 Nick
Nick


формат настройки:
A: [0-50);
B: [50-100);
в коде
rnd.nextInt(100)
далее выбор варианта в зависимости от диапазона
Nick
никаких компенсаций это не требует и достаточно в базе только сделать счетчики попадания в каждый из вариантов.
Компенсации не нужны, т.к. у вас в рамках А/Б долно быть написано минимальное количество показов каждого варианта, как только на обоих вариантах достигнуто свое мин значение - значит А/Б можно считать проведенным
 Eugen
Eugen
https://stackoverflow.com/questions/33268955/mongodb-aggregation-group-by-date-even-if-doesnt-exist
Eugen
нашел что-то такое
Eugen
)
Nick
https://stackoverflow.com/questions/33268955/mongodb-aggregation-group-by-date-even-if-doesnt-exist
собсна как и сказано выше - делается в коде приклада
 Devperk
Devperk
никаких компенсаций это не требует и достаточно в базе только сделать счетчики попадания в каждый из вариантов.
Компенсации не нужны, т.к. у вас в рамках А/Б долно быть написано минимальное количество показов каждого варианта, как только на обоих вариантах достигнуто свое мин значение - значит А/Б можно считать проведенным
кажется я понял
1) get A or B by rand
2) test = find_and_inc counter
3) if (test.counter_A >= limit and test.counter_B >= limit) -> stop_test()
Devperk
вроде получается довольно простая схема, спасибо!)
Nick
кажется я понял
1) get A or B by rand
2) test = find_and_inc counter
3) if (test.counter_A >= limit and test.counter_B >= limit) -> stop_test()
в 3 AND, т.к. надо чтобы оба прошли лимит
Devperk
точно, поправил для истории, спасибо
 Google
Google
 Google
Google
🆘🆘🆘🆘
 Konstantin
Google
Konstantin
Google
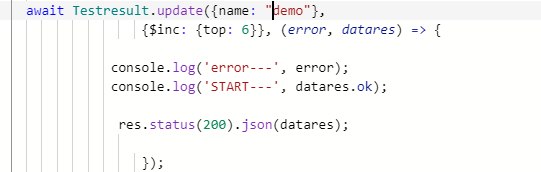
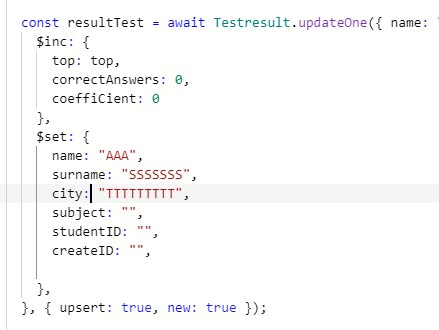
Вот не могу понять что у меня в top: 0 число когда я обновляю получеться 12
Anonymous
Включи профилирование в бд, не исключено что inc делается 2 раза. У тебя случайно не 2 инстанса приложения в БД смотрят?
Rustam
Здравствуйте! Подскажите, пожалуйста, как правильно/лучше забекапить монгу, в которой одна из баз имеет 1.5 миллиарда записей? Пробовал через mongodump/pbm. В целом pbm с бекапом сравляется норм, но вот рестор такой базы это полный ужас. Я пока что думаю что лучшее решение будет rsync с дб локом. К сожалению сама база лежит на рутовом диске в 3 ТБ и снимать снепшот тоже не вариант
Andrey
Очень долгий бекап и еще более более долгий рестор бекапа
Ну так и данных сколько - много, я вчера коллекцию бэкапил, 800 гигов, долго, но а как?
Rustam
Меня больше смущает не время бекапа, а время рестора.
Rustam
За почти трое суток только 30% базы восстанавилось
Andrey
Меня больше смущает не время бекапа, а время рестора.
Вы посчитайте сколько весит база, посчитайте скорость записи куда пишете. Может долго - при таких условиях железа и канала куда бэкап пишете - это норм?
Andrey
За почти трое суток только 30% базы восстанавилось
Я вообще в dev делал монгу в контейнер, базу в отдельную директрию через volume, потом докер стоп и копируешь базу как директорию куда надо, но это dev.
Rustam
Вы посчитайте сколько весит база, посчитайте скорость записи куда пишете. Может долго - при таких условиях железа и канала куда бэкап пишете - это норм?
Я вот сейчас тесты делаю. Бекап лежит локально рядом с монгой. машина - baremetal сервер.
Google
 Dan
Dan
Привет, кто может подсказать с таким вопросом. Есть продукты и есть категории. Для категории задаю
owner: [{
type: Types.ObjectId,
ref: "MyProduct"
}]
для продуктов
category: {type: Types.ObjectId, ref: "MyCategory"}
Dan
Категории я уже добавил, там у меня просто owner с пустым массивом
Dan
При добавления продукта что нужно указать что бы они были частью
Nick
Vasily
Привет!
Как распаралелить можно запросы к mongo через Python?
Nick
питон и распараллелить вроде как не сочетаются, в лучшем случае асинхронные запросы
 Ivan
Ivan
Все привет, могли бы подсказать, мне нужен кластер из 3х реплик (без шардирования)
Я запускаю 2 роута, 3 конфиг сервера и 3 реплики
Но при подключении к роуту и попытке создания базы получаю ошибку
"unable to initialize targeter for write op for collection test.user :: caused by :: Database test not found :: caused by :: No shards found"
Ivan
Как мне указать роуту реплики?
Как я понимаю шарды добавляются вот так в конфиге
sh.addShard("rs-shard-01/shard01-a:27017")
Andrey
Andrey
Через очередь
Nick
Через общую память можно.
а что делать когда один из процессов помрет? поэтому и говорю что не дружит ибо многовато телодвижений
Andrey
Nick
Отслеживать как помер.
спасибо за комментарии, я просто думал что уже чтото поменялось в мире питона, но пока то что помню актуально
Andrey
спасибо за комментарии, я просто думал что уже чтото поменялось в мире питона, но пока то что помню актуально
Ну например. У меня в базу пишется 8 процессами. Из mp async pool. Если запись не прошла или что то еще. Данные идут в файл. Потом можно обработать файлы с ошибочными данными.
Andrey
На чтение
Как на чтение? У вас на входе условно должны быть список аргументов по которым ищете. Каждый запрос в процесс. Поэтоиу и спросил как читать.
Andrey
Как на чтение? У вас на входе условно должны быть список аргументов по которым ищете. Каждый запрос в процесс. Поэтоиу и спросил как читать.
Это если нельзя в 1 запрос оформить к базе.
Vasily
Это если нельзя в 1 запрос оформить к базе.
Есть 500+ коллекций
Сейчас в цикле пробегаюсь по всем и получаю данные за нужный временной промежуток (одинаковый для всех запросов
Те меняется только имя коллекции
Andrey
Есть 500+ коллекций
Сейчас в цикле пробегаюсь по всем и получаю данные за нужный временной промежуток (одинаковый для всех запросов
Те меняется только имя коллекции
Делаете функцию в которую передаете аргументами connection string и аргументы. Она читает возвращает данные. Создаете pool из mp и передаете функцию и аргументы. Позже условный пример скину.
Andrey
А вообще. Если таблицы с одной схемой. То я думаю лучше посмотреть как сделать View от MongoDB. Может можно одним запросом. Но тут меня поправят, можно ли делать View на n коллекций
Andrey
Есть 500+ коллекций
Сейчас в цикле пробегаюсь по всем и получаю данные за нужный временной промежуток (одинаковый для всех запросов
Те меняется только имя коллекции
Аргументы у функции лучше сделать: connection_string, database, collection_name, query. В этой функции создаете клиента делаете выборку из коллекции и вовращаете результат. Очень хороший пример из документации к python у них на сайте. Можно так же сделать. https://docs.python.org/3/library/concurrent.futures.html
Вам лучше ProcessPoolExecutor. Там можно прям по примерам из документации сделать.
Andrey
благодарю!
Там из документации по ссылке он проверяют список чисел на простоту. У них список чисел - это ваши коллекции. А функция проверки на простоту - ваша функция в которой цепляетесь к базе и выборку делаете. Условно конечно - но концепт очень понятен.
Andrey
Колличество процессов больше чем "ядер" - не делаете.
 Denis
Denis
Все привет, могли бы подсказать, мне нужен кластер из 3х реплик (без шардирования)
Я запускаю 2 роута, 3 конфиг сервера и 3 реплики
Но при подключении к роуту и попытке создания базы получаю ошибку
"unable to initialize targeter for write op for collection test.user :: caused by :: Database test not found :: caused by :: No shards found"
Сначала пишешь что без шардирования, а потом шарды добавляешь. Тебе реплика сет или шардированный кластер? Для реплика сета не нужны конфиг сервера и тд, только нечетное (желательно) кол-во реплик
Ivan
Сначала пишешь что без шардирования, а потом шарды добавляешь. Тебе реплика сет или шардированный кластер? Для реплика сета не нужны конфиг сервера и тд, только нечетное (желательно) кол-во реплик
Да только реплика, спасибо, уже понял что не нужны конфиги и роуты
Illia
У меня есть коллекция с обьектами, где хранится история изменений. То есть поле field обозначает что изменилось и соответсвенно староеи новое значение. Можно ли в одном запросе делать lookup с условием? ТО есть, если field == А, lookup будет брать с коллекции Б, если field == В, lookup будет брать с коллекции Д?
 Марк
Марк
Всем привет) Заранее сорри за глупые вопросы)
Только сегодня начал работать с MongoDB. Необходимо извлекать данные из этой БД. Скачал Compass, подключился, почитал, как писать find запросы для выборки данных.
Но не понимаю, куда их в compass писать, где консоль? Подскажите, пжл
Andrey
скачай robo3T бесплатную - может там попроще будет
Dmitry
 Anton
Anton
Compound индексы будут быстрее работать нежели отдельно созданные?
Viktar
Зависит от ваших запросов. Если специально под запрос, то быстрее
Yaroslav
Если вопрос в том, сможет ли монга вместо compound индекса заюзать несколько обычных - то, хотя в документации про это и написано, лично я в версии 3.6 монги не видел на практике, чтобы это работало
Andrey
Если вопрос в том, сможет ли монга вместо compound индекса заюзать несколько обычных - то, хотя в документации про это и написано, лично я в версии 3.6 монги не видел на практике, чтобы это работало
? А можно подробней. То есть если индексы построены по 2 полям отдельно, то поиск по значениям в этих полях не работает так, как 1 индекс по этим полям?
Марк
Спасибо! Подскажите, еще пжл) А как из консоли в компассе сохранить результат в csv файл?)
Марк
скачай robo3T бесплатную - может там попроще будет
Марк
https://youtu.be/YxZpf5FqZjk
Andrey
коллеги, тут был вопрос - медленно восстанавливается (через mongorestore). Я сам было подумал - дело в железе у вопрошающего. Сейчас столкнулся с такой же ситуацией. Был сделан дамп коллекции через mongodump. Файл небольшой - 10gb, записей 8 миллионов. Сейчас его ресторю на primary - в существующую коллекцию. в коллекции 3 индекса - понятно, но чтоб так медленно - уже 2 час пошел.
Andrey
мне уже кажется, что проще было удалить индексы, зарестористь и заново построить индексы?
Yaroslav
? А можно подробней. То есть если индексы построены по 2 полям отдельно, то поиск по значениям в этих полях не работает так, как 1 индекс по этим полям?
Ну да, механизмы разные
1. Если у вас есть один индекс по полю A, а вы делаете запрос по полям A и Б, тогда монга заюзает индекс A, поднимет все подходящие документы, отфильтрует по полю Б и вернет вам что останется
2. Если у вас компаунд индекс по полям A, Б - тогда при запросе по полям А и Б шаг с чтением подходящих документов будет пропущен, по индексу монга поймет какие документы нужно вернуть и вернет
Если у вас два обычных индекса по полям А и Б, то на моем опыте c Mongo3.6 при запросе по полям А Б будет ситуация 1, хотя в доках описан возможный вариант использования их двух и объединения https://docs.mongodb.com/manual/core/index-intersection/
Andrey
Ну да, механизмы разные
1. Если у вас есть один индекс по полю A, а вы делаете запрос по полям A и Б, тогда монга заюзает индекс A, поднимет все подходящие документы, отфильтрует по полю Б и вернет вам что останется
2. Если у вас компаунд индекс по полям A, Б - тогда при запросе по полям А и Б шаг с чтением подходящих документов будет пропущен, по индексу монга поймет какие документы нужно вернуть и вернет
Если у вас два обычных индекса по полям А и Б, то на моем опыте c Mongo3.6 при запросе по полям А Б будет ситуация 1, хотя в доках описан возможный вариант использования их двух и объединения https://docs.mongodb.com/manual/core/index-intersection/
благодарю, странно - Если у вас два обычных индекса по полям А и Б, то на моем опыте c Mongo3.6 при запросе по полям А Б будет ситуация 1, хотя в доках описан возможный вариант использования их двух и объединения - , надо читать
Viktar
Искать пересечения довольно ресурсозатратно. Посмотрите какие планы строит монга и какие реджектит.
Антон
explain что ли не работает с aggregate?
как тогда можно узнать время выполнения аггрегации?
 yopp
yopp
explain что ли не работает с aggregate?
как тогда можно узнать время выполнения аггрегации?
Работает. Если вы в шелле делаете, то db.fill.explain().aggregate(...)
Антон
Работает. Если вы в шелле делаете, то db.fill.explain().aggregate(...)
да, пробовал такое. но там я не вижу чего-нибудь связанного с executionTimeMillis
yopp
explain('executionStats')
Антон
аа, вот оно как. спасибо
Rodjer
Всем привет, вопрос есть ли у монги официальное приложение на мобилу чтобы базу чекать?