 Евгений
Евгений


Естественно
Евгений
ЕлементМатч возвращает документ, если хотя бы один элемент в массиве совпадет
Евгений
Я сегодня тоже ипался с этим
Евгений
Ты уверен что ты правильно данные кладешь?
Евгений
Как бы ты можешь сделать группировку и полнотекстовый поиск из того что я начитал, но блин, оно надо?)) Не проще промокоды положить в отдельную табу
Евгений
?
Евгений
Я бы так сделал
 Nick
Nick
он мне отдал все items из доки
https://docs.mongodb.com/manual/reference/operator/aggregation/filter/
Евгений
Я только боюсь как бы группировка не сработала на документ целиком
 Mikhail
Mikhail
Привет всем! Тут же есть специалисты по монге? Кто-нибудь знает как можно сделать аналог distinct по полю в коллекции за адекватное время. Индекс есть, но он не спасает. Знающие чуваки посоветовали использовать aggregation, но оно всё равно не работает особо быстро
Евгений
Тут их нет, проверено))
Nick
Привет всем! Тут же есть специалисты по монге? Кто-нибудь знает как можно сделать аналог distinct по полю в коллекции за адекватное время. Индекс есть, но он не спасает. Знающие чуваки посоветовали использовать aggregation, но оно всё равно не работает особо быстро
Какие критерии адекватности времени? Сколько данных? Есть ли какие-то фильтры на выборке?
Mikhail
Какие критерии адекватности времени? Сколько данных? Есть ли какие-то фильтры на выборке?
Сейчас среднее время 4 секунды (с aggregation) или 8 секунд для distinct.
Есть один фильтр secondfield: null, индекс сделан с таким же фильтром. Данных около 1m документов.
madspectator
А индекс полностью в память загружен?
Nick
Сейчас среднее время 4 секунды (с aggregation) или 8 секунд для distinct.
Есть один фильтр secondfield: null, индекс сделан с таким же фильтром. Данных около 1m документов.
После фильтрации сколько доков получается?
Nick
Уберите условие с нулом и постфактум его уберите из результата
Nick
Не вижу проблемы вынести бизнес логику из базы в приложение
Mikhail
Не вижу проблемы вынести бизнес логику из базы в приложение
Тогда мне придется делать distinct по двум полям.
Если коротко: каждый документ - один проданный продукт. Там где поле не null - это неоплаченный продукт. Мне нужно получать distinct по клиентам у которых есть оплаченные продукты
Mikhail
Мне проще завести отдельную коллекцию активных клиентов, чем переделывать эту логику
Mikhail
Но это как-то глупо выглядит по сравнению с тем, что в реляционных базах такие запросы особо проблем не вызывали. А в монге при наличии индекса который имеет только нужные данные почему-то всё становится очень долго
madspectator
А зачем там вообще монга тогда?
Mikhail
А зачем там вообще монга тогда?
Типичный русский чат: на конкретно сформулированную проблему отвечают - вы не должны этого хотеть и вообще всё делаете неправильно
madspectator
Mikhail
Я такого не говорил.
Короткий ответ: дизайн решения приняты не мной, но имеется весьма конкретное обоснование относительно существующей инфраструктуры в компании
Kenan
Вам придется группировать скорее всего
К этом выводу всё таки пришёл. Надо будет каждое свойство разбить по коллекциям, прикрепить ссылки в виде ObjectID и работать так
Kenan
Ибо я пытаюсь в нереляционке сделать реалиционку ( т.е. хернёй страдаю)
Евгений
Короткий ответ: дизайн решения приняты не мной, но имеется весьма конкретное обоснование относительно существующей инфраструктуры в компании
Так может индекс перестроить? Может у вас неправильно сортируется таблица индекса и потому типа оптимизатор не выбирает его и считает что ему проще фулскан сделать?) Индекс и пример запроса в студию
Евгений
Без них вряд-ли кто поможет
Mikhail
Так может индекс перестроить? Может у вас неправильно сортируется таблица индекса и потому типа оптимизатор не выбирает его и считает что ему проще фулскан сделать?) Индекс и пример запроса в студию
distinct работает плохо, про это разработчики монги сами говорят. А вот адекватной замены нет
Евгений
distinct работает плохо, про это разработчики монги сами говорят. А вот адекватной замены нет
Distinct везде плохо работает
Евгений
Вы дайте индексы
Евгений
И пример запроса
Евгений
Может кто чё увидит
Mikhail
db.getCollection('Col').explain("executionStats").aggregate(
{$match: {'second': null}},
{$group: {
"_id": "$first"
}}
)
Евгений
Ну а индекс
Евгений
Вы говорили у вас там null поле
Евгений
Понял
Евгений
Сори
Евгений
Ну у вас есть индекс где просто second и поле id за ним?
Евгений
А ещё, я сам 2 дня пользуюсь монгой, но у вас explain вызывается всегда, так прям в коде написано или для теста и только сейчас?
