res, SetInstance):
return list(res)
return res
class ObjectOut(UpdateObject):
id: int
...
impacts: List[FearedEventImpact] = []
...
class Config:
orm_mode = True
getter_dict = PonyGetterDict
Jeff
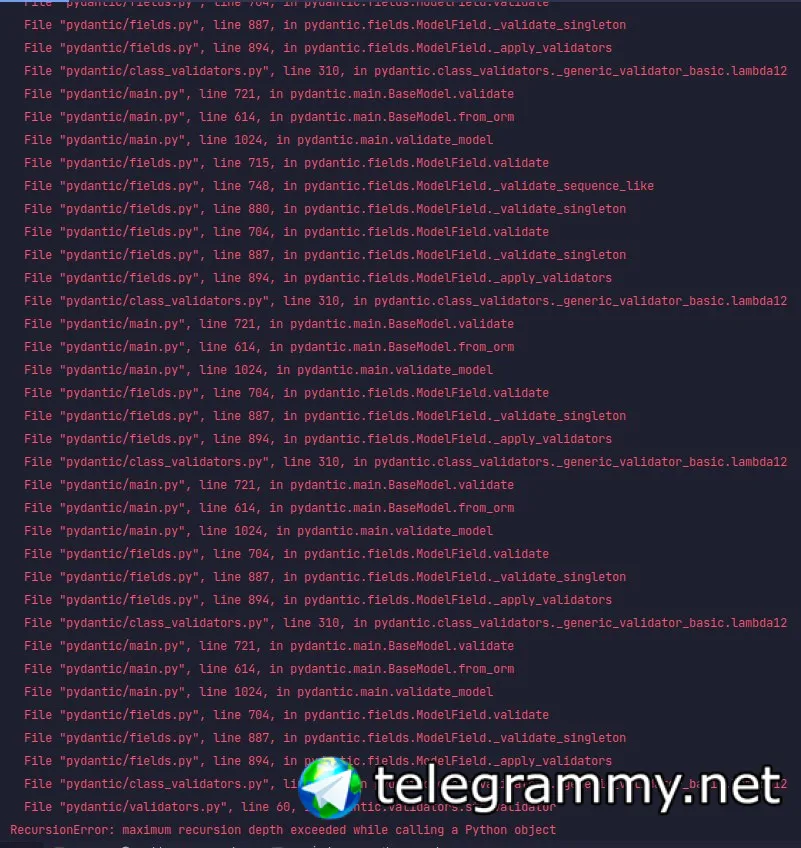 Jeff
Jeff
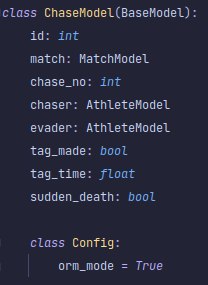 Jeff
Jeff
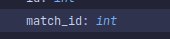 Jeff
Jeff
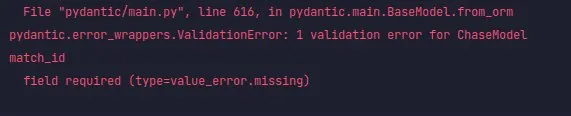 El Mojo
Henri
El Mojo
Henri
After switching from SQLite to Postgresql I got a problem with auto-increment of the primary key during testing.
The model:
class User(db.Entity):
email = Required(str, 80, unique=True)
firstname = Required(str, 64)
lastname = Required(str, 64)
password = Required(str, 255)
register_ip = Optional(str, 46)
The add logic:
def add(self, email, firstname, lastname, password, register_ip=""):
ph = PasswordHasher()
password_hash = ph.hash(password)
user = User(
email=email,
firstname=firstname,
lastname=lastname,
password=password_hash,
register_ip=register_ip,
)
user.flush()
return user
The test:
def test_add_user():
new_user_json = json.dumps(
{
"email": "newuser@example.com",
"firstname": "NewUser",
"lastname": "Test2",
"password": "top_secret_7",
}
)
response = c.post("/users", new_user_json, status=201)
The error message:
pony.orm.core.TransactionIntegrityError: Object Repertorization[new:1] cannot be stored in the database. IntegrityError: ERROR: double key value hurts Unique-Constraint »repertorization_pkey«
E DETAIL: Key »(id)=(1)« already exists.
The same happens in other tables when adding an entity. With SQLite everything was fine.
Jim
I run it between tests with postgre:
def _pg_reset_sequences(db):
with orm.db_session():
sequences = db.execute(
"SELECT sequence_name FROM information_schema.sequences;"
).fetchall()
for item in sequences:
req = "ALTER sequence {0} RESTART".format(item[0])
db.execute(req)
Jim
postgree doesn't reset counter
Matthew
you need to rebuild the database between tests I think
Henri
you need to rebuild the database between tests I think
I use this between tests:
def setup_function(function):
db.drop_all_tables(with_all_data=True)
db.create_tables()
ph = PasswordHasher()
with db_session:
User(
id=1,
email="leader@example.com",
firstname="Leader",
lastname="Test",
password=ph.hash("top_secret_1"),
is_admin=True,
)
User(
id=2,
email="mary@example.com",
firstname="Mary",
lastname="Test",
password=ph.hash("top_secret_2"),
)
User(
id=3,
email="juergen@example.com",
firstname="Jürgen",
lastname="Test",
password=ph.hash("top_secret_3"),
)
But it doesn't help.
Henri
The most weird thing is that after switching to Postgresql I had the same problem with the patient table but after debugging it for a while it starts to work. But I'm not aware of changing any relevant code. It looks similar to the tables where it fails.
Henri
I run it between tests with postgre:
def _pg_reset_sequences(db):
with orm.db_session():
sequences = db.execute(
"SELECT sequence_name FROM information_schema.sequences;"
).fetchall()
for item in sequences:
req = "ALTER sequence {0} RESTART".format(item[0])
db.execute(req)
Adding this to setup_function, which runs before the tests doesn't help either.
Henri
This is the test for the Patient entity, which is the one which works. I don't see any difference.
def test_add_patient():
c = Client(App())
new_patient = json.dumps({"data": "NewEncryptedTestData"})
patient = {
"id": 3,
"data": "NewEncryptedTestData",
}
response = c.post("/patients", new_patient, status=201)
assert patient.items() <= response.json.items()
assert response.json["data"] == "NewEncryptedTestData"
with db_session:
assert Patient.exists(id=3, data="NewEncryptedTestData")
Henri
When I look at the database I see, that User[1] - User[3] exists before the code to add a new user runs, so I would expect that auto-increment works and creates id=4.
 Christian
Christian
Getting error pony.orm.dbapiprovider.OperationalError: (3159, 'Connections using insecure transport are prohibited while --require_secure_transport=ON.') - Do I need to set this with the driver (pymysql in my case) or with Pony?