 Ilshat
Ilshat


небольшой вопрос: будет ли балансировщик пытаться spill jumbo chunks? Или раз уж он помеченный, то и делить его не стоит?
Roman
Есть такой запрос( в упрощенном виде) на sql:
SELECT t1.* FROM t1
JOIN t2 ON (t2.id=t1.t2_id)
WHERE t1.name=$1 AND t2.id =$2
Где $1 и $2 - переменные
Каким образом его лучше переписать на монго? Вижу два решения, но не знаю, какое более правильное для монги: 1) Написать аггрегацию с lookup и match ; 2) Написать 2 раздельных запроса, первый для проверки наличия записи в t2, второй для получения данных из t1.
Вроде как второй более оптимальный, потому что нет лишнего поиска данных, но там 2 запроса, а это меня смущает.
Заранее спасибо за ответы
 Александр
Александр
Если t2 для каждого t1 не очень большое, то лучше держать в t1
Roman
t2 и t1 большие и это разные коллекции, которые нельзя объединить
Александр
коллекции могут быть большими, а вот
t2.id=t1.t2_id может быть не очень большим
Roman
Может быть несколько тысяч записей в - это считается большим?
Roman
И в общем случае, есть ли какие-то правила или требования, когда лучше использовать несколько запросов вместо аггрегации?
 Nick
Nick
Есть такой запрос( в упрощенном виде) на sql:
SELECT t1.* FROM t1
JOIN t2 ON (t2.id=t1.t2_id)
WHERE t1.name=$1 AND t2.id =$2
Где $1 и $2 - переменные
Каким образом его лучше переписать на монго? Вижу два решения, но не знаю, какое более правильное для монги: 1) Написать аггрегацию с lookup и match ; 2) Написать 2 раздельных запроса, первый для проверки наличия записи в t2, второй для получения данных из t1.
Вроде как второй более оптимальный, потому что нет лишнего поиска данных, но там 2 запроса, а это меня смущает.
Заранее спасибо за ответы
матч на основную каллелкцию, потом в лукапе указат ьвторое услвоие
Nick
И в общем случае, есть ли какие-то правила или требования, когда лучше использовать несколько запросов вместо аггрегации?
когда вы начали нормально проводить нагрузочное или вышли в прод и по метрикам нашли узкое место и оно вам аффектит бизнес
 no
no
Привет всем!
no
У меня есть коллекция posts:
{
definition: { type: mongoose.Types.ObjectId, ref: 'Definition' }
}
Также есть коллекция definitions:
{
title: String,
likes: { type: Number, index: true }
}
Вопрос: как вытащить из коллекции posts те документы, definition.likes которых > 10, к примеру? Используя aggregate
Anonymous
Вечер добрый
Anonymous
Парни, подскажите как связать две таблицы по заданному ключу
Anonymous
Или там только связь можно осуществить по _id ??
 Viktor
Viktor
Приветствую, подскажите плиз, как БД перенести на другой сервер, с данными и индексами?
 NCR
NCR
тулзы mongodump и mongorestore
Viktor
Thanks
NCR
Тогда написать скриптёныша на коленке на экспорт и импорт
kk
эти тулзы выгружают только коллекции, без индексов
в смысле? вы путаете с mongoimport mongoexport. mongodump mongorestore прекрасно дампит/ресторит всю мету, включая индексы
kk
блин, в доке написано что только документы дампит, но я тысячу раз так делал, с указанием коллекции через --collection и информация об индексах сохранялась и при ресторе всё восстанавливалось
kk
а, кажись я понял - оно сохраняет _инфу_ об индексах и при ресторе перестраивает их, если надо прям перенести готовенькое, то да, это не подойдёт
 yopp
yopp
зачем переносить готовые индексы?
 Vladimir
Vladimir
учитывая логическость бэкапа, то незачем, они все равно работать в новом месте не будут
Ilya
всем привет
есть такая коллекция:
[{
"_id": {
"$oid": "5f05cb677cb8e722ec2e8667"
},
"project": {
"$oid": "5f05c45e1f878c2b6475304c"
},
"times": [
{
"_id": {
"$oid": "5f05cd8909372a306415d9ec"
},
"user": {
"$oid": "5f05c3267d435521802b0d1b"
},
"text": "",
"time": 325,
"updatedAt": {
"$date": "2020-07-08T13:43:37.100Z"
},
"createdAt": {
"$date": "2020-07-08T13:43:37.100Z"
}
},
{
"_id": {
"$oid": "5f05dc596dc16731a84935f3"
},
"user": {
"$oid": "5f05c3267d435521802b0d1b"
},
"text": "коммент",
"time": 260,
"updatedAt": {
"$date": "2020-07-08T14:46:49.749Z"
},
"createdAt": {
"$date": "2020-07-08T14:46:49.749Z"
}
}
],
"createdAt": {
"$date": "2020-07-08T13:34:31.674Z"
},
"updatedAt": {
"$date": "2020-07-08T14:46:49.749Z"
},
"__v": 0
}]
мне нужно взять только те элементы из times, которые пренадлежат определенному проекту (самый верхний уровень) и юзеру (на уровне times)
я сделал aggregate:
[
{
$match: {
project: mongoose.Types.ObjectId(project),
updatedAt: {$gte: new Date(fromDate), $lte: new Date(toDate)},
}
},
]
но не понимаю что делать дальше, как отфильтровать записи внутри times и как эти отфильтрованные times вернуть в виде массива
Ilya
подскажите в какую сторону смотреть
 Nazar
Ilya
Nazar
Ilya
Спасибо
yopp
$unwind и $group для того чтоб отфильтровать элементы массива — антипаттерн
 Ростислав ✚
Ростислав ✚
Здравствуйте. Есть вопрос. Хорошим ли решением будет использовать данную БД для интернет магазина? Просто по тому что я нагуглил сложилось мнение что будут проблемы с фильтрами товаров, так как много массивных связей многие ко многим, или это решается populate?
Daniil
Здравствуйте. Есть вопрос. Хорошим ли решением будет использовать данную БД для интернет магазина? Просто по тому что я нагуглил сложилось мнение что будут проблемы с фильтрами товаров, так как много массивных связей многие ко многим, или это решается populate?
populate это фишка из mongoose и по сути своей просто второй запрос
Ростислав ✚
populate это фишка из mongoose и по сути своей просто второй запрос
Ясно, а есть тогда какие-то еще варианты?
Daniil
Ясно, а есть тогда какие-то еще варианты?
Правильно проектируя схему, используя преимущества отсутствия схемы и тд
Daniil
Ну и $lookup есть
Ростислав ✚
Ладно, спасибо, буду пробовать и смотреть на производительность
𝐃𝐢𝐦𝐚
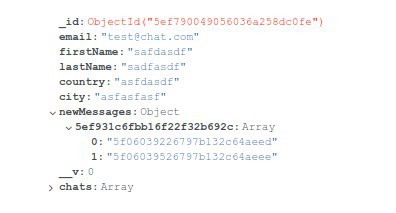
Привет , кто может подсказать как обновить запись чтобы была такая структура newMessages
𝐃𝐢𝐦𝐚
 𝐃𝐢𝐦𝐚
𝐃𝐢𝐦𝐚
newMessages:
chatId: [messagesId,messagesId]
 Anton Zol
Anton Zol
 VovaDos
VovaDos
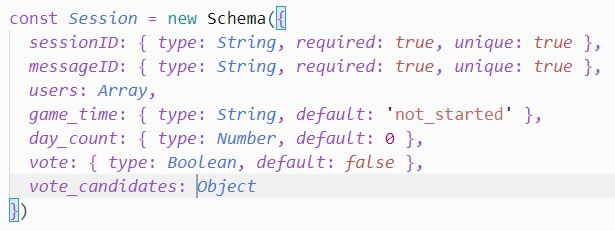
Всем привет! Почему, делая в схеме поле с типом Object оно не появляется в БД при создании?
VovaDos
 VovaDos
VovaDos
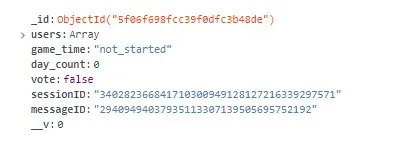
При создании:
VovaDos
 Nick
VovaDos
Nick
VovaDos
вы его не заполняете
Дело в том, что заполняю в процессе работы. Но для этого мне надо получить vote_candidates, а он - undefined
Nick
ну потому что не заполнили, а дефолтного значения нет
Nick
если бы заполнили, то оно бы было
VovaDos
Нормальная практика ставить default: {}?
Nick
почему бы и нет, если это позволяет монгус.
Но не нормально то, что вы не заполняете его, если оно обязательное
Nick
и если вы расчитываете что поле будет заполнено по какойто структуре, то в случае дефолтов вы также получите ошибку
yopp
Нормальная практика ставить default: {}?
нетипизированные объекты в целом не очень идея, особенно когда название аттрибута подразумевает что у вас там какая-то явно заданная структура
Александр
Anton Zol
Пробовали под рутом:
echo -1000 > /proc/<PID_Mongo>/oom_score_adj
и может попробовать добавить swap?
в первом случае произошел ребут) второй случай пробую в данный момент, нарастил ram до 40 и своп примерно аналогичного размера
Oleg
всем привет. кто то юзает mgob для бэкапа в кубике ?
Andrew
Подскажите пожалуйста способы отслеживания запросов в монгу? Интересует именно кто запросы делает
Nick
Обычный remove с запросом, как если бы вы просто искали те же доки
Nick
Подскажите пожалуйста способы отслеживания запросов в монгу? Интересует именно кто запросы делает
Вам нужен аудит, в бесплатной версии может его и не быть https://docs.mongodb.com/manual/core/auditing/
 Pavlo
Pavlo
Подскажите, а как искать по связанным документам? Или это нереально?
Pavlo
У меня есть модель Билет, и я хочу найти билеты по имени пользователя, который указан как:
user: {
type: Schema.Types.ObjectId,
ref: "User"
},
Pavlo
Использую библиотеку mongoose
Pavlo
 Pavlo
Pavlo
Привет всем, нужна помощь.
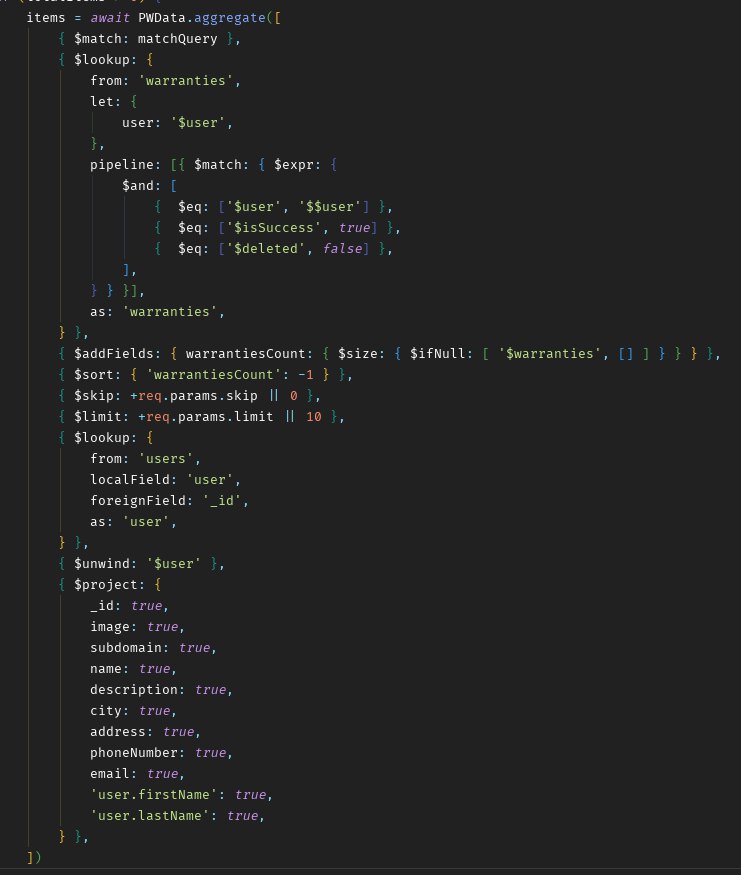
Есть две колекции вебсайты и гарантии, между собой никак не конектяться, единственное что у них общего это поле user так как и те и те конектяться к колекции пользователей (где пользователь это создатель вебсайта или гарантии).
Пришла задача от клиента вернуть список вебсайтов таким образом чтоб их порядок зависел от количества успешных гарантий пользователя. Пробывал сделать таким образом(на скрине выше), но запрос длится около 30 секунд (вебсайтов около 500, гарантий более 20000)
Mongoose.
Возможно есть более быстрый способ.
 Chechen
Chechen
Есть два документа: vacancy и candidate.
в вакансии хранится список кандидатов, состоящий из ссылок на candidate.
в кандидате хранится список заявок, состоящий из ссылок на vacancy.
когда меняется candidate.applications, то соответственно нужно менять и vacancy.candidates. как это легче всего реализовать?
 stay
stay
Есть два документа: vacancy и candidate.
в вакансии хранится список кандидатов, состоящий из ссылок на candidate.
в кандидате хранится список заявок, состоящий из ссылок на vacancy.
когда меняется candidate.applications, то соответственно нужно менять и vacancy.candidates. как это легче всего реализовать?
Проще не хранить у кандидата .applications
stay
Я конечно не эксперт, но это, вроде как, антипаттерн
stay
Я бы хранил только список кандидатов у вакансий, а если вдруг надо достать список вакансий, на которые претендует кандидат – использовать $lookup
Chechen
понял принял, спасибо
 Matvey
Matvey
Привет всем, подскажите пожалуйста, могу ли я добавить запись в коллекцию из mongo-init.js который прокидываю в контейнер с монгой?
Пользователя в этом файле получается создать, а вот что мне интересно, так это после добавления юзера, добаивть в одну коллекцию документ
После конструкции указаной здесь https://stackoverflow.com/a/54064268
Выполняю вызов следующих комманд
db = db.getSiblingDB('dbname’)
db.collection_name.insert({email: "mail@gmail.com", password: "12345678", name: "Matvey"})
Но заветная запись не появляется
 Андрей
Андрей
Всем привет, столкнулся с проблемой такой:
Делаю запрос на подсчет строк в таблице юзеров, и походу очень много там строк и не отвечает тупо((( делал так:
User.where({}).countDocuments(function (err, count) { console.log(count)}
Как-то еще это можно оптимизировать?
 Denis
Denis
Всем привет, столкнулся с проблемой такой:
Делаю запрос на подсчет строк в таблице юзеров, и походу очень много там строк и не отвечает тупо((( делал так:
User.where({}).countDocuments(function (err, count) { console.log(count)}
Как-то еще это можно оптимизировать?
Where не нужен, countDocuments первым аргументом query принимает
И чтобы query в индекс попадало, тогда быстро будет. Ну если пустой то естественно индексы не надо
no
Daniil
Быстрее estimatedDocumentsCount
Daniil
Но он не совсем точный