Mikhail
Более правильный запрос
db.getCollection('Col').explain("executionStats").aggregate(
[{$match: {'excludeField': null}},
{$group: {
"_id": "$A"
}}],
{hint: { "A": 1, "B": 1 }}
)
Евгений
Да хорошо, индекс мне)
Mikhail
Index db.Col.createIndex({ "A": 1, "B": 1 }, {partialFilterExpression: {excludeField: null}});
Mikhail
"$cursor" : {
"query" : {
"excludeField" : null
},
"fields" : {
"A" : 1,
"_id" : 0
},
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "db.Col",
"indexFilterSet" : false,
"parsedQuery" : {
"excludeField" : {
"$eq" : null
}
},
"winningPlan" : {
"stage" : "FETCH",
"filter" : {
"excludeField" : {
"$eq" : null
}
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"A" : 1.0,
"B" : 1.0
},
"indexName" : "A_1_B_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"A" : [],
"B" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"A" : [
"[MinKey, MaxKey]"
],
"B" : [
"[MinKey, MaxKey]"
]
}
}
},
"rejectedPlans" : []
},
Mikhail
По-умолчанию без hint использует индекс db.Col.createIndex({excludeField: 1});
Евгений
А у вас индексы дефрагментированны?
Евгений
Чем индекс более фрагментирован тем медленнее он работает))
Евгений
Я просто хз, какой командой запустить дефрагментацию и не делает ли моего ее сам
Евгений
Но если у Вас миллион записей, а дефрагментации не было, то это в разы все замедлит
Евгений
У вас просто получается больше данных в индексе, много мусора и пробелов между данными, много страниц и т.д. это я предполагаю все по аналогии с sql
Евгений
Но как бы тут вряд-ли как-то по другому
Евгений
Все БД основы плюс-минус одинаковые
Евгений
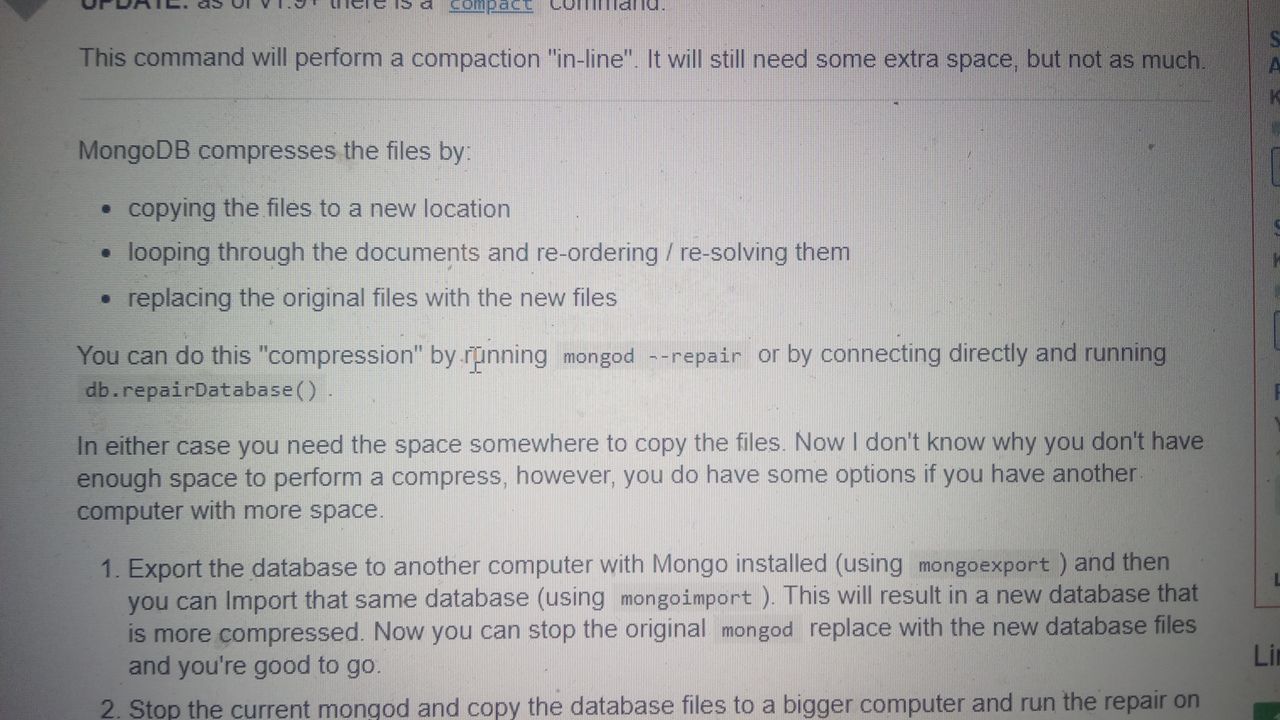 Евгений
Евгений
Попробуйте repairDatabase() запустить
Евгений
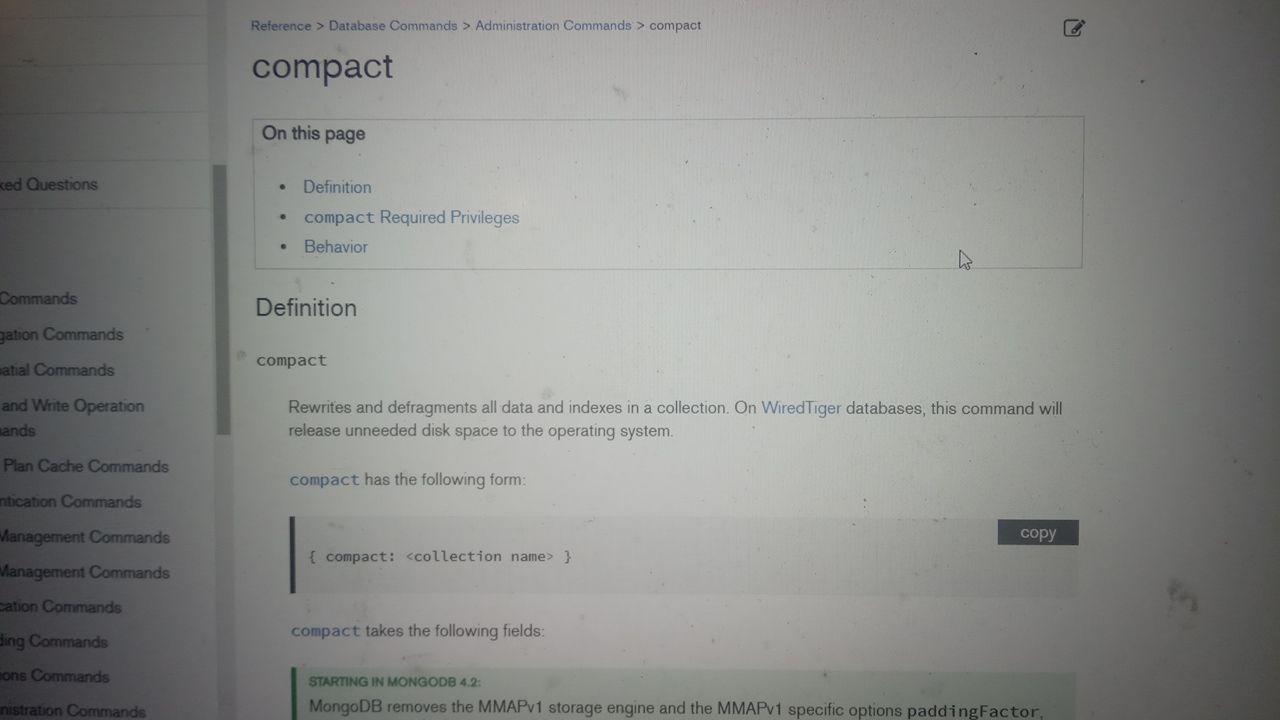 Евгений
Евгений
Вот ещё compact есть
Евгений
Попробуйте запустить и отпишитесь, если удачно
Евгений
По-умолчанию без hint использует индекс db.Col.createIndex({excludeField: 1});
Лучше compact - это написано что явная дефрагментация
Nick
Я просто хз, какой командой запустить дефрагментацию и не делает ли моего ее сам
фрагментация не имеет смысла, если данные уже в ОС кэш попали, а раз индекс не большой, то это уже так.
Nick
По-умолчанию без hint использует индекс db.Col.createIndex({excludeField: 1});
потому что у вас индекс работает только в матче, а дальше уже тащатся все данные из документов для группировки
Nick
Более правильный запрос
db.getCollection('Col').explain("executionStats").aggregate(
[{$match: {'excludeField': null}},
{$group: {
"_id": "$A"
}}],
{hint: { "A": 1, "B": 1 }}
)
сделайте после матча $project где вы оставляете только ваши поля А и В, и после этого сделайте эксплейн без хинта
Nick
 Denis
Denis
Всем привет. Как наименее затратно сделать запрос в монго если такая структура: коллекция фирмы , у фирмы есть автосалоны своя коллекция, у автосалона есть подписчики , коллекция юзеры. Нужно выдать для фирмы первые 5 подписчиков. Голову ломаю как оптимизировать запрос.
Проект на yii2
madspectator
А что именно сейчас тормозит?
Denis
А что именно сейчас тормозит?
Запрос). Выбираются все автосалоны по ним getAll подписчики с лимитом 5
madspectator
Ну т.е. там несколько запросов, по запросу на коллекцию? В mongodb есть такое https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/, но я сам не юзал.
Denis
madspectator
Ну, а в целом, не понятно, что там у вас. Что за запросы. Может быть, банально, индексы в память не влазят.
 Dmitriy
Dmitriy
Всем привет. Как наименее затратно сделать запрос в монго если такая структура: коллекция фирмы , у фирмы есть автосалоны своя коллекция, у автосалона есть подписчики , коллекция юзеры. Нужно выдать для фирмы первые 5 подписчиков. