 Nick
Nick


Блин, точно забыл самое важное))
 Alex
Alex
добрый день господа; столкнулся с такой проблемой: Sort operation used more than the maximum 33554432 bytes of RAM; Add an index. Но загвоздка в том, что я не понимаю, по каким полям нужно делать индекс. В запросе find есть $in по одному полю и sort по двум другим полям. Пробовал создавать индекс по разным комбинациям этих трёх полей (одно, два, три), но ошибка лезет всё равно. Важен ли порядок, в котором указываются поля, когда создаёшь индекс?
 agic
agic
куда то не туда )
Alex
Запрос в студию
db.getCollection('facility').find({
"_id": {
"$in": [
"20088ee0-8d1e-4e70-825a-91ee74208915",
"797b729c-b274-41cf-8648-63956db4e546",
"62aaf1bb-dfb5-427e-87a0-b254d78a039e",
... ещё 19 тысяч строк здесь
]
}
}).sort({
"treeDepth": 1,
"supportedTranslatedDisplayNames.en": 1
})
Nick
И используйте explain для проверки использования индекса
Alex
создал индекс, он появился в winningPlan.inputStage в explain, но падение всё равно происходит
Alex
уменьшил количество строк до 10к, теперь не падает. Осталось теперь только придумать, что со всем этим делать, чтобы работало со всеми 19к строками
 ✙ Ukraine siegt an allen fronten! 🇺🇦
✙ Ukraine siegt an allen fronten! 🇺🇦
Привет всем. С монгой работаю не так давно и не так много, поэтому возник следующий вопрос:
В БД SQL сохранять файлы в blob значениях является крайне плохой практикой, по ряду причин, одна из которых - раздутые террабайтные таблицы, и все вытекающие из этого.
Как обстоят дела в Mongo в этом плане? Стоит в ней хранить байт-значения файлов или по-классике сохранять путь к файлу и класть все на сервер?
✙ Ukraine siegt an allen fronten! 🇺🇦
Кто подскажет - заранее благодарю
Alex
можно использовать MongoDB GridFS
 Александр
Александр
А какой вобще смысл хранить файлы в бд? Что бы их раздать придётся из БД читать, а так их nginx может сразу отдавать
Артур
привет всем, подскажите, в доке имеется два поля order: Number, memoryInt: Number
задача: есть диапазон товаров с order от 100 до 120, поле memoryInt у этих товаров обьем памяти, типа 64, 128, 25, каким образом вначале отфильтровать вначале по order а потом по memoryInt?
sort({order: 1, memoryInt: 1}) - так не пашет
Alex
уменьшил количество строк до 10к, теперь не падает. Осталось теперь только придумать, что со всем этим делать, чтобы работало со всеми 19к строками
короче кажется по-простому не получится это починить, придётся перелопачивать весь код у себя в проге, грузить по частям или хз...
Viktar
Для картинок есть свои системы хранения.
✙ Ukraine siegt an allen fronten! 🇺🇦
А какой вобще смысл хранить файлы в бд? Что бы их раздать придётся из БД читать, а так их nginx может сразу отдавать
Если честно, транзакционность во время input-а настраивать гемор просто))
Daniil
Картинки в s3 должны лежать, никак не в бд
Ну аксиомой это не является абсолютно. Если нагрузки маловато, то смысла в S3 нет никакого (тем более что помимо S3 есть ещё n хранилищ)
 Denis
Denis
Ну аксиомой это не является абсолютно. Если нагрузки маловато, то смысла в S3 нет никакого (тем более что помимо S3 есть ещё n хранилищ)
Я имею в виду любое s3 совместимое
«Не является аксиомой» - а что будем base64 строчки в монге хранить?
Daniil
Я имею в виду любое s3 совместимое
«Не является аксиомой» - а что будем base64 строчки в монге хранить?
Вы не учитываете контекст задачи конкретного человека вообще. А потом кластер кубернетеса раскатывают в дц по всей планете чтобы 5 запросов в минуту обрабатывать. Плюс ещё и сразу вендорлок предлагаете
Denis
Вы не учитываете контекст задачи конкретного человека вообще. А потом кластер кубернетеса раскатывают в дц по всей планете чтобы 5 запросов в минуту обрабатывать. Плюс ещё и сразу вендорлок предлагаете
Minio и аналоги не слышал о таком? В третий раз - s3 совместимое
Denis
Вы не учитываете контекст задачи конкретного человека вообще. А потом кластер кубернетеса раскатывают в дц по всей планете чтобы 5 запросов в минуту обрабатывать. Плюс ещё и сразу вендорлок предлагаете
Еще раз, адекватная альтернатива объектному хранилищу какая?
Daniil
Minio и аналоги не слышал о таком? В третий раз - s3 совместимое
Слышал и использовал. Но вы по прежнему продвигаете уже S3-совместимые хранилища как аксиому, не вникая в суть конкретной задачи
Daniil
Еще раз, адекватная альтернатива объектному хранилищу какая?
Без контекста не имеет смысла обсуждать вообще
 yopp
yopp
Я имею в виду любое s3 совместимое
«Не является аксиомой» - а что будем base64 строчки в монге хранить?
Зачем хранить base64 если есть binary тип и gridfs спецификация как хранить в монге файлы так, чтоб было легко и приятно.
А шардируемое, реплицируемое, HA/FT хранилище, по которому не надо в принципе получать PhD по деплою ещё поискать надо.
А навернуть поверх монги нормальный http кэш можно обычным nginx, причём с lua драйвером можно ещё и реалтайм инвалидацию на ченджстримах сделать
 Roman
Roman
ребят как сравнить два массива через монгу
Roman
пока что я делаю updateOne
Roman
и перезаписываю старый массив на новый но это плохо для моей реализации
Roman
очень часто объекты внутри похожи, по этому я озадачился данным вопросом
Denis
а есть какой то индекс на наличие поля? например я хочу повесить индекс на поле url, которое ссылка, но мне не интересен текст этой ссылки, я не хочу забивать оперативу текстами этих ссылок, я по тексту никогда не буду искать, я хочу просто чтобы $exists быстро работал для выборок где url есть или нету
Denis
ребят как сравнить два массива через монгу
find({
yourArr: [{ field1: '1' }, { field2: '2' }]
})
на точное соответствие переданного массива массиву из монги
если надо проверить на вхождение всех переданных элементов (то есть и другим разрешено быть)
find({
yourArr: {
$all: [{ field1: '1' }, { field2: '2' }]
}
})
также если части полей разрешено быть другими, можно заюзать dot notation - 'yourArr.field1'
 Roman
Roman
спасибо
 Archakov
Archakov
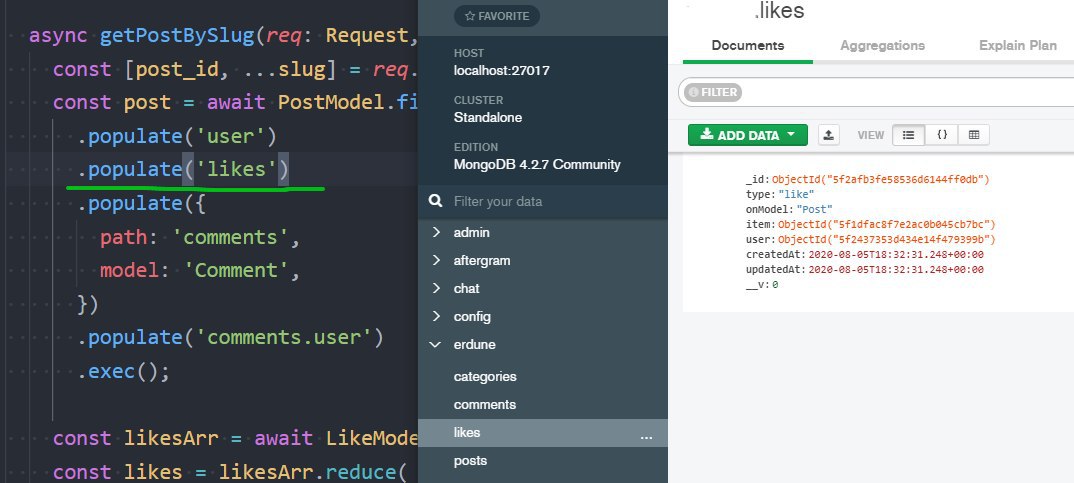
Добрый день! Как правильно можно реализовать в mongoose систему лайков/дизлайков? Есть комменты и посты и у них есть лайки
Archakov
Правильно ли будет, если для LikeModel я задам { post: ObjectId, comment: ObjectId }, а потом уже уже с помощью populate вытаскивать лайки, типа
PostMode.populate('likes')
при этом в PostModel добавить
likes: [
{
type: Schema.Types.ObjectId,
ref: 'Like',
},
],
Archakov
так и я для комментов
 no
no
Я делал отдельную модель для лайков
no
Были у меня лайки на постах и комментах
no
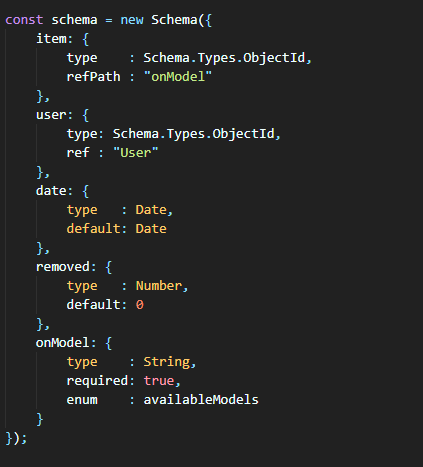 Archakov
Archakov
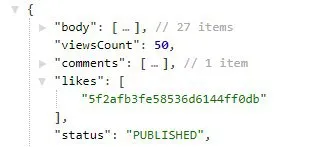
то есть, в item ты контролируешь для какой модели лайк ставится?
Archakov
availableModels хранит массив или что?
no
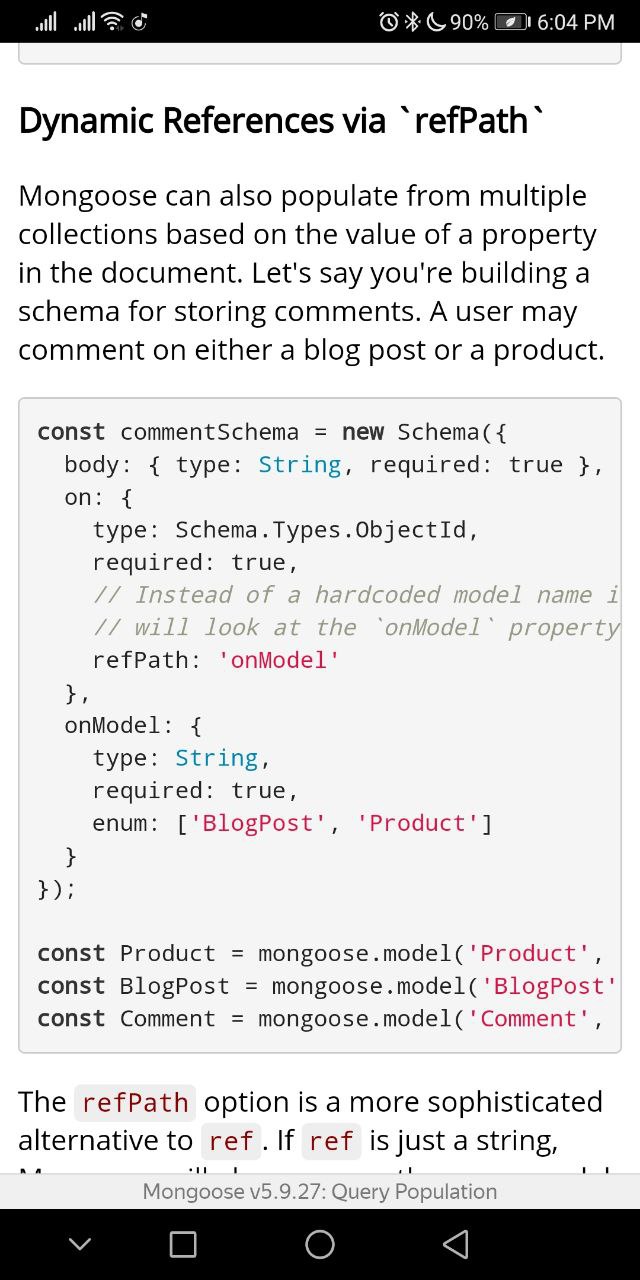 no
no
https://mongoosejs.com/docs/populate.html#dynamic-ref
Archakov
о! спасибо
 Ростислав ✚
Ростислав ✚
 Ростислав ✚
Ростислав ✚
 Denis
Denis
 Serhii
Serhii
Да
Ростислав ✚
Я так понял они там обязательно нужны для монги, и должны быть полюбому?
Serhii
Да. Но перезаписывать нужно осмысленно
Ростислав ✚
Да. Но перезаписывать нужно осмысленно
Да пусть будут тогда, я просто подумал что сам их спровоцировал на это) Спасибо
Archakov
 Daniil
Archakov
Daniil
Archakov
 Daniil
Archakov
Daniil
Archakov
походу разобрался, спасибо
Archakov
 s
s
привет
s
 s
s
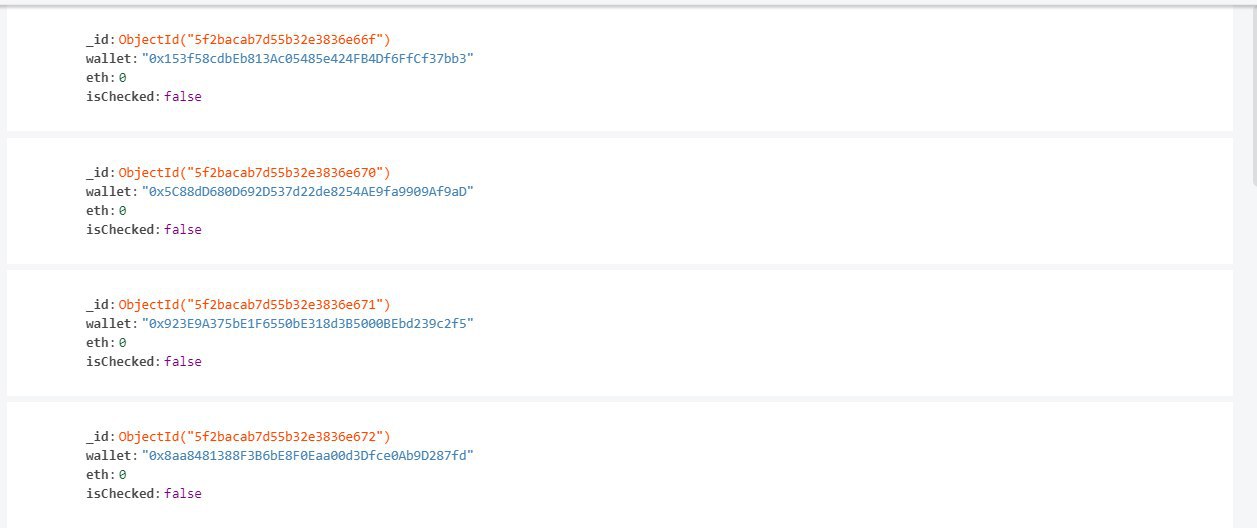 s
s
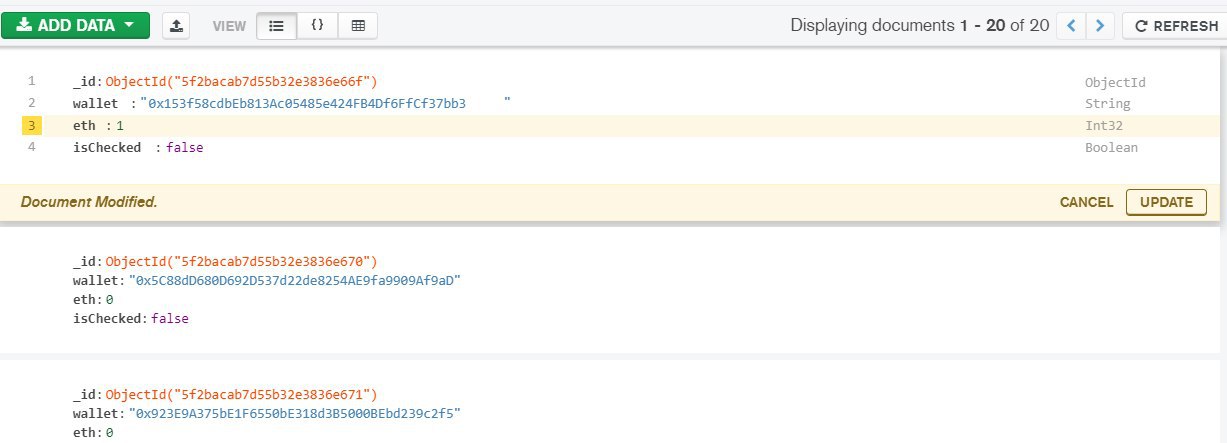 s
s
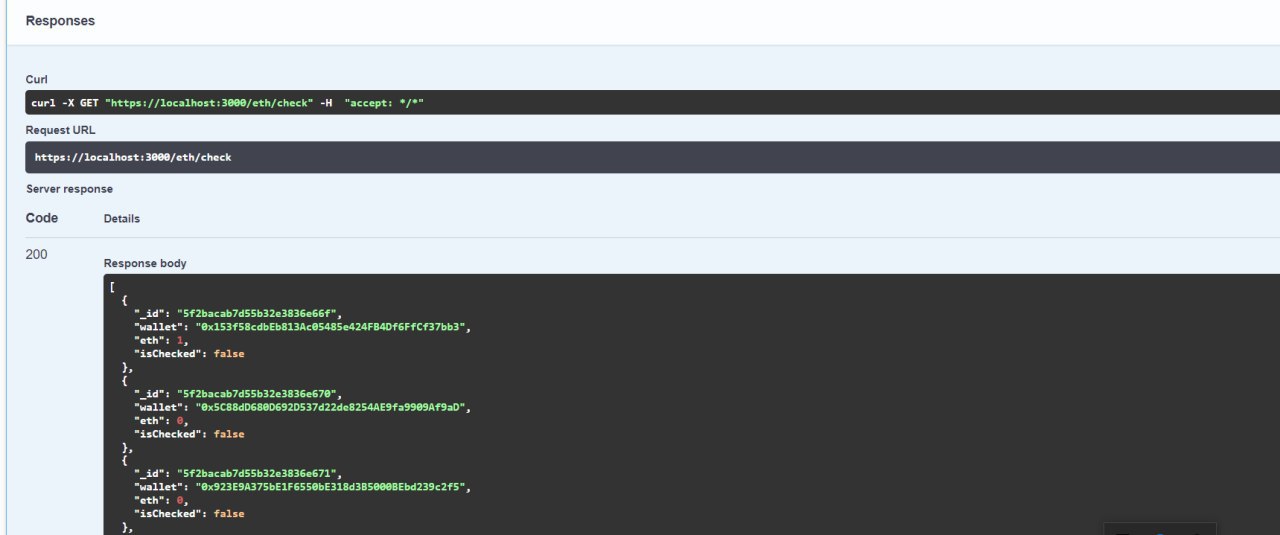 s
s
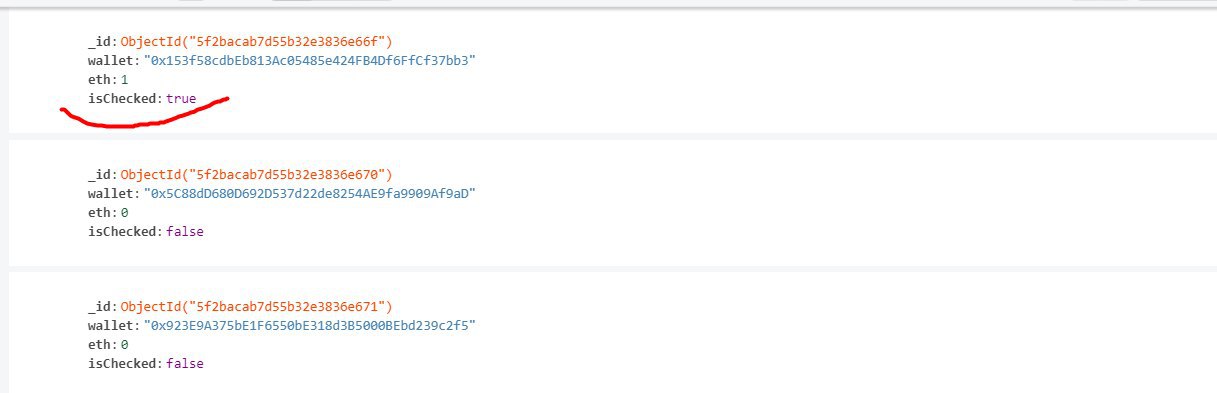 s
s
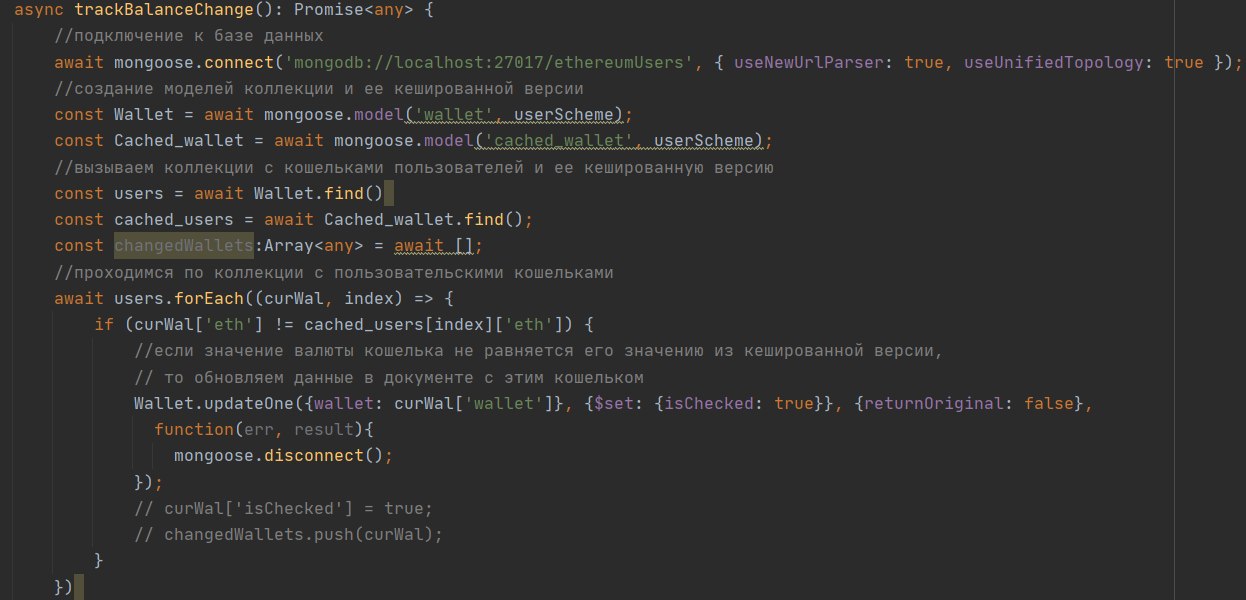
и что бы увидеть его в ноде, нужно вызывать метод еще раз
Shamil | CS
s
ты имеешь ввиду вынести построение схем и коннект к бд в приватные поля?
а в асинхронном создании массива нет смысла, это нужно поправить
Shamil | CS
Более того, каждый раз вызывать на любой коллекции .find() очень снижает performance в лонг-терме, поэтому нужно строить запросы внутри MongoDB (через интерфейс mongoose)
s
я монгусом и пользуюсь
s
но вообще этот метод в продакшене будет отрабатывать раз в 10 минут
s
или в большее время
s
сейчас-то я его в ручную вызываю
Shamil | CS
но вообще этот метод в продакшене будет отрабатывать раз в 10 минут
Нет разницы, представь что в одной из коллекций больше 1млн+ записей
Просто неэффективно