 yopp
yopp


Если read into постоянно растёт, то working set скорее всего не умещается в память
yopp
Если ещё и растёт written from то значит insert/update операции выстесняют
yopp
Если растёт только pages requested from cache значит только данные не помещаются
 Гена
Гена
Ну тем не менее, боттлнек тут где может быть, как по мне 4ЦПУ маловато
Гена
как по мне
Гена
48гб для монги вполне себе
yopp
В первую очередь нужно найти откуда ноги
yopp
LA вероятнее всего это или следствие компрессии или следствие cpu intensive computations
yopp
Или какой-то побочный эффект
yopp
Плюс у вас монга в гипервизоре, с зарезанным количеством ядер и это неудачная идея
Гена
Хм...
Спасибо)
yopp
Но вы продолжаете искать проблемы без метрик
yopp
Это тупиковый путь
Гена
да я понимаю, но с этим затык
Гена
у нас заббикс
yopp
Бессмысленно пытаться что-то делать не имея объективной картины происходящего
Гена
а там темплейты дерьмо
Гена
так что у нас метрики из *** и палок)
yopp
Практически гарантированно вы примчите неверное решение без достаточного количества информации
yopp
Есть PPM
yopp
Задеплоить PPM будет всяко дешевле чем налить железа, которое может и не помочь особо
Гена
Спасибо.
Подумаем
Гена
@dd_bb Еще вопрос
Если у нас 48гб ОЗУ и монга использует только +- половину для кэша, можно ли "заставить" монгу использовать бльще своего внутреннего лимита?
yopp
Это не имеет смысла и скорее усугубит проблему
yopp
Втора вполовина памяти используется под дисковый кеш
Гена
Получается, если у нас монга упирается в РАМ (кэш) она начинает иджектить данные на диск за счет ЦПУ
И чтоб нам поднять кэш нам надо поднять РАМ, верно?
yopp
Компрессия в WT работает таким образом, что в кеше хранятся несжатые страницы и сжимаются они только при сбросе на диск. Выделив больше памяти для кеша, количество сжатых страниц в дисковом кеше уменьшится и в итоге в памяти будет меньше данных
yopp
Получается, если у нас монга упирается в РАМ (кэш) она начинает иджектить данные на диск за счет ЦПУ
И чтоб нам поднять кэш нам надо поднять РАМ, верно?
Не могу ничего сказать, у меня нет никаких объективных данных чтоб даже гипотезы строить, не говоря уже о решениях
Гена
понял) спасибо
 Dmitriy
Dmitriy
ребят, а подскажите функцию (если есть) для замены в строке чтобы в агрегации работала?
Андрей
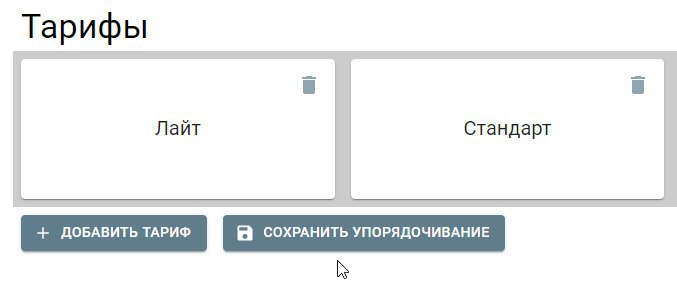
как то можно при создании документа выставлять число на единицу больше максимального числа из существующих документов? Например , есть документы
{id: 2, order: 10} {id: 1, order: 14} {id: 3, order: 53} и когда я вставлю новый документ автоматически вставилось число {id: 4, order: 54}
 Андрей
Андрей
надо же автоматически выставить order поле
Dmitriy
делайте на уровне приложения в 2 запроса, первый файнд с сортировкой по ордер и выборкой максимального и второй вставка с инкрементацией
Dmitriy
не думаю, что тарифы у вас меняются особенно часто, чтобы 2 запроса негативно сказались на перформансе
yopp
Если в нужен порядок для большого числа документов, то positional math внутри транзакции и механизм разрешения конфликтов
yopp
Большое число это тысячи где-то
Андрей
Спасибо, тарифов всего до 5-7 будет
Dmitriy
ребят, а подскажите функцию (если есть) для замены в строке чтобы в агрегации работала?
разобрался, если кому-то интересно, то можно сделать через $split + $concat
Гена
коллеги
пытаюсь запустить транзакцию с шелла не получается
session = db.getMongo().startSession()
2020-03-26T15:12:05.194+0100 E QUERY [thread1] TypeError: db.getMongo(...).startSession is not a function :
@(shell):1:11
в чем может быть проблема
Гена
источник - https://habr.com/ru/post/417131/
yopp
коллеги
пытаюсь запустить транзакцию с шелла не получается
session = db.getMongo().startSession()
2020-03-26T15:12:05.194+0100 E QUERY [thread1] TypeError: db.getMongo(...).startSession is not a function :
@(shell):1:11
в чем может быть проблема
Это не официальная документация, для нестабильной версии. официальная вот: https://docs.mongodb.com/manual/reference/method/Session.startTransaction/
Anton
Привет.
Немного тривиальный вопрос, возможно, уже обсуждавшийся.
Есть коллекция, в которой есть два поля с одинаковым типом( время ). Назовем их f1 и f2
Хочется получать данные из коллекции отсортированными по такому условию, выражаясь на языке sql: coalesce(f1,f2).
Не могу понять, как это правильно сделать в MongoDB
Нашел оператор $ifNull для пайплайнов, но не смог подружить его с индексами, работает очень медленно. Создавал индексы по кажому из полей.
Пока вижу только вариант явно создать дополнительное поле f3 = $ifNull(f1,f2) и по нему сделать дополнительный индекс.
Но все же не хотелось бы заводить дополнительных полей.
Подскажите, собственно, какое традиционное решение такой задачи?
Спасибо.
 Alexandr
Alexandr
Доброго, подскажите пожалуйста, если ли возможность организовать выборку из коллекции следующим образом:
Допустим есть массив данных ['a', 'b', 'c']
в базе есть записи
{value: 'a'}
{value: 'b'}
Я хочу, чтобы выборка из базы мне вернула данные, которых в базе нет, то есть результатом выборки должно быть ['c']
 RapidCodeLab
RapidCodeLab
Доброго, подскажите пожалуйста, если ли возможность организовать выборку из коллекции следующим образом:
Допустим есть массив данных ['a', 'b', 'c']
в базе есть записи
{value: 'a'}
{value: 'b'}
Я хочу, чтобы выборка из базы мне вернула данные, которых в базе нет, то есть результатом выборки должно быть ['c']
Постановка вопроса конечно адовая "вернула данные, которых в базе нет" ))) но подозреваю что нужно $exists
Alexandr
Постановка вопроса конечно адовая "вернула данные, которых в базе нет" ))) но подозреваю что нужно $exists
ну дык, как есть так и описал)
Alexandr
как можно вернуть данные которых нет?
$exists проверяет ключи, а мне нужны значения, а как можно.. вот хз как, этих данных могут быть десятки и сотни тысяч, не хотелось бы проверять каждую запись на наличие, а получить сразу список несуществующих
RapidCodeLab
по вашему вопросу в базе два документа только?
{value: 'a'}
{value: 'b'}
а какой документ вы хотите получить?
Dmitriy
$exists проверяет ключи, а мне нужны значения, а как можно.. вот хз как, этих данных могут быть десятки и сотни тысяч, не хотелось бы проверять каждую запись на наличие, а получить сразу список несуществующих
А зачем вам по одной проверять. Получите все из базы и обойдите через for элементы в приложение
RapidCodeLab
список несуществующих документов? 😂
Dmitriy
Это вам будет дешевле чем городить адову логику на стороне субд
Alexandr
А зачем вам по одной проверять. Получите все из базы и обойдите через for элементы в приложение
весьма затратно, и данных много прилетает и обход забивает основной поток на долго, уже пробовал
Dmitriy
Хотя подозреваю, что вам даже это не нужно может быть. Вы попробуйте описать конкретную задачу, глядишь и придумается хорошее решение
RapidCodeLab
distinct значений в базе берите и узнаете каких значений там нет(ключ под индекс естественно, а то долго будет)
Alexandr
Хотя подозреваю, что вам даже это не нужно может быть. Вы попробуйте описать конкретную задачу, глядишь и придумается хорошее решение
хорошо, задача: прилетает на проверку 20к значений (неважно от куда), в базе уже есть 19995 значений из тех, которые прилетели на проверку (всего в базе 300к значений), нет только 5-ти значений (5-ти это условно, может быть и 10 и 20 и 1000), нужно определить каких значений нет и записать их в базу
Dmitriy
хорошо, задача: прилетает на проверку 20к значений (неважно от куда), в базе уже есть 19995 значений из тех, которые прилетели на проверку (всего в базе 300к значений), нет только 5-ти значений (5-ти это условно, может быть и 10 и 20 и 1000), нужно определить каких значений нет и записать их в базу
Что нужно сделать дальше с теми значениями, которые вы определили как уникальные?
Alexandr
Dmitriy
записать их в базу
Зачем вы тогда проверяете уникальность на клиенте, сделайте уникальный индекс по полю в базе
Dmitriy
И сразу вставляйте записи
Alexandr
Зачем вы тогда проверяете уникальность на клиенте, сделайте уникальный индекс по полю в базе
и что тогда предлагаете через insertMany все 20к вставлять?
Alexandr
пытаться вставить вернее
Dmitriy
А почему нет, с ордеред фалсе
Dmitriy
Я потому и стал уточнять)
Андрей
 Alexandr
Alexandr
я думал по контексту это и так понятно
Dmitriy
С точки зрения самого запроса к монге
Андрей
ааа
Alexandr
А почему нет, с ордеред фалсе
Тогда добавлю условие, мне нужно сделать эту запись в 2 коллекции, через транзакцию, и такой вариант уже не катит
Dmitriy
Тогда добавлю условие, мне нужно сделать эту запись в 2 коллекции, через транзакцию, и такой вариант уже не катит
Ну мы можем раскрутить вашу задачу дальше и я думаю и эту проблему можно решить будет. Но я думаю разбор вашей задачи до правильного архитектурного решения - это не тема для данного чата
Alexandr
может быть так и сделаю, если ничего другого не придумаю, сравнение массивов тогда наверно в отдельный поток вынесу...
yopp
хорошо, задача: прилетает на проверку 20к значений (неважно от куда), в базе уже есть 19995 значений из тех, которые прилетели на проверку (всего в базе 300к значений), нет только 5-ти значений (5-ти это условно, может быть и 10 и 20 и 1000), нужно определить каких значений нет и записать их в базу
Если это задача синхронизации, то самый эффективный способ не проверять существование и заливать все пришедшие документы. К ним добавить какой-то идентификатор «версии синхронизации» и хранить его где-то отдельно, используя его для выборок.
Все остальные решения алгоритмически будут сложнее
Аркадий
Подскажите, пожалуйста, как реализовать систему тегов для блога. Это обязательно в две коллекции делается Статьи и Теги или можно как-то строкой хранить в статье?
 Артем
Артем