и если я правильно понял что вы хотите обновить 1кк записей - то конечно же это будет долго - ресурсы диска не бесконечны
Нет, обновить нужно только те, которые попадают под условие :)
 Anonymous
Anonymous


 Nick
Nick
а сколько таких?
Nick
тогда вам точно в эксплейн
Nick
и смотреть как выпоняется запрос
Anonymous
ну вот я потыкал его, а что нужно сделать, что бы улучшить результат - хз )
Nick
наверняка индекс можно добавить
Nick
эксплейн на гист закиньте
Anonymous
https://gist.github.com/bespilotnayakartoshka/2f79ee76eac208a8f5201c1fea30fc81
 Andrey
Andrey
Второе, но вместо mongoexport/import используйте mongodump/restore
правильно понимаю, что такую операцию нужно на каждом сервере в кластере проделывать?
 yopp
yopp
Нет, не на каждом. Если вливать в существующий кластер то записи автоматически реплицируются
Andrey
а если шардированый кластер?
yopp
а если шардированый кластер?
mongos сам сбалансирует по шардам и внутри шарда оно автоматически реплицируется
Andrey
mongos сам сбалансирует по шардам и внутри шарда оно автоматически реплицируется
имею в виду с шардов с каждого отдельно снимать дамп?
yopp
Зависит от цели
Andrey
ааа ну шард подразумевает же в теории независимую точку отказа верно? то есть если упала определённая нода, то достаточно только её восстановить, поэтому можно делать асинхронно бэкап с каждого шарда полагаясь на их взаимонезависимость. логика верна?
yopp
зависит от данных
yopp
в общем случае нет, логика не верна
yopp
если есть связанные данные, то необходим point-in-time бэкап, который для всего кластера очень нетривиально сделать
Andrey
да я понял, спасибо, изначально полагал связность всех данных. но по факту описал для несвязных
а есть где почитать про point-in-time бэкапы, проблемы, примеры как и что блокировать? так понимаю это то, что из коробки атлас предлагает
 Murena
Murena
Всем привет - подскажите, у меня система парсит определенные текстовые данные и складывает в mongoDB - это все работает через очередя - и паралельно может выполнятся до 4-8 процессов - которые добавляют данные в базу и у меня довольно часто когда размеры базы по определенному фильтру/выборке становятся большыми - происходит повреждение данных в бд что приходится делать db.repairDatabase() потом все успешно работает дальше - вопрос: Может ли из за того что процесы которые через очередя добавляют данные в бд и добавляют информацию в один и тот же документ - вызывать повреждение данных в базе - что потом приходится делать db.repairDatabase()
Murena
то есть у меня подозрение что добавление одновременное данных в один и тот же документ разными процессами - вызывает повреждение бд - это возможно ? или наврят ?
Murena
MongoDB server version: 4.0.5
Null
Январские обновления:
* 4.2.3
* 4.0.16, 4.0.15
* 3.6.17
Завершилась поддержка версии 3.4, обновлений больше не будет. Настоятельно рекомендую запланировать обновление вашего кластера
Murena
даные в бд добавляются/дополняются в массив посредством
{ $push: { items: { $each: value } } }
Murena
то есть может быть такое что два процесса пытаются добавить доп елементы в массив одного и того же документа посредством
{ $push: { items: { $each: value } } }
yopp
4.2.3 (Jan 27) ◦ 4.0.16 (Feb 5)
• Плейграунд для запросов
• Документация
• Официальные курсы по MongoDB
Stable: 4.2.3 ◦ Bugfix: 4.0.16
Legacy: 3.6.17 (Jan 27)
По вопросам покупки Enterprise лицензии пишите @dd_bb
☠️: 3.4.23 (Jan ‘20), 3.2.21 (Dec ’18), 3.0.15 (May ’17)
yopp
yopp
проверьте SMART у вашей дисковой системы, проверьте память
Murena
ясно - значит буду рыть где то еще проблему
yopp
и обновитесь до 4.0.16
 Андрей
Андрей
Всем привет, реально ли как-то вывести из базы строки с повторяющимся значением одного из столбцов
yopp
Всем привет, реально ли как-то вывести из базы строки с повторяющимся значением одного из столбцов
https://docs.mongodb.com/manual/reference/operator/aggregation/group/
 Dmitriy
Андрей
Dmitriy
Андрей
Спасибо
Anonymous
Будет правильней хранить в базе данные в таком виде:
data: {
"1": {
"name": "string"
},
"2": {
"name": "string"
}
и т.д
}
или в таком?
data: [
{
"id": 1,
"name": "string"
},
{
"id": 2,
"name": "string"
}
]
В первом случае мне не нужно делать перебор по массиву чтобы полуить нужный мне элемент. По моему так быстрее и экономнее
Что скажете?
yopp
По первому варианту невозможно сдклать индекс
Anonymous
Ааа
yopp
Внутри bson документы и массивы это одно и тоже
yopp
Разница только в том, что в массиве ключ это индекс элемента в виде строки
Anonymous
Спасибо, теперь я понял
 Vlad
Vlad
Разница только в том, что в массиве ключ это индекс элемента в виде строки
вроде, инты в роли индекса
yopp
‘0’: {}, ‘1’: {}
yopp
Потому что key в документе это cstring
Vlad
понял, наверное логично не тратить по 4 байта на индекс
yopp
Нет, там небольшой оверхед, это null-terminated strong.
yopp
Но основное преимущество в том, что массивы поддокументов индексируются
yopp
А просто вложенные документы нет
yopp
Потому что монга не умеет индексировать содержимое ключей
yopp
Она умеет индексировать только сами значения
yopp
За счёт компрессии разницы не будет, массивы даже могут быть более компактно сжаты
Anonymous
А ты крутой
yopp
С точки зрения времени доступа тоже никакой разницы нет, потому что структуры идентичные. Так что доступ по индексу не отличается от доступа по ключу
yopp
Можно до 4.2.3. Но там могут быть нюансы с совместимостью. Внутри одной ветки апгрейд должен без проблем пройти
 Konstantin
Konstantin
 Leonid
Leonid
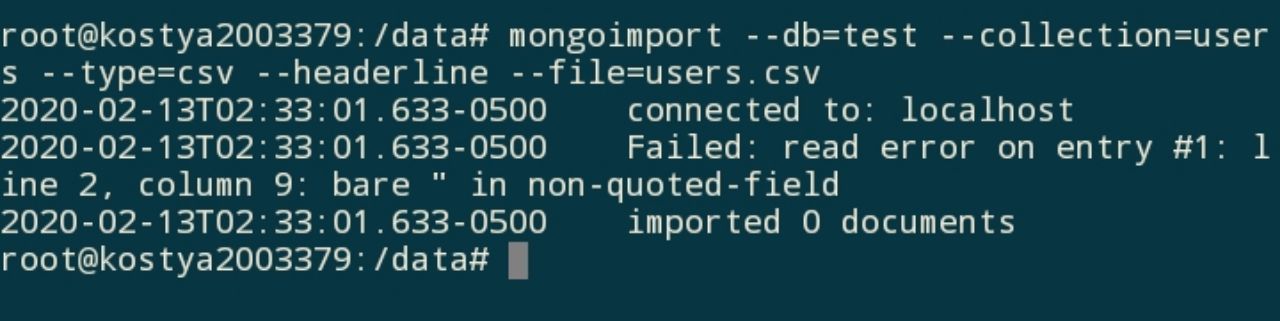
ну тут же четко написано что кривой входной файл
Leonid
даже строка и колонка указана
Leonid
смотри что там
Konstantin
Вряд-ли он может быть кривым
Leonid
легко
Konstantin
Я импортировал его через компас
Konstantin
Экспортировал*
Leonid
у каждой проги свои стандарты. то что файл импортился в одной проге не означает успешный импорт в другой
Leonid
просто проверь. у тебя похоже там ..... , some " text , .....
Leonid
а ковычки внутри текста не допустимы при таком подходе. нужно экранирование
 Павел
Павел
Народ, есть реализация embedded mongo какой нибудь, чтобы можно было в java приложении во время теста быстро поднять, заполнить, протестить и очистить?
Konstantin
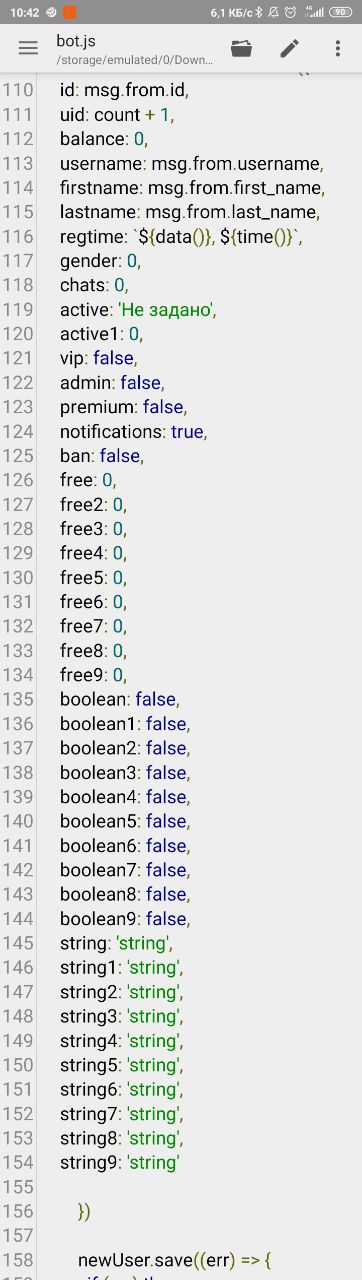
Я импортировал через компас, но он почему то начал ещё раз регестрировать всех пользователей
Leonid
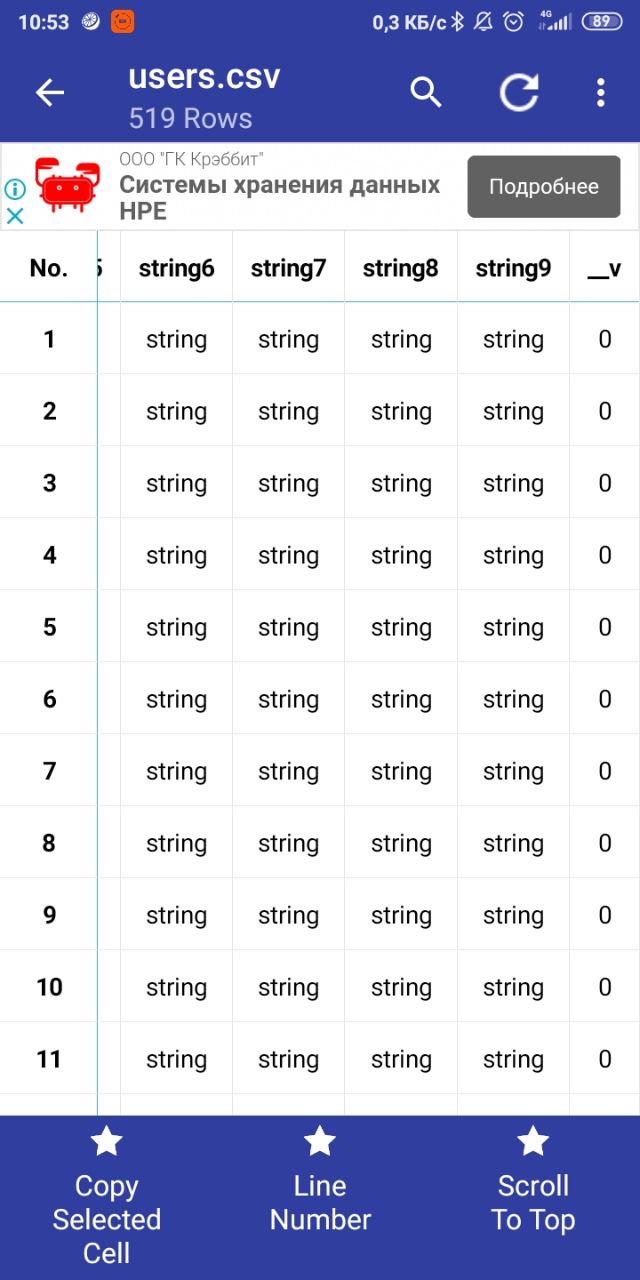
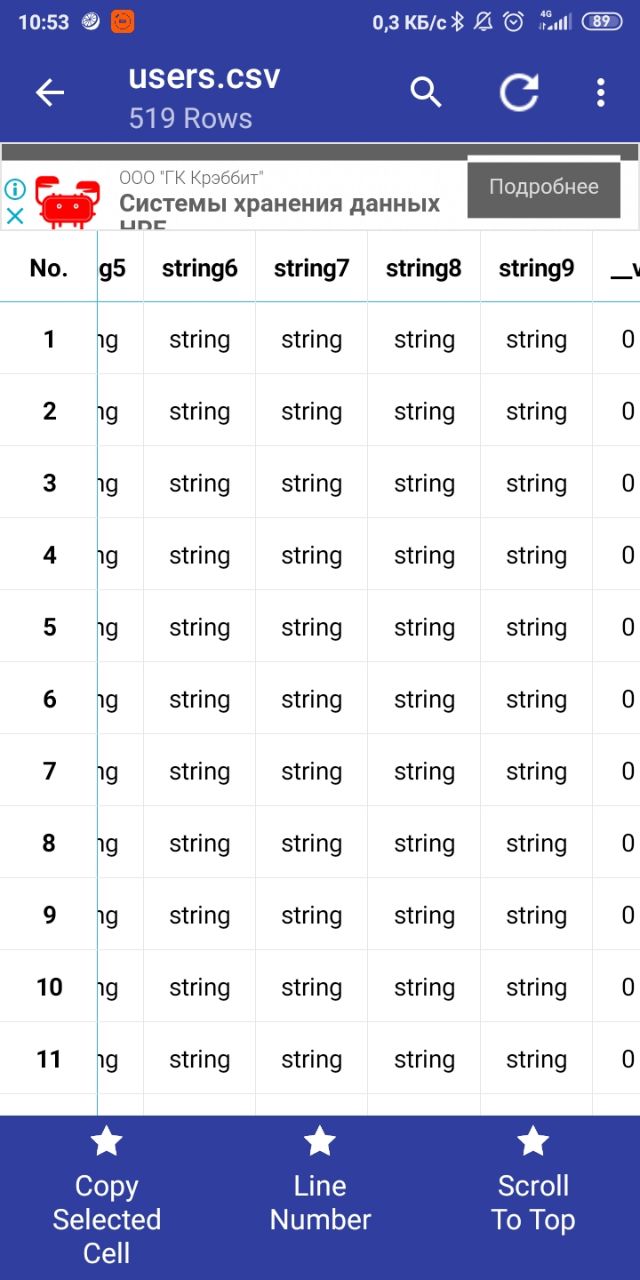
скинь 1ю строку csv
Dmitriy
Народ, есть реализация embedded mongo какой нибудь, чтобы можно было в java приложении во время теста быстро поднять, заполнить, протестить и очистить?
есть докер и монга в нем, все очень быстро и почти embeded
 Konstantin
Konstantin
Сейчас открою его