/Всем привет можете помочь
Дублирование записей в mongodb
Есть приложение написанное на node expressjs, база используется mongodb.
Алгоритм такой: когда приходят пост данные, производится поиск записи по полям name, server, fraction. Если такая запись есть то обновить, если нет то создать.
Проблема в том, что при большом количестве запросов, если не находит запись, то создает не одну запись, а несколько. Я предполагаю что пока mongodb создает запись, следующий поиск не дает результата, ведь запись еще не создана и поиск не дает результата, и mongodb создает еще одну идентичную запись, хотя должна обновить.
Как решить эту проблему?
https://docs.mongodb.com/manual/reference/method/db.collection.update/#upsert-behavior
 yopp
yopp


 Alexandr
Alexandr
newReport.updateOne({upsert: true}) так правильно ‼️
To avoid inserting the same document more than once, only use upsert: true if the query field is uniquely indexed.
из доки, так что посмотри какое поле ты можешь сделать уникальным индексом и используй его
 Google
Google
 Google
Google
 Nemo
Nemo
Можно так,
populate({ path: 'tarifGroup', populate: { path: 'another object' }})
спасибо. спасло от гемора с агрегатом. что мне в другом месте подсказали ХД
Google

 Daniyar
Daniyar
ку ребят
Daniyar
это нормально хранить в базе на разных языках? 3-4 языка на пример: titleRu, titleEn, titleKg
Daniyar
ну само собой description и тд, что подразумевает себя string
Daniyar
или есть более хорошие решения?
Yaroslav
а какие у вас критерии нормальности/хорошести?
Daniyar
ну короче норм да?
Daniyar
если так сделаю
Yaroslav
опять же смотря для чего, если вдруг захотите текстовой индекс строить для каждого языка - будет плохо, тк у монги на коллекцию только один текстовой индекс
если текстовой поиск не будете использовать, то в целом ок
Daniyar
опять же смотря для чего, если вдруг захотите текстовой индекс строить для каждого языка - будет плохо, тк у монги на коллекцию только один текстовой индекс
если текстовой поиск не будете использовать, то в целом ок
почему только один?.. вроде несколько использовал на старых проектах и норм работал
yopp
это нормально хранить в базе на разных языках? 3-4 языка на пример: titleRu, titleEn, titleKg
Это неудобно и нормально не индексируется.
title: [{locale: ru, text: ...}, {locale: es, text: ..} ...]
Daniyar
Это неудобно и нормально не индексируется.
title: [{locale: ru, text: ...}, {locale: es, text: ..} ...]
дам индекс на title и будет все языки индексировать?
yopp
Точнее на title.text
Daniyar
а да
Daniyar
точно
Daniyar
спасибо
Google
var modelDoc = new MyModel({ foo: 'bar' });
MyModel.findOneAndUpdate(
{foo: 'bar'}, // find a document with that filter
modelDoc, // document to insert when nothing was found
{upsert: true, new: true, runValidators: true}, // options
function (err, doc) { // callback
if (err) {
// handle error
} else {
// handle document
}
}
);
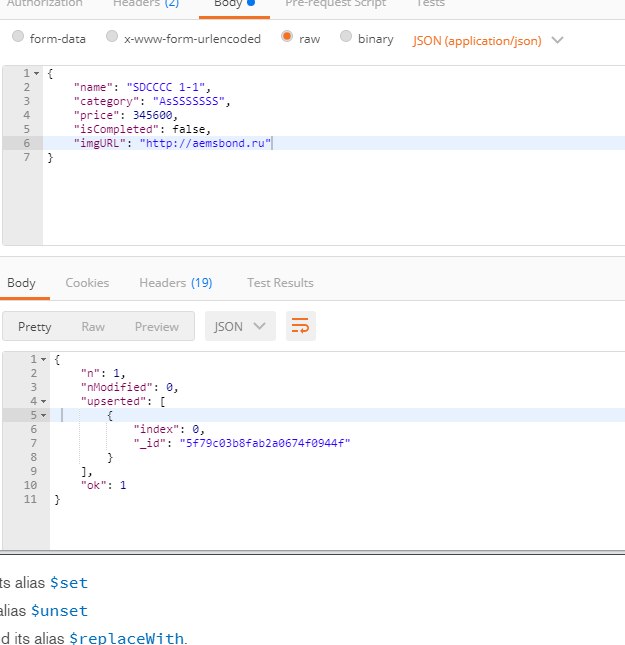
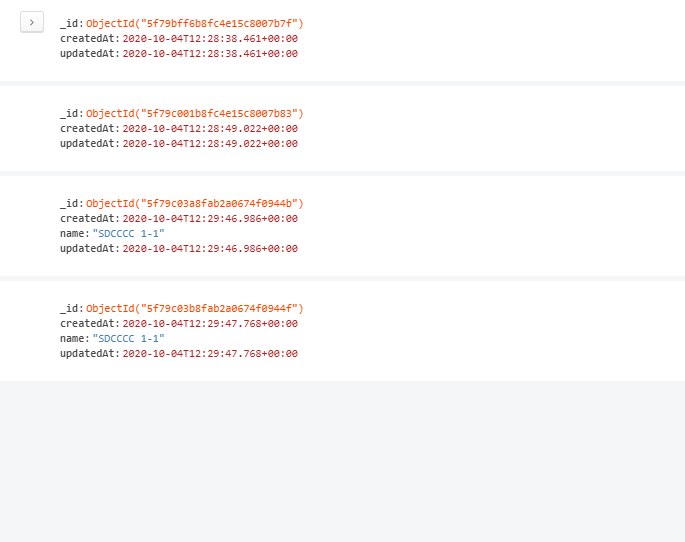
можете помочь по чемуто при если есть в базе точная копия то оно не обновляет
Google
 Google
Google
‼️‼️‼️‼️ sos
 Anatoly
Anatoly
var modelDoc = new MyModel({ foo: 'bar' });
MyModel.findOneAndUpdate(
{foo: 'bar'}, // find a document with that filter
modelDoc, // document to insert when nothing was found
{upsert: true, new: true, runValidators: true}, // options
function (err, doc) { // callback
if (err) {
// handle error
} else {
// handle document
}
}
);
можете помочь по чемуто при если есть в базе точная копия то оно не обновляет
Вторым параметром в функции должен быть объект с полями которые то хочешь изменить, а третий опции
Google
Google
{foo: 'bar'}, // find a document with that filter
modelDoc, // document to insert when nothing was found
{upsert: true, new: true, runValidators: true},
Anatoly
Ага не заметил второй параметр.
Google
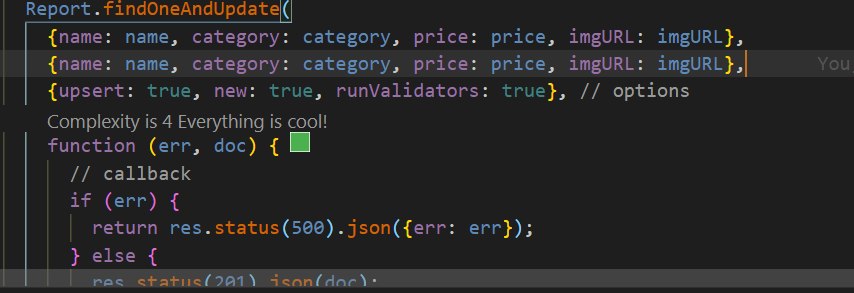
так ?
Anatoly
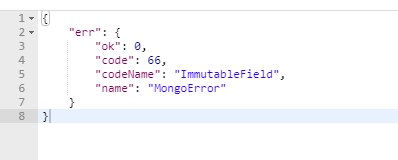
А поле Foo у тебя в модели случайно не подмечено как immutable = true?
Google
 Google
Google
А поле Foo у тебя в модели случайно не подмечено как immutable = true?
Google
 Google
Google
короче проблема теперь если все совподает то оно обновляется а если скажем в name что-то изменился получаю такую ошибку
Google
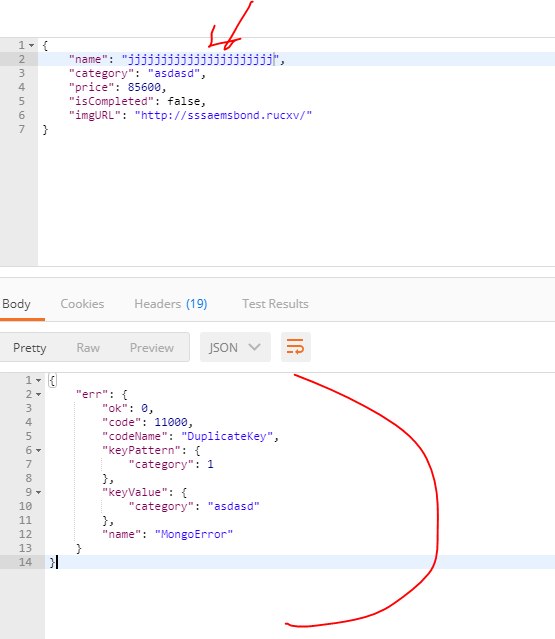 Google
Google
как исправить |?
Viktar
А какое поле у вас является ключом?
 SuleYman
SuleYman
Всем привет немного запутался с NoSql, можно ли использовать MySQL и монго вместе? И где лучше их рассматривать?
 inqfen
inqfen
У тебя задача-то какая?
SuleYman
Да есть CRM используется MySQL если будет награждена данными, как можно будет кешировать?
inqfen
При чем тут монга вообще?
inqfen
Делай какие-то миддлвари с кешами
inqfen
Тот же редис
inqfen
Эти кеши все равно нужно писать руками, явно и аккуратно
inqfen
забудь мемкеш, его все приличные люди уже лет 8 как выкинули
04MTTM07
Всем привет немного запутался с NoSql, можно ли использовать MySQL и монго вместе? И где лучше их рассматривать?
эксплуатируется бот, часть функционала на mysql, часть переведена на монго.
Функционирует с двумя (код на golang), пока все переписываю на монго.
Сложность только в том, что иногда приходится дублировать какие-то данные в обе бд - не забывать про это. В остальном подводных пока не заметил.
Бот при этом активно юзается сторонними пользователями.
Но тебе лучше действительно в сторону редиса покопать.
Anatoly
Google
У тебя судя по всему поле категория unique = true в схеме модели;
нет только установил в схеме на name
Daniil
нет только установил в схеме на name
В любом случае существует уникальный индекс на поле category, удаляйте его вручную
SuleYman
эксплуатируется бот, часть функционала на mysql, часть переведена на монго.
Функционирует с двумя (код на golang), пока все переписываю на монго.
Сложность только в том, что иногда приходится дублировать какие-то данные в обе бд - не забывать про это. В остальном подводных пока не заметил.
Бот при этом активно юзается сторонними пользователями.
Но тебе лучше действительно в сторону редиса покопать.
Какую часть ты использовал монго, а какую часть SQL ?? Читал типо сложные запросы лучше кешировать, но кто то как и ты распределено использует две модели
 Zak
Zak
Вопрос: может кто то сталкивася, монга падает из-за того, что запрос скушивает всю память сервера. Может как то можно ограничить сколько памяти максимум может потреблять запрос? Либо что то ещё .
Out of memory: Kill process 29812 (mongod)
 Nick
Nick
Вопрос: может кто то сталкивася, монга падает из-за того, что запрос скушивает всю память сервера. Может как то можно ограничить сколько памяти максимум может потреблять запрос? Либо что то ещё .
Out of memory: Kill process 29812 (mongod)
советы в порядке полезности: добавьте индексов, ограничьте объем выборки, добавьте памяти
Zak
советы в порядке полезности: добавьте индексов, ограничьте объем выборки, добавьте памяти
я понял и больши ничего ? Уже изведонаая область и проторенная дорожка на поиск других вариантов?
Nick
других вариантов нет
 Anton
Anton
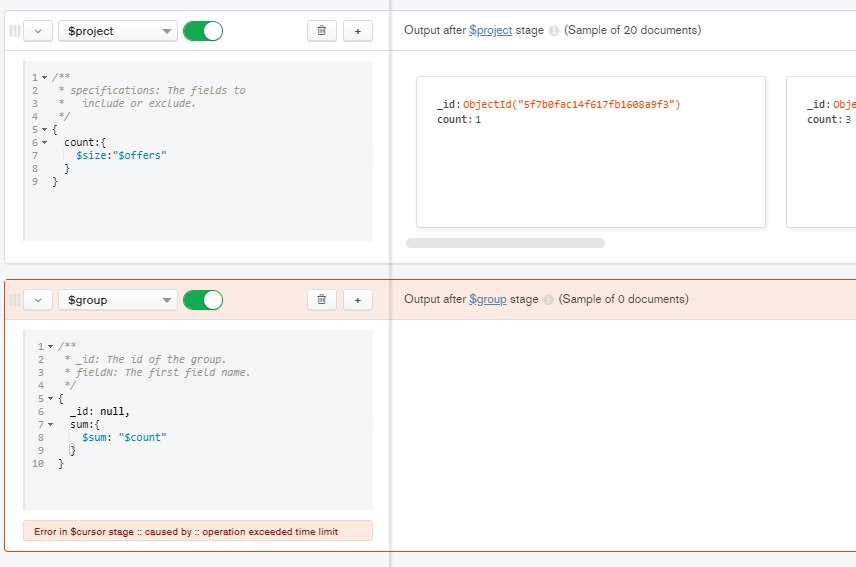
Ребят, а в пайплайне агрегации новый стэйдж зависит от проекции предыдущего стейджа?
Anton
 no
no
 Nick
Anton
Nick
Anton
там семплы на каждую берутся на каждый стейдж, а гроуп у вас обходит все данные, поэтому с ним вы натыкаетесь на таймаут
Спасибо, реально был таймаут. Не знал что 15.5 гб данных так долго могут обрабатываться
Anton
Целесообразно для таких случаев делать View. А View как часто обновляется? С каждым инсертом документа?
 orthodox
orthodox
Приветствую. Немного ламерский вопрос. У меня есть коллекция a, в каждом документе в коллекции есть поля x и y. Нужно получить сумму y в в каждом документе с одинаковым x, и так для каждого x
Viktar
Группируйте по х и считайте сумму у
Viktar
https://docs.mongodb.com/v3.6/reference/method/db.collection.group/
Anton
Целесообразно для таких случаев делать View. А View как часто обновляется? С каждым инсертом документа?
Сори View же вычисляется с каждым запросом заново
Nick
Сори View же вычисляется с каждым запросом заново
вроде бы да, тут не подскажу. В вашем случае похоже нужно будет хранить отдельно суммы и их обновлять периодически, если это допустимо. Еще можете сделать поле size для вашего массива и не вычислять его, и построить еще по нему индекс, тогда по нему будет производиться обход, а не по всей коллекции доков (но это на усмотрение планировщика монги на самом деле, может не сработать)
 Pavlo
Pavlo
Всем привет, подскажыте можно ли сделать такой фильтр на запрос в базу, чтобы вернуло все модели от создание которых не прошло еще 10минут, то есть модели созданные максимум 10минут назад, надо одним запросом
Daniil
Всем привет, подскажыте можно ли сделать такой фильтр на запрос в базу, чтобы вернуло все модели от создание которых не прошло еще 10минут, то есть модели созданные максимум 10минут назад, надо одним запросом
Можно, особенно если есть поле createdAt с жатой создания документа
Pavlo
Можно, особенно если есть поле createdAt с жатой создания документа
Как я понимаю можно взять какое время было 10 минут назад, и дата создания должна быть больше чем то время
Daniil
$gte
 Алексей К
Алексей К
Приветствую, господа! Насколько криминально в плане производительности будет хранить счетчик просмотров документа (новостей)
в той же коллекции что и сам документ. Учитывая что выборки из коллекции документов активно запрашиваются на фронт, и при частом прибавление счетчиков будет ли это сильно тормозить запросы выборки? Прибавление счетчика атомарным inc. Просто хотелось бы обойтись без отдельной коллекции и агрегирования, потребности в котором больше нигде в проекте нет.
Nick
Приветствую, господа! Насколько криминально в плане производительности будет хранить счетчик просмотров документа (новостей)
в той же коллекции что и сам документ. Учитывая что выборки из коллекции документов активно запрашиваются на фронт, и при частом прибавление счетчиков будет ли это сильно тормозить запросы выборки? Прибавление счетчика атомарным inc. Просто хотелось бы обойтись без отдельной коллекции и агрегирования, потребности в котором больше нигде в проекте нет.
а вам реально надо точно подсчитывать количество показов?