На ум приходит циклом пройтись, может есть более верное решение
deleteMany?
 Anonymous
Anonymous


 Dezmunt
Dezmunt
db.collection.remove( { _id : { $in: [
ObjectId("51ee3966e4b056fe8f074f48"),
ObjectId("51ee3966e4b056fe8f074f4a"),
ObjectId("51ee3966e4b056fe8f074f4b")
] } } );
Dezmunt
deleteMany
 StaniFe
StaniFe
Все добрый день! Подскажите, как в монге можно сделать autoincrement по int полю.
Есть много экземпляров сервиса и периодически возникают проблемы с дублями int значения 😔
Сервер кластерный
 Nick
Nick
Все добрый день! Подскажите, как в монге можно сделать autoincrement по int полю.
Есть много экземпляров сервиса и периодически возникают проблемы с дублями int значения 😔
Сервер кластерный
а на кой вам автоинкремент, какую бизнес задачу он решает?
Scorpi
Все добрый день! Подскажите, как в монге можно сделать autoincrement по int полю.
Есть много экземпляров сервиса и периодически возникают проблемы с дублями int значения 😔
Сервер кластерный
Не знаю как другие делают, но у меня в проекте просто есть коллекция со счётчиками
findOneAndUpdate + $inc + returnNewDocument
В результате получаем новый уникальный ID
StaniFe
Не знаю как другие делают, но у меня в проекте просто есть коллекция со счётчиками
findOneAndUpdate + $inc + returnNewDocument
В результате получаем новый уникальный ID
Тоже сделал через
findOneAndUpdate. Вроде все ок. Покрыл тестами на многопоточность и все вроде ок
StaniFe
а на кой вам автоинкремент, какую бизнес задачу он решает?
Генерация номера полиса по истовому значению
Nick
Генерация номера полиса по истовому значению
возможно не погружен, но потребность именно в порядковых номеров?
 no
no
Не знаю как другие делают, но у меня в проекте просто есть коллекция со счётчиками
findOneAndUpdate + $inc + returnNewDocument
В результате получаем новый уникальный ID
+
Плагин даже есть (мангуст + отдельно для монго в доке)
Nick
Не знаю как другие делают, но у меня в проекте просто есть коллекция со счётчиками
findOneAndUpdate + $inc + returnNewDocument
В результате получаем новый уникальный ID
скажите а у вас именно бизнес потребность порядковые номера иметь? и для каких сущностей используется
Scorpi
скажите а у вас именно бизнес потребность порядковые номера иметь? и для каких сущностей используется
В основном для удобства поиска и коммуникации
Сущность - заказы (не совсем, но схоже)
no
вы тоже расскажите если возможно
Меня просто интересовал порядковый номер пользователя, вот и хотелось сделать что-то на подобии mysql авто инкремента
Nick
Меня просто интересовал порядковый номер пользователя, вот и хотелось сделать что-то на подобии mysql авто инкремента
недавно нашел тут сервис с автоинкрементом ид юзеров - все сдамплено теперь
Nick
Почему?
сдамплено изза автоикремента - просто поставить граббер который по порядку всех юзеров выгребает с сервиса
Nick
тоже самое касается публичных сервисов с заказами и иже с ними, если не настроена авторизация
Daniil
сдамплено изза автоикремента - просто поставить граббер который по порядку всех юзеров выгребает с сервиса
Ну если сервис даёт возможность получить данные о пользователе без авторизации под этим пользователем, то проблема не в автоинкременте явно
Daniil
А если это публичные данные, то почему нет
Nick
Ну если сервис даёт возможность получить данные о пользователе без авторизации под этим пользователем, то проблема не в автоинкременте явно
возможна ситуация когда недосмотрели, но банальный guid вместо автоинкремента уже закрывает часть вопросов с безой и плюс не нужно завязываться на особенности БД
Dmitriy
Коллеги, подскажите, как сделать запрос на получение данных с фильтрацией по boolean полю, но при этом его может не существовать.
Например мне нужно получить все записи, у которых поле manual = false либо его не существует
Dmitriy
понял, спасибо
Dmitriy
можно ли одним запросом обновить несколько записей в таблице с разными значениями полей апдейта?
Например у меня есть 10 _id и есть 10 статусов для каждого id которые нужно установить конкретной записи?
Если да, то подскажите в какую сторону смотреть либо может примеры у кого то есть?
 Mykola 🤷🏼♀️
Mykola 🤷🏼♀️
 Artem
Artem
Откуда может появляться duplicate key error, если я использую только findOneAndUpdate ??
Yaroslav
мб вы апдейтите значение ключа уникального индекса?
Artem
мб вы апдейтите значение ключа уникального индекса?
Я апдейт кидаю на юзера по его ID, в апдейт передаю имя
Artem
Я ищу юзера по ID, я не могу заменить ID, потому что если он раньше был другой, то я нового создам, потому что если он был другой, то он не найдется по новому
Artem
а имя не уникально
Artem
Сейчас перезапустил — ошибки нет
Artem
есть база
Users: {id, name}
От стороннего апи я получаю ID и имя пользователя и делаю такой запрос: findOneAndUpdate({id: recievedId}, {name: recievedName}, {upsert: true})
Artem
Он ругается что ID дублируется, буд-то второй раз создал юзера с таким же ID. Но тогда какого фига он его не нашел, раз он уже был?
Nico
Здравствуйте
Подскажите пожалуйста
А можно ли как-то узнать после подключения к БД - есть ли конкретная коллекция или нету?
Дело такое, что мне понравилась функция update( , upsert=True) вместо insert_one().
Но она не создает коллекцию если той нету.
Надо заранее написать скрипт проверки если ли коллекция и если нету - то создать ее через db.create_collection()
Как это сделать? типа функция check_is_collection()
Работаю на pymongo, на python
Nico
Нашел зацепку - при create_collection выдает exception если уже есть
Nico
так что изи)
Nico
боялся чтобы не перезаписывала
 Маrаt
Маrаt
Что делать если я не знаю мой документ будет больше 16 мб или нет? Есть какие-то техники чтобы если нужно то мог хранить больше?
Serhii
Что делать если я не знаю мой документ будет больше 16 мб или нет? Есть какие-то техники чтобы если нужно то мог хранить больше?
Вроде GridFS такие проблемы решает
https://docs.mongodb.com/manual/core/gridfs/#when-to-use-gridfs
 Anton
Маrаt
Anton
Маrаt
Это нормальная практика использовать каждый объект в коллекции как отдельную вещь? Например нужно написать древовидные комментарии, как каждый комментарий лучше сохранять? В отдельном объекте коллекции или 1 глубоким объектом всю цепочку комментариев сохранять?
Маrаt
просто мне кажется чем больше комментариев будет, тем больше придется тратить времени для поиска в дереве комментариев, если использовать глубокий объект
Anton
Не подскажете в чем ошибка (unknown top level operator: $in)
{
marks: {
$elemMatch: {
$or: [
{ $in: [‘BAR’, ‘BAZ’] },
{ $eq: 'all_marks' }
]
}
}
}
 Yaroslav
Yaroslav
Не подскажете в чем ошибка (unknown top level operator: $in)
{
marks: {
$elemMatch: {
$or: [
{ $in: [‘BAR’, ‘BAZ’] },
{ $eq: 'all_marks' }
]
}
}
}
$elemMatch используется для вложеных полей. например, если объект из массива marks имеет поля f1 и f2:
{
marks: {
$elemMatch: {
$or: [
{ f1: { $in: ['BAR', 'BAZ'] }},
{ f2: { $eq: 'all_marks' }}
]
}
}
}
в Вашем случае наверное нужно:
{
$or: [
{ marks: { $in: ['BAR', 'BAZ'] }},
{ marks: { $eq: 'all_marks' }}
]
}
Anton
$elemMatch используется для вложеных полей. например, если объект из массива marks имеет поля f1 и f2:
{
marks: {
$elemMatch: {
$or: [
{ f1: { $in: ['BAR', 'BAZ'] }},
{ f2: { $eq: 'all_marks' }}
]
}
}
}
в Вашем случае наверное нужно:
{
$or: [
{ marks: { $in: ['BAR', 'BAZ'] }},
{ marks: { $eq: 'all_marks' }}
]
}
Точняк, что-то у меня уже башка не варит, пора отдохнуть)
Yaroslav
Это нормальная практика использовать каждый объект в коллекции как отдельную вещь? Например нужно написать древовидные комментарии, как каждый комментарий лучше сохранять? В отдельном объекте коллекции или 1 глубоким объектом всю цепочку комментариев сохранять?
нормально, но не само по себе, а в зависимости от обстоятельств - размер документов, количество документов, количество комментариев, какого рода поиск нужен и т.д..
Вашем случае думаю можна сделать двумя путями:
1) положить все комменты в один массив, но деревовидность смоделировать ссылками друг на друга
2) выделить первые основные комментарие в отделый документ в отдельной коллекции, а потом комменты к основным коммментам тоже положить в один массив со ссылками друг на друга.
но на самом деле нужно понимать Вашу задачу во всех деталях что-бы смоделировать структуру наиболее эффективно.
 yopp
yopp
Это нормальная практика использовать каждый объект в коллекции как отдельную вещь? Например нужно написать древовидные комментарии, как каждый комментарий лучше сохранять? В отдельном объекте коллекции или 1 глубоким объектом всю цепочку комментариев сохранять?
Дешевле и проще всего Materialized path. Пока количество комментариев не влияет на скорость выборки (это вероятно порядки десятков миллионов), то хранить каждый комментарий в отдельном документе
yopp
Хранить в дереве массивов/словарей очень неэффективно и будут огромные сложности с выборками.
Кешировать в родительском объекте тоже не стоит пока не будет реальных проблем с производительностью, так как это добавит множество сложностей
 Александр
Александр
всем привет
кто-нибудь сталкивался с падением mongo, когда она отъедает много памяти?
пробовал поставить
storage:
engine:.
wiredTiger:
engineConfig:
cacheSizeGB: 5
перестала запускаться.
сейчас стоит :
storage:
engine:.
wiredTiger:
версия mongo 4.0.12
Подскажите как лечить проблему?
Daniil
Но лучше дать столько памяти, сколько нужно, стоит это копейки
Александр
Ограничить размер кеша
а это разве не оно cacheSizeGB: 5 ? в том-то и дело, что не могу ограничить, при таком конфиге не стартует.
Daniil
Daniil
Там минимальный размер 250мб по моему
Daniil
Там понятное дело еще под другие нужды монга памят возьмёт
Daniil
Сколько всего ОЗУ доступно?
Nick
кеш монги - это кеш, а не память нужная для выполнения запросов. Вот память под выполение именно действий ограничить нельзя
Александр
с конфигом storage:
engine:.
wiredTiger:
engineConfig:
cacheSizeGB: 5
не стартует. как ограничить?
Daniil
с конфигом storage:
engine:.
wiredTiger:
engineConfig:
cacheSizeGB: 5
не стартует. как ограничить?
Не стартует по какой причине?
 Иван
Иван
Здравствуйте! Подскажите пожалуйста профилировщик для .NET Core. Бд съедает всю память и приложение валится. Пытаюсь понять в каких запросах проблема. Спасибо!
 Sergey
Sergey
Здравствуйте! Подскажите пожалуйста профилировщик для .NET Core. Бд съедает всю память и приложение валится. Пытаюсь понять в каких запросах проблема. Спасибо!
https://docs.mongodb.com/manual/tutorial/manage-the-database-profiler/
Попробуйте это
Иван
https://docs.mongodb.com/manual/tutorial/manage-the-database-profiler/
Попробуйте это
Спасибо! Попробую!
Может быть есть какая либо для C#?
Sergey
Спасибо! Попробую!
Может быть есть какая либо для C#?
С c# не знаком. Попробуйте посмотреть метод explain, в вашей библиотеке, но если приложение падает, вам это мало чем поможет
Anonymous
это норм что монгус записал значение без рекваерд поля и не выдал ошибку?
Anonymous
записываю через findOneAndUpdate
Anonymous
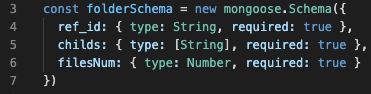 Евгений
Евгений
Народ
Евгений
Подскажите, использует ли монго индексы автоматически или надо указывать?
Евгений
Потому что стало много объектов, и начало это все тормозить безбожно
Евгений
Использую драйвер для .net
Anonymous