 Konstantin
Konstantin


папки дата нет
 GG
GG
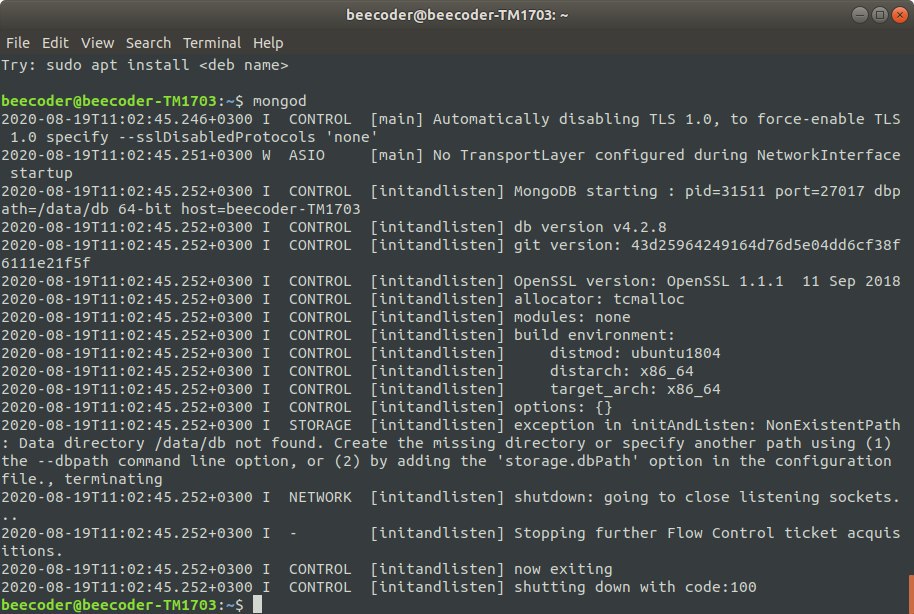
блин да, я ищу /data/db, а там нет, подумал может где-то в другом месте она еще может находится
 inqfen
inqfen
блин да, я ищу /data/db, а там нет, подумал может где-то в другом месте она еще может находится
Ну монга явно сказала какой каталог она хочет и при этом он отсутствует
inqfen
И даже сказала как переопределить, если база в другом каталоге
GG
она у меня до этого не запускалась, я нагулил решение пролемы, и вообщем ввел команду mongod --repair, могла ли эта команда стереть мои бд?
inqfen
И каталог удалить и в сервер наложить, ага. Нет, repair твои каталоги не должен удалить
 Андрей
Андрей
Only use mongod --repair if you have no other options. The operation removes and does not save any corrupt data during the repair process.
Пути с файловой системы не должно трогать.
GG
Only use mongod --repair if you have no other options. The operation removes and does not save any corrupt data during the repair process.
Пути с файловой системы не должно трогать.
Не очень понял, эта команда удаляет повреждённые файлы, бдшки мои входят в это множество "повреждённые файлы" ? Могла ли эта команда удалить мои бдшки?
Андрей
Конечно могла
Андрей
Перед рипэйром необходимо копировать весь БД путь в отдельное место
Андрей
А покорапчены ли были ваши БД откуда ж мы можем знать
 Вовчик
Вовчик
Всем привет, хотел спросить совета насчёт структуры базы данных используемой в проекте. Дело обстоит так: у нас таблица с категориями товаров, в этой таблице есть также и подкатегории, которые от родительских отличаются лишь полем { isMain: false }. Чтобы связать категорию и ее подкатегории, в основной категории есть поле subcategories, в котором хранятся ID дочерних категорий. Как по мне эта структура немного странновата. Потому что на фронте не всегда нам нужны все категории с их подкатегориями, но часто нужна единичная категория с ее дочерними подкатегориями, что приводит к нескольким запросам вместо одного: один на то чтобы достать категорию, и еще один чтобы достать все подкатегории, чьи ID хранятся в поле { subcategories } основной категории. Я предложил использовать virtual свойства в монгусе, и разделить эту таблицу на две отдельные с Категориями и Подкатегориями, и добавить Подкатегориям поле parentCategory с ID родительской категории, связав их. На что мне наш базист сказал что это не есть гуд дробить таблицы, поля у которых похожи. Проблема еще возникает на админке со стороны UI, так как немного тяжело создавать категории и в них же добавлять такие же категории, при этом не сделав UI громоздким, а наоборот более реюзабельным. Стоит ли прислушаться базиста и дальше страдать на фронте или сделать по-своему?
Спасибо за любые советы.
Вовчик
Нет, они такие же категории, просто имеют в поле isMain значение false
Вовчик
Если переделать под virtual то тогда да они будут попюлейтиться, но это нада разбить таблицу с категориями и подкатегориями на две отедльные
Вовчик
Что собственно я и предложил своему базисту, но он сказал что дробить таблицы не очень хорошо, а раз подкатегории по структуре такие же как категории, то давайте хранить всё вместе
Вовчик
Такой подход будет лучше или всё же хранить всё вместе, и чтобы достать подкатегории какой-нибудь категории задавать isMain: false и искать айди подкатегории в масиве subcategories родительской категории?
s
всем привет, у меня такой кейс: пишу приложение на ноде, использую nestjs. Раз в н-ное время получаю все документы из коллекции, делаю с некоторыми из них определенные манипуляции, сохраняю их в массив и передаю в другое место, где тоже есть бд. И нужно найти в бд те же документы, что пришли в массиве и отредактировать их в соответствии с массивом. как оптимальнее всего это сделать?
Dmitry
всем привет, у меня такой кейс: пишу приложение на ноде, использую nestjs. Раз в н-ное время получаю все документы из коллекции, делаю с некоторыми из них определенные манипуляции, сохраняю их в массив и передаю в другое место, где тоже есть бд. И нужно найти в бд те же документы, что пришли в массиве и отредактировать их в соответствии с массивом. как оптимальнее всего это сделать?
https://docs.mongodb.com/manual/core/bulk-write-operations/ ?
s
спасибо
Viktar
Добрый день, есть ли смысл с точки зрения перформанса вытаскивать в find определенные поля или весь документ?размер документа примерно 70кб
Viktar
Но их около 400 млн
Vadzim
https://github.com/mongodb/mongo-java-driver/blob/master/docs/reference/content/driver/tutorials/compression.md
проставил почти как описано в доке. Т.е. у меня настройки в конфиге, а не в самом коде. Не помогло. Вижу что сжатие не работает. Подскажите, есть ли у кого реальный опыт работы спринга с монго?
Daniil
Добрый день, есть ли смысл с точки зрения перформанса вытаскивать в find определенные поля или весь документ?размер документа примерно 70кб
Если нужны только определенные поля, то вытаскивайте только их, это ускоряет процесс
Viktar
s
https://docs.mongodb.com/manual/core/bulk-write-operations/ ?
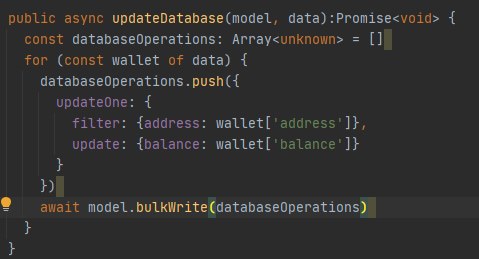
bulk принимает массив из операций, которые нужно сделать?
 s
s
то есть data всегда разная по объему
Daniil
После цикла взываете балк переливая массив операций
Daniil
Но в целом балк это чисто сетевая оптимизация поэтому если операций у вас там немного, то смысла в этом нет просто
s
ну там может быть от 1к до 30к операций за раз
s
понял
s
благодарю
 s
s
а
s
я не заметил что еще внутри цикла нахожусь
s
bulkWrite выполняется как один запрос?
s
а за счет чего выигрыш?
 Sardor
Sardor
Меньше нагрузки на сеть , со стороны клиента уходит всего лишь один запрос
Sardor
Bulk накапливает множество операции а после запроса выполняет на сервер БД
s
спасибо за ответ
Bogdan
Привет, что дешевле/лучше/быстрее, .insertMany() на 100 элементов или на 1000?
 Nick
Nick
Привет, что дешевле/лучше/быстрее, .insertMany() на 100 элементов или на 1000?
Надо тестировать в вашем окружении на ваших данных, не всегда увеличение рамера батча положительно влияет на производительность
Bogdan
 Сергей
Сергей
Всем привет.
Может кто-то подскажет как можно с минимальными издержками почистить по времени нагруженную базу mongo объемом 1.5 Тб?
Версия 4.0.19, база с ReplicaSet`ом.
Nick
Всем привет.
Может кто-то подскажет как можно с минимальными издержками почистить по времени нагруженную базу mongo объемом 1.5 Тб?
Версия 4.0.19, база с ReplicaSet`ом.
написать скриптец который порционально удаляет по диапазонам дат. Само собой подразумевается что у вас есть индекс на это поле
Nick
на 1.5Тб колскан на любом запросе положит базу, особенно если не sdd, а значит без индексов делать нечего.
Bogdan
Для упорядочивания записей по ключу, в данном случае по дате
 Александр
Александр
_id содержит в себе дату)
Nick
_id содержит в себе дату)
если у вас задача удалить конкретные данные, то дата из _id возможно не будет отвечать бизнес критерию и под него может попасть лишнее и тогда будет потеряд данных
Nick
дату из id можно брать когда данные за промежуток плюс-минус несколько минут не критично потерять. Как вариант для случаев простой очистки очень старых данных без доп критериев подойдет
Александр
Откуда "плюс несколько минут"?
Nick
_id может заполняться с клиента или с сервера или вразнобой если разные клиенты работают с БД и при разных языках/драйверах с не одинаковым поведением (это допускается в отношении _id). Соответвенно время на сервере/клиенте можете расходиться как минмум на секунды и скорее всего до минуты. Несколько минут - запущенные случаи, когда полностью отсутвует синхронизация времени между клиентом и сервером БД
Александр
Если всё тоже самое применить к полю с датой не будет тех же самых "плюс несколько минут"?
Nick
Привет. Есть вопрос:
Я использую мангус для разработки. У него есть схемы и модели.
Но я захотел установить gui для визуализации (робо3т или атлас, не важно). Проблема в том, что когда я создаю новую коллекцию через gui, я не могу получить доступ к этим данным в мангусе. Даже если я и пишу схему с моделью с тем же именем, все равно получаю пустой массив.
Как мне синхронизировать этот процесс? Я хочу руками заполнять БД из gui, а потом спокойно писать запросы через мангус
Сергей
написать скриптец который порционально удаляет по диапазонам дат. Само собой подразумевается что у вас есть индекс на это поле
При наличии индекса на подходящем поле удаление документов будет как-то аффектить параллельные запросы на чтение?
Nick
При наличии индекса на подходящем поле удаление документов будет как-то аффектить параллельные запросы на чтение?
Только нагрузкой на базе вцелом, т.к. Удаление дорогая операция и она аффектит диски
Nick
Если всё тоже самое применить к полю с датой не будет тех же самых "плюс несколько минут"?
Когда используется поле с датой, то мы можем быть уверены в том что оно заполняется в одном месте и скачков не будет. Плюс мы знаем как именно оно заполняется, что дает доп информацию для построения правильных предсказуемых запросов
Сергей
Только нагрузкой на базе вцелом, т.к. Удаление дорогая операция и она аффектит диски
Спасибо. Буду думать и экспериментировать :/
Alex
Посоветуйте хостинг для MongoDB? Думаю воспользоваться услугами от mail.ru cloud solutions. Может кто-то это тоже использует?
Vasily

 Oleg
Oleg
 nortimg
nortimg
 StaniFe
StaniFe
Всем привет. Тут кто ни будь работает с монгой на c#?
StaniFe
ну может все равно сходство есть.
Как можно ускорить выборку по n фильтрам и сортировке (в последствии применяется take и skip)
 Артем
Артем
через where
StaniFe
сейчас запрос на первых 20 (1 страница) элементах выполняется моментально, а запрос на 3000 странице выполняется под 12 секунд
Артем
плюс индекс не забудь навесить
StaniFe
да вроде уже на все навесил, но на последних страница ±10 секунд
Артем
skip take в монго не так работает как например в mssql
Артем
поэтому фильтруешь сразу через where