 Yuriy
Yuriy


Через Juju можно в мониторинг поставить бэкенд, и если он недоступен, менять его по умолчанию на другой.
Yuriy
Там 5 строчек скрипта на баше максимум.
 Artemy
Artemy
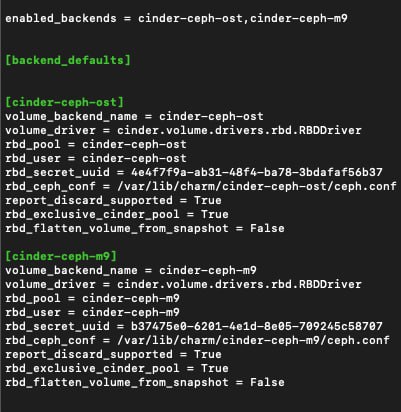 Alexey
Artemy
Alexey
Artemy
 Artemy
Artemy
Почему неудачное?
Вот смотри - предположим тебе надо создать два идентичных инстанса в разных ДЦ (в разных зонах). Если ты делаешь как положено то ты а) указываешь у инстанса зону доступности б) указываешь волюм тайп ceph. После чего волюмы автоматом приезжают на правильные бакэнды. А если сделать как сделал ты - то тебе надо у каждого инстанса выбрать правильный тип.
Alexey
Так может просто дефаулт оставить )))
Artemy
Но есть один нюанс. Чтобы это дело заработало нужно включать cross_az_attach=no в нове, и тогда волюмы нельзя быдет зааттачить к ВМ другой зоны :)
Artemy
Как миниумум в йоге такое ограничение было
Artemy
Там какая-то упоротая система коммитинга, пошли они нафиг с ней 😊
Sid
ты гонишь
Sid
ты про sell забыл
 Stanley
Stanley
Коллеги, может тогда распишите правильное решение под задачу Мороза? Ну чисто для истории.
Stanley
Волум тайпы не использовать, белое не надевать, не танцевать
Stanley
Кто лишил? Наказать
 ⓥ
ⓥ
 Stanley
Stanley
Не, я то все понял. Кроме того что Артём написал. Но пофиг, я волум тайпы только для qos использовал и чтобы отдельный пул от большого цефа вынести (HDD) для холодных бекапов.
 Pavel
Pavel
А нефиг дефолт без указания бека использовать.
Рамиль
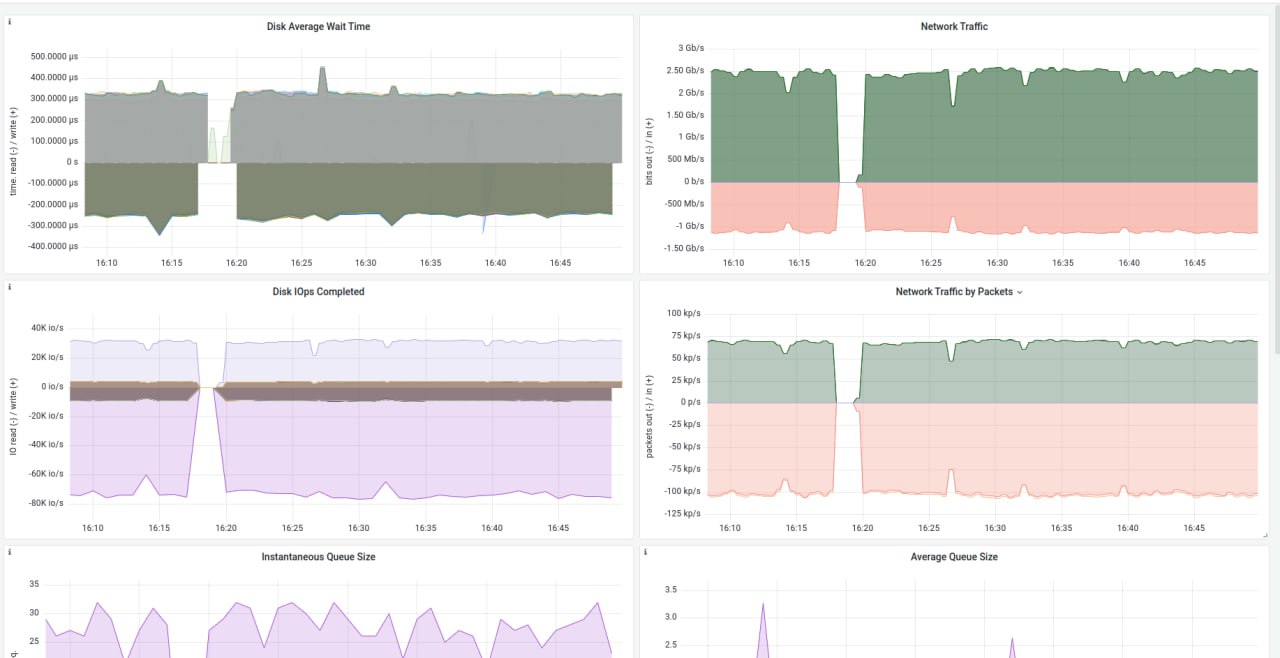 Artemy
Artemy
В латенси ты уперся, в процессор, в очередь и в sync. Убери fsync=1, скажи sync=1
Artemy
Дело в том что вызов fsync является условно (внутри) блокирующим и приводит к дрейну очереди
Nikolay
iscsi это же fc?
Nikolay
или прям он самый
Nikolay
а вижу, слепой
Nikolay
Поэтому и вопрос был, поверх чего
Nikolay
Не понимаю я ваши кадры пакеты маки ИП, просто включаю компутер и там Ютуб есть
Nikolay
Кстати надо пересмотреть... На очередном архитектурном коммитете
Nikolay
Тебя нет чтобы херами крыть
Nikolay
Реально жесть, из пустого в порожнее сколько можно переливать
Рамиль
В латенси ты уперся, в процессор, в очередь и в sync. Убери fsync=1, скажи sync=1
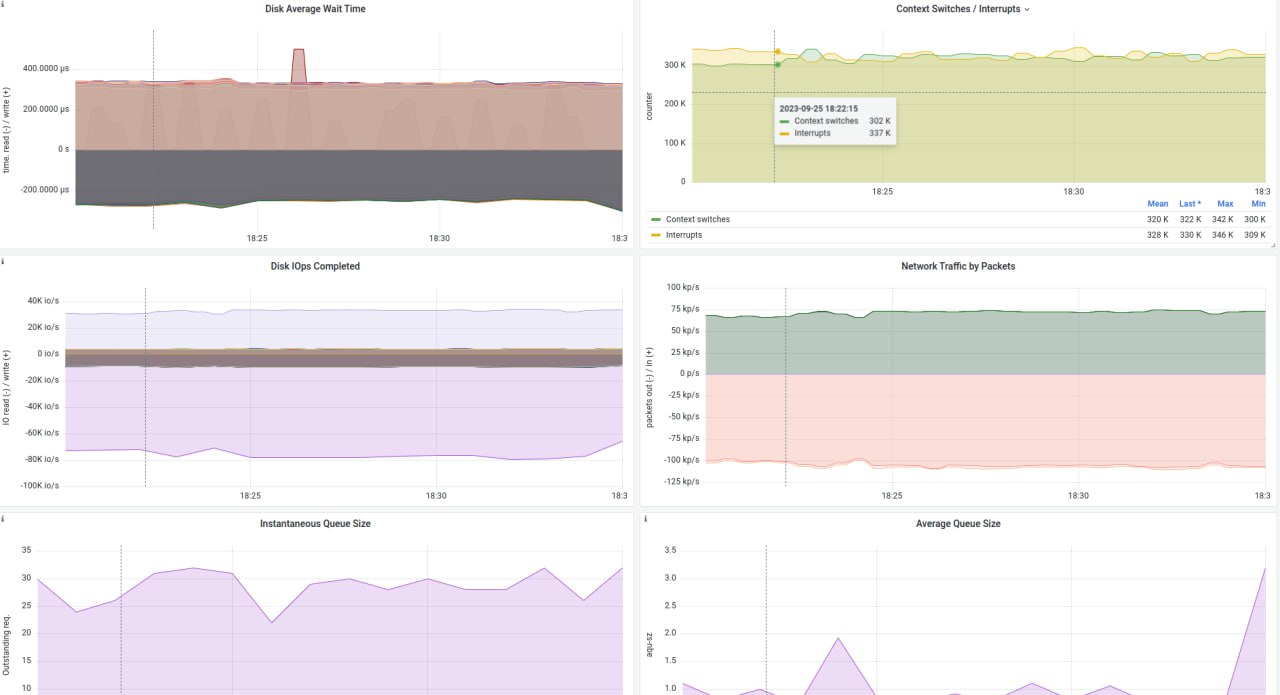 Рамиль
Рамиль
да
Рамиль
наверное( что значит независимая? агрегат не собран. оба интерфейса сейчас нагружены на ~2.5 Гбит/с
Artemy
Рамиль
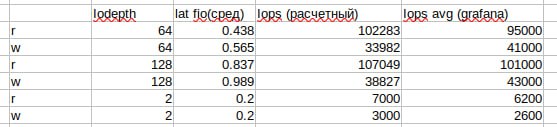
Неинтересно. У тебя латенси средняя порядка 0.3ms, у тебя 32 потока, сколько IOPS должно быть? И сколько иопсов у тебя на графиках?
на графиках ~110 килоопсов. Вопрос в сторону вот этого расчета?
32(очередь) * 3333 (иопса за одну секунду ) = ~106 килоопса
Рамиль
1000 милисенд / 0.3 мс = 3333
Artemy
Остынь. Он уперся в латенси. М - математика
Artemy
Л-А-Т-Е-Н-С-И. 32 очереди по 3.4K иопс в каждой.
Artemy
Сделает iodepth=128 - получит больше IOPS, сделает blocksize=64K - получит больше банвич
Рамиль
Дело было не в бабине!
kn
строго говоря - fc(fcp) это все таки протокол, а среда передачи у него может быть и оптика и медь
Рамиль
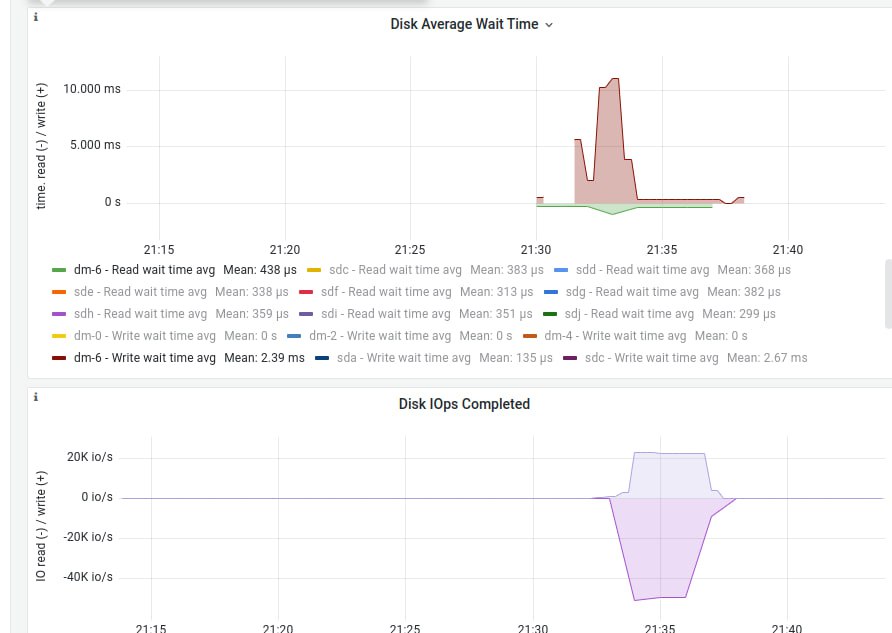
Сейчас проверю и узнаю погрешность и/или еще одно узкое место
kn
ну так то да, но которое время назад были диски с интерфейсом fc (https://www.disctech.com/Sun-540-6343-Fiber-Fibre-Channel-Hard-Drive), но в них из оптики был только светодиод :)
kn
сдаюсь :)
Рамиль
Сейчас проверю и узнаю погрешность и/или еще одно узкое место
 J
J
J
J
Ну а дальше будешь уже оптимизировать.
Включать\выключть оффлоды на картах, пинить ядра, играть с io планировщиками и все в таком духе.
Небыстрый процесс, короче.
J
У тебя результаты то близкие к расчетным. ХЗ много ли там можно улучшить)
J
Ну да)
Столько работы проделать, конечно)
J
Вот эт ты лихо)
Сразу ROCE)
 Denis
Denis
Предлагаю сразу InfiniBand )))
Denis
Роки шляпа, не масштабируется нормально
J
Предлагаю сразу InfiniBand )))
Та он чахнет.
Так и останется, конечно, в продуктах нвидии теперь. Но кроме мелланокса никто и не занимался.
По задержкам эзернет его уже перегнал всяко с ROCE)
Остаются только другие плюхи инфинибенда. Но в них вникать мало кто станет, потому что очень нишевый он.
Denis
Та он чахнет.
Так и останется, конечно, в продуктах нвидии теперь. Но кроме мелланокса никто и не занимался.
По задержкам эзернет его уже перегнал всяко с ROCE)
Остаются только другие плюхи инфинибенда. Но в них вникать мало кто станет, потому что очень нишевый он.
Смотря где, в наших задачах только на нем и выезжаем
Denis
да что ж ты все мимо-то? )
 Я и твой кот
Я и твой кот
Загуглите уж его.
J
Смотря где, в наших задачах только на нем и выезжаем
Я скептически отношусь к утверждениям что "только на нем выезжаем".
Обычно бывает так что на него сели несколько лет назад, когда эзернет не подошел.
А теперь эзернет уже вполне подходит, но слезать с IB очень трудозатратно будет. Вот и говорят все что только IB одним и живут)
Denis
Я скептически отношусь к утверждениям что "только на нем выезжаем".
Обычно бывает так что на него сели несколько лет назад, когда эзернет не подошел.
А теперь эзернет уже вполне подходит, но слезать с IB очень трудозатратно будет. Вот и говорят все что только IB одним и живут)
нет, к сожалению на тестах и реальных задачах все проверено и не раз
Denis
парни, с удовольствием подискутирую, но сейчас времени нет, надо документацию на BeeGFS допиливать
Denis
эх, если бы
J
парни, с удовольствием подискутирую, но сейчас времени нет, надо документацию на BeeGFS допиливать
Да не то чтоб очень хочется.
Если можешь, лучше коротко расскажи какие задачи, как пара минут будет)
Denis
Да не то чтоб очень хочется.
Если можешь, лучше коротко расскажи какие задачи, как пара минут будет)
Напомни послезавтра, пока правда занят
Denis
=)))
Denis
пусть будет так
Рамиль
 Рамиль
Рамиль
Всем спасибо
kn
а откуда kolla может брать неправильный (сломанный) адрес репозитория?:
INFO:kolla.common.utils.rabbitmq:E: Failed to fetch https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu/dists/jammy/InRelease 402 Payment Required [IP: cut]
INFO:kolla.common.utils.rabbitmq:E: The repository 'https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu jammy InRelease' is not signed.
INFO:kolla.common.utils.rabbitmq:
в template/repos.yaml адрес правильный
kn
ещё как. спасибо!
Denis
Нет, вчера был у заказчиков, приехал поздно.
Denis
Сразу говорю, что это к стеку не относится и может быть офтопом
Denis
По поводу задач: в основном это сильносвязные hpc задачи, такие как гидрогазодинакима, прочность, обучение языковых моделей. В этих задачах, особенно в обучении, критична задержка, которая не позволяет масштабировать вычисления.
Denis
Из последнего - запускали тесты на роки в одной биолабе, так вот там расчет больше чем на 8 нод не масштабировался, производительность выходила на полку и там оставалась. Точные цифры не помню, надо логи поднимать.