 Гена
Гена


чет нагуглить не могу
 yopp
yopp
Коллеги
подскажите, о чем говорит эта запись
[WT OplogTruncaterThread: local.oplog.rs] WiredTiger record store oplog truncation finished in
Технический вывод, информация о времени очистки выпавших из границ capped коллекции записей. А в чем проблема?
Гена
Просто встречаю в логах иногда) Просто не нашел нигде пояснения
спасибо
 Konstantin
Konstantin
всем привет
Konstantin
сможет ли кто-нибудь помочь мне поставить аутентификацию на базу?
Гена
@dd_bb
 Nikita
Nikita
гайз, а кто нибудь знает какие нибудь фокусы чтобы bulk updates ускорить на блинах?
щас получается размер батча линейно влияет на лейтенси ну и в целом лейтенси хочется чуть поменьше
балк на 150 записей 50мс, на 2000 - 800мс
у кого нить был опыт?
Daniil
bulk-операции это просто упаковка n-го количества операций в один «пакет», в базе они применяются последовательно, как обычные update’ы
Самое просто, что можно порекомендовать - перезанять на NVMe SSD. Не так дорого стоит
Nikita
Ну про железо понятно,это дальше будеть
Nikita
То есть даже перестройки инднкса идут не батчем?
Nikita
еще такой вопрос, что с lmt индексами в монге? в wiredtiger есть, но че то я так понял в монге все еще B-tree :/
Nikita
для _id даже включить нельзя вроде
yopp
гайз, а кто нибудь знает какие нибудь фокусы чтобы bulk updates ускорить на блинах?
щас получается размер батча линейно влияет на лейтенси ну и в целом лейтенси хочется чуть поменьше
балк на 150 записей 50мс, на 2000 - 800мс
у кого нить был опыт?
Изменить схему таким образом, чтоб обновлять меньше документов
yopp
еще такой вопрос, что с lmt индексами в монге? в wiredtiger есть, но че то я так понял в монге все еще B-tree :/
Я сомневаюсь что структура организации индекса будет иметь хоть какой-то статистически значимый эффект
Nikita
еще меньше обновлять не получится к сожалению
yopp
по каким критериям происходит выборка для обновлений?
yopp
Но в целом, 2.5к операций в секунду на hdd это неплохой результат
Nikita
это CDC из мастер системы. выборка 1) по id 2) по id в массиве(1% обновлений)
Nikita
да, результат вполне ок. 2.5-5к
просто хотел понять можно ли как-то потюнить чтобы не был линейный рост лейтенси при увеличении размера батча.
если батч делать не 150 а 2к то трупут до 8к доходит, но лейтенси 800мс не подходят
Nikita
прежде чем шардировать и накидывать ssd
yopp
97% что эти задержки это дисковая система
yopp
если у вас не очень важные обновления можно делать их мимо журнала
yopp
Возможно это уменьшит задержки, но не уверен
Nikita
в вайртайгер нельзя уже отключить журнал
yopp
Вы можете отключить его в запросе
Nikita
в целом это можно было бы сделать, т.к. обновления из кафки приходят, по сути журнал. Но это нужно оффсеты хранить тогда в монге и доп приседания делать
yopp
Тогда ack операции вам придёт без ожидания журналирования
yopp
Но в целом, я бы не пытался это крутить
yopp
Шарды сомневаюсь что дадут какой-то ощутимый прирост
Nikita
почему?
yopp
В ширину дадут, а вот с точки зрения задержек при равнозначном железе не дадут
yopp
NVME
yopp
И памяти побольше
Nikita
память под диск кэш имеете ввиду?
yopp
А у вас сколько данных?
Nikita
вайтайгера кэш на 1/3 занят. есть что-то что еще в монге по памяти мониторить?
Nikita
ну то что щас гоняется 1кк записей, в бою 150кк будет
Nikita
запись в районе 1-3кб наверное
 Nick
Nick
гайз, а кто нибудь знает какие нибудь фокусы чтобы bulk updates ускорить на блинах?
щас получается размер батча линейно влияет на лейтенси ну и в целом лейтенси хочется чуть поменьше
балк на 150 записей 50мс, на 2000 - 800мс
у кого нить был опыт?
Можно только ordered: false попробовать, но свои приколюхи. А как вы меряете летенси? И почему балк а не просто обычные запросы?
Nikita
ordered false и так, он чуть шустрее вроде чем true но тоже погрешность
лейтенси - System.nano; execute; system.nano и перцентиль в прометеус:)
Nikita
батчи потому что из кафки батч пришел - в монгу батч обработал - закинул.
Nick
ordered false и так, он чуть шустрее вроде чем true но тоже погрешность
лейтенси - System.nano; execute; system.nano и перцентиль в прометеус:)
Замер начинается до сборки батча или именно перед отправкой запроса?
Nikita
обе метрики
Nikita
ну и показывает что основное время execute занимает
Nick
Т.е. Ожидание запроса
Nick
В это время монга упирается в диски/цпу/сеть?
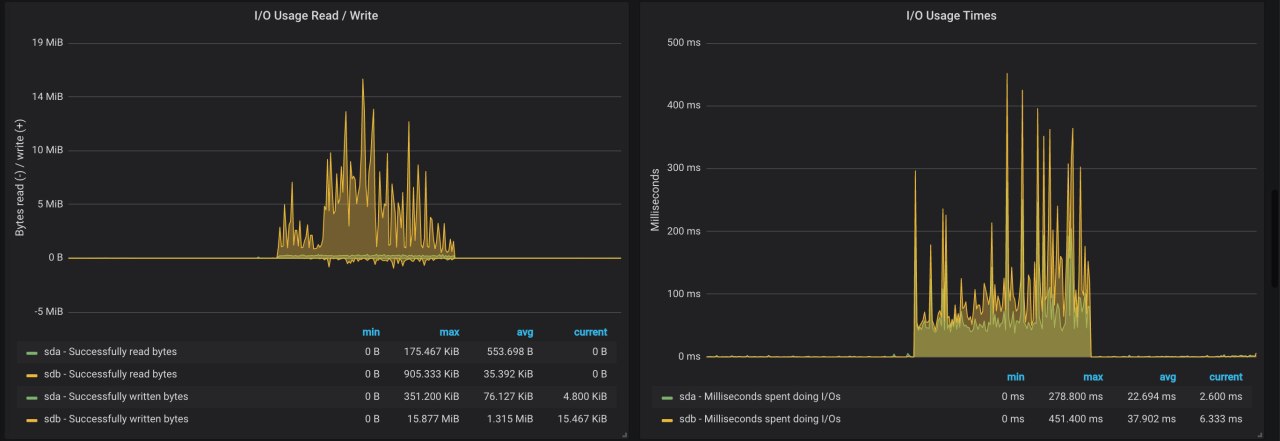
Nikita
ну упирается никуда, но кажется что лейтенси диск дает.
по графикам iotime до 300мс
2k iops на запись между прочим;)
Nick
Nikita
рейд1, хдд, 1 массив 2 диска
Nikita
не спрашивайте почему так:)
Nick
А, можно успокоиться, больше сложно получить
Nikita
 Nikita
Nikita
ну в целом 2к iops на хдд это прям норм так, так что да
Nick
Там расчетная норма 150-200 на обычный диск
Nikita
это рандомные если записи
Nikita
последовательная 10-20к вполне ок
Nikita
я поэтому тож на батчи расчитывал:)
Nikita
хм, не 2к, 1к, в проме запрос кривой был:) но все равно норм, ладно, всем спс
Nick
Скажу только что с ростом количества серваков и шардирование может получиться, что отправка запросов по одному даст больше производительности, но только в асинхронном режиме и некоторых извращениях в коде и магией работы с кафкой
Nikita
а монга балк по шардам не раскидает через роутер?
Nick
Раскидывает, но время ожидания сбора результата со всех шардов - доп латенси
Nikita
ну сеть обычно такую не дает как hdd)
Nikita
ну ладно, это уже если ssd не дадут профита нужного
Nick
ну ладно, это уже если ssd не дадут профита нужного
mongos can attempt to send the writes to multiple shards simultaneously.
Nick
https://docs.mongodb.com/manual/core/bulk-write-operations/#strategies-for-bulk-inserts-to-a-sharded-collection
Nick
короч это уже будущее, потом просто вернетесь к этому вопросу если потребуется
Nikita
да, спс
 Булат
Булат
Доброго времени суток! Скорее всего мой вопрос глупый, только начал использовать mongodb, но возникла ситуация, в которой не могу придумать запрос который возвращал бы 1) результат агрегации 2) количество элементов ДО применения skip и limit
db.bets.aggregate([
{ $match: { 'user.id': id } },
{
$lookup: {
from: 'lots',
let: { lotId: '$lotId' },
pipeline: [{
$match: {
$expr: {
$and: [
{ $eq: ['$_id', '$$lotId'] },
{ $gte: ['$willFinish', now] }
]
}
}
}],
as: 'lot'
}
},
// {
// $count: 'COUNT' - возвращает верно, но результат агрегации не выводится
// },
{
$skip: (page - 1) * limit
}, {
$limit: limit
},
{ $unwind: '$lot' }
])
Булат
можете подсказать в какую сторону смотреть?
Булат
думал можно как-то сначала запомнить результат агрегации, а затем вывести его в два поля, где одно это count, а второе это уже сам результат, через некий $facet возможно
Булат
не хотелось бы в два запроса выполнять
Булат
я не знаю как работает монго под капотом, но не думаю что он способен это соптимизровать так, чтоб он не выполнял эту агрегацию два раза
Nick
делайте два запроса
Булат
то есть он выполнит оптимизацию? или нет другого способа?
Nick
на какую оптимизацию вы расчитываете?
Булат
{ $match: { 'user.id': id } },
{
$lookup: {
from: 'lots',
let: { lotId: '$lotId' },
pipeline: [{
$match: {
$expr: {
$and: [
{ $eq: ['$_id', '$$lotId'] },
{ $gte: ['$willFinish', now] }
]
}
}
}],
as: 'lot'
}
},
что вот эта часть не будет выполняться дважды
Nick
{ $match: { 'user.id': id } },
{
$lookup: {
from: 'lots',
let: { lotId: '$lotId' },
pipeline: [{
$match: {
$expr: {
$and: [
{ $eq: ['$_id', '$$lotId'] },
{ $gte: ['$willFinish', now] }
]
}
}
}],
as: 'lot'
}
},
что вот эта часть не будет выполняться дважды
вам нужно делать два разных запроса
Булат
окей, благодарю
 Vladislav
Vladislav
привет. Не получается сделать апдейт массива субдокументов таким образом: