 Mike
Mike

 Mike
Mike
вот две модельки
Mike
 Mike
Mike
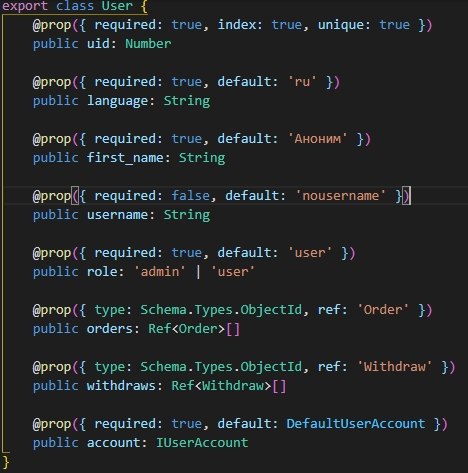
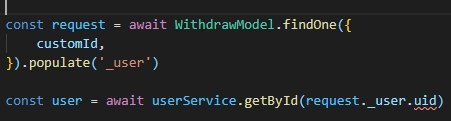
вот делаю запрос
Mike
 Mike
Mike
ts ругается
Mike
сталкивался кто-нибудь с подобным?
 Максим
Максим
сталкивался кто-нибудь с подобным?
Не сталкивался, но ты пытаешься положить тип юзер в поле типа обжект ид. Это и не нравится тс.
 Дмитрий
Дмитрий
Очевидно ж что request._user это ObjectId откуда у него ещё и ключ uid?
Mike
Очевидно ж что request._user это ObjectId откуда у него ещё и ключ uid?
после populate в консоли все отображается, все значения есть
Дмитрий
В рантайме можете делать с данными что угодно, но тайпскрипт не знает что там будет в реузьтате populate, поэтому и ругается
Дмитрий
Погуглите по ключевым: typescript mongoose populate
 Вовчик
Вовчик
Здравствуйте, подскажите пожалуйста решение следующей ситуации: есть коллекция продуктов, у которых есть множество возможных полей, в самой коллекции содержится несколько продуктов с самыми популярными комбинациями. Есть также коллекция заказов, которая содержит масив всех продуктов, которые купил покупатель, но так-как комбинации могут быть самыми разными, я не добавляю созданный покупателем продукт в коллекцию продуктов. То-есть продукт хранится только в заказе под видом объекта с похожими как у продукта полями, а не как ссылка в коллекцию продуктов. Правильный ли это подход или нужно добавлять каждый продукт с различной комбинацией параметров в коллекцию продуктов, но при этом мне не нужно на фронте отображать всевозможные сочетания параметров продукта.
Anton
 yopp
yopp
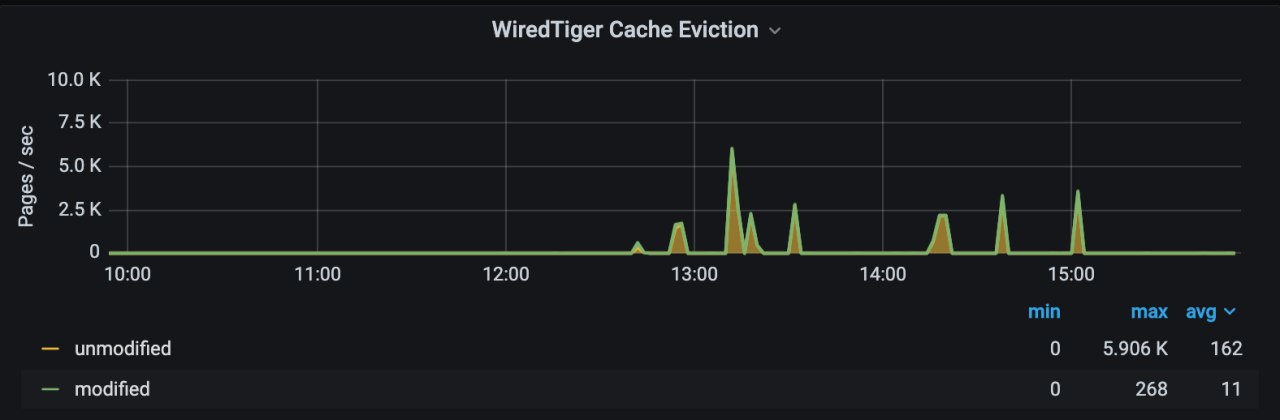
Не стоит этого делать. У
вас из памяти выгружаются немодифицироыанные страницы, а значит IO они не генерируют. Думаю что это подтвердят данные с дисковой подсистемы и вы увидите что там преобладает не write, а read io
Скорее всего это говорит о том, что у вас в эти моменты какие-то запросы требуют очень много памяти, и это разновидность cache trashing.
Ищите что это за запросы создают такую ситуацию. Возможно что-то мимо индексов едет.
yopp
Не стоит этого делать. У
вас из памяти выгружаются немодифицироыанные страницы, а значит IO они не генерируют. Думаю что это подтвердят данные с дисковой подсистемы и вы увидите что там преобладает не write, а read io
Скорее всего это говорит о том, что у вас в эти моменты какие-то запросы требуют очень много памяти, и это разновидность cache trashing.
Ищите что это за запросы создают такую ситуацию. Возможно что-то мимо индексов едет.
В том смысле что из кэша выгружаются страницы чтоб освободить память для данных которые требуются для выполнения запроса, судя по тому что нет modified eviction, это запрос на чтение.
Read IO будет следствием того что данные с диска в память загружаются
Алексей
Добрый день. Подскажите, пожалуйста, почему mongodb долго считает count и как это время можно сократить?
версия mongodb 4.2.8
у меня коллекция из 14млн документов
Такой pipeline
[{
$match: {
'variables.sip_h_X-AUTH-ACCOUNT': '1210',
'variables.direction': 'inbound'
}
}, {
$sort: {
'variables.start_stamp': -1
}
}, {
$count: 'count'
}]
есть отдельные индексы по полям variables.start_stamp, variables.sip_h_X-AUTH-ACCOUNT, variables.direction
помогут ли составные индексы?
yopp
Попробуйте убрать $sort. Но я не уверен что планировщик будет пересекать ваши отдельные индексы
Алексей
если сделать explain по match то он использует только один индекс. variables.sip_h_X-AUTH-ACCOUNT
Алексей
Попробуйте убрать $sort. Но я не уверен что планировщик будет пересекать ваши отдельные индексы
неа, не особо. все еще ищет)
у меня все индексы desc(-1). Тоесть свежие записи он ищет быстро.
я так понимаю он все равно шерстит всю базу чтобы посчитать количество
Алексей
хм. по одному полю 'variables.sip_h_X-AUTH-ACCOUNT': '1210', считает. достаточно шустро.
yopp
yopp
Ещё сделайте projection _id: 0, и два поля из индекса. Без $sort, в этом случае оно должно сделать covered query
Алексей
Anton
В том смысле что из кэша выгружаются страницы чтоб освободить память для данных которые требуются для выполнения запроса, судя по тому что нет modified eviction, это запрос на чтение.
Read IO будет следствием того что данные с диска в память загружаются
да Read IO диска тоже в эти моменты возрастает резко
yopp
да Read IO диска тоже в эти моменты возрастает резко
Включите профайлер и посмотрите что туда упадёт
yopp
Думаю что можно безопасно включить его для
yopp
*для запросов больше секунды
yopp
Чтоб шума меньше было
 Roman
Roman
привет у меня есть старая коллекция в монгодб, там 200 записей , как мне из всех 200 записей забрать указанные поля, типо store, name, id, email
Roman
я собираюсь потом эти данные затолкать уже через типизацию mongoose
Roman
или что почитать ? я в монге неделю только, еще не все знаю
Максим
Если правильно понял тебя.
Максим
ща попгуглю что эт
Только не запутайся, там для драйвера одно апи, для консоли немного другое.
Roman
Только не запутайся, там для драйвера одно апи, для консоли немного другое.
я уже более менее вижу разницу, спасибо )
Максим
_I'd:0 чтоб ид убрать
Дмитрий
Подскажите пожалуйста, здесь есть какая то ошибка ?
filter: {email: {$eq: "nikolay"}}
поидее должны вернуться все пользователи у которых в email присутствует nikolay ?
yopp
Подскажите пожалуйста, здесь есть какая то ошибка ?
filter: {email: {$eq: "nikolay"}}
поидее должны вернуться все пользователи у которых в email присутствует nikolay ?
Которы полностью совпадают со строкой «nikolay»
Дмитрий
Я уже понял))) Помню что в другом месте делал, а там перепутал функции. Сделал через regex ))))
 Vladimir
Vladimir
Всем привет. Господа, подскажите плиз, куда смотреть, а то я в монге не особо. Имеется aws documentdb, телнет к нему на порт 27017 проходит, но при попытке коннекта к нему через mongo cli он пишет
connecting to: mongodb://inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017/test?gssapiServiceName=mongodb 2020-10-22T14:44:59.966+0000 D NETWORK [thread1] creating new connection to:inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017 2020-10-22T14:45:00.039+0000 D NETWORK [thread1] connected to server inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017 (172.31.33.128)
и висит... что это может быть?
yopp
Всем привет. Господа, подскажите плиз, куда смотреть, а то я в монге не особо. Имеется aws documentdb, телнет к нему на порт 27017 проходит, но при попытке коннекта к нему через mongo cli он пишет
connecting to: mongodb://inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017/test?gssapiServiceName=mongodb 2020-10-22T14:44:59.966+0000 D NETWORK [thread1] creating new connection to:inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017 2020-10-22T14:45:00.039+0000 D NETWORK [thread1] connected to server inx-dev.cluster-csvtkvrvpqap.eu-west-1.docdb.amazonaws.com:27017 (172.31.33.128)
и висит... что это может быть?
documentdb это не монга, это монгоподобный интерфейс к documentdb, с очень ограниченным набором фич и официально ни кем не поддерживаемый.
Судя по connected to server, соединение устанавливается, но так как нет баннера о подключении, возможно сервер не отвечает нужным образом.
Сомневаюсь что с mongo-shell последних версий у вас что-то заработает. Попробуйте с 3.0 или 2.4
Vladimir
в амазоне написано, что версия 3.6. Точно такую же 3.6 я поставил на клиент. Или это разные версии?
yopp
Единственные кто вам могут помочь с documentdb, это инженеры aws.
yopp
в амазоне написано, что версия 3.6. Точно такую же 3.6 я поставил на клиент. Или это разные версии?
Попробуйте более ранние версии
Vladimir
ну то есть так, с ходу никаких явных ошибок не видно?
yopp
Там есть аутентификация?
yopp
Возможно вы не передаёте реквизиты доступа, а оно по этому не отвечает на ismaster, по этому консоль и висит
 Anton
Anton
А в mongo можно объединять коллекции в группы?
Viktar
Добрый вечер, подскажите по каким полям лучше сделать шардирование, что бы поднять перформанс по чтению из сщдукции при запросах `{'phones.number': {$in: [value1,.. , valueN]}}
{names: {$elemMatch: {firstName: 'value', lastName: 'value'}}}
{addresses: {$elemMatch: {zip: value, zip4: value}}}`
и
{persistentIndividualId: value}
колекция ~90-100 Гб
количество записей около 150 млн
Gregory
привет всем! только начинаем использовать монгу) что посоветуете почитать про БД?
Gregory
тока не разрабное) а что нить более Operations, есть какие нить годные книги?
Anonymous
Ребят, всем ку. Кто может подсказать, как грамотно все организовать.
Есть два микросервиса, условно
channels и ads
каждый микросервис пишет в свою коллекцию
в сервис ads приходит запрос, на получение списка объявлений
/api/v1/ads/list
в самой функции, мне нужно одним запросом сходить в коллекцию channels и собрать каналы по фильтрам gt,lt
крч, допустим получаю массив из 20 элементов
потом же мне нужно получить информацию, связанную именно с деталями объявления для каждого канала (коллекция ads)
это нормальная практика:
- одним запросом получаю список каналов
- потом в for range для каждого канала делаю индивидуальный запрос на получение инфы. Тоесть если в списке 20 каналов (которые достал одним запросом)
после придется делать еще 20 запросов, что бы получить дополнительную информацию для каждого канала
Это вообще здоровая практика? Или сервер сразу просядет при повышении rps, здесь стоит применить что-то типа агрегации или пайплайнов?
в итоге мне нужно собрать примерно следующую структуру
{
"ads": [
{
"channel_id": 1, // получаю из коллекции channels
"conditions": [] // получаю из коллекции ads
},
{
"channels_id": 2,
"conditions": []
},
{
"channel_id": 3,
"conditions": []
}
]
}
список из channel_id получаю одним запросом, но потом для каждого мне нужно забрать conditions из другой коллекции по фильтру channel_id
тоесть это одним запросом уже не сделать
или может в в монге можно сделать db.ads.find({"_id": [1, 2, 3] ]}) ?
объяснил как мудак, понимаю))))
но может кто-то сможет просвятить?)
 Alexandr
Viktar
Alexandr
Viktar
Выглядит как работа с реляционной базой
Anonymous
Выглядит как работа с реляционной базой
наоборот здесь меня монга выручает, т.к. эти conditions могут быть вообще разными)
Anonymous
благодарю! звучит как вариант, сейчас доку раскурю немножк
Anonymous
тоесть и так получится?
db.ads.find({"_id": {$in: [1, 2, 3]}, "price": {"$gt": 100, "$lt": 300}})
?
Anonymous
изи) благодарю еще раз)
Viktar
Примерно так. Только скобочки не там. )
Viktar
Json в фильтре должен получится
Anton
Включите профайлер и посмотрите что туда упадёт
Нашли запрос, который выполнялся на большой коллекции без использования индексов. Индекс повесили. Надеюсь, что проблема будет решена. Спасибо большое за наводку
Aleksey
Всем привет.
Может кто знает как сделать копию базы, которая может находиться на другом сервере и служить просто как актуальный архив рабочей базы, в которую сливаются все изменния в режиме онлайн?
Пытался понять репликацию, но она вроде для распределения нагрузки и как то там сложно все и ограничения на саму базу по поводу _id индексов если я правильно понял.
yopp
Всем привет.
Может кто знает как сделать копию базы, которая может находиться на другом сервере и служить просто как актуальный архив рабочей базы, в которую сливаются все изменния в режиме онлайн?
Пытался понять репликацию, но она вроде для распределения нагрузки и как то там сложно все и ограничения на саму базу по поводу _id индексов если я правильно понял.
Это кейс для репликации. Вам необходимо поднять single node replica set и добавить туда hidden member, для резервного копирования
Viktar
Всем привет.
Может кто знает как сделать копию базы, которая может находиться на другом сервере и служить просто как актуальный архив рабочей базы, в которую сливаются все изменния в режиме онлайн?
Пытался понять репликацию, но она вроде для распределения нагрузки и как то там сложно все и ограничения на саму базу по поводу _id индексов если я правильно понял.
Как раз нет. Она предназначена для переключения в случае сбоя. Распределение нагрузки это побочный эффект и только на чтение. Может вы путаете с шардированием? Оно как раз предназначено для распределения нагрузки
Aleksey
Спасибо. А replica set имеет какие то ограничения? или можно без каких либо изменений структуры взять любую базу и переключить в этот режим?
Viktar
На мой взгляд именно так и есть
Aleksey
Как раз нет. Она предназначена для переключения в случае сбоя. Распределение нагрузки это побочный эффект и только на чтение. Может вы путаете с шардированием? Оно как раз предназначено для распределения нагрузки
Возможно путаю, но даже если это реплика, то цель не переключение, а просто онлайн архив. Сейчас база архивируется по ночам, но записей уже много, и почему то монгодамп слетает при создании архива. Да и сам архив уже под 70 гиг
yopp
Ещё раз повторюсь, что ваш кейс это кейс для single node replica set и hidden member
Aleksey
спасибо 👍
yopp
В этой конфигурации реплика с одной нодой будет работать почти так-же как standalone топология. Разница только в наличии журнала репликации, который можно использовать для change stream и транзакций. А hidden member не видим для клиентов, не может учавствовать в выборах и не может обслуживать запросы. В результате это и есть online архив.
Для него ещё можно настроить delayed replication, создав таким образом окно для восстановления после логических ошибок, например удалённой коллекции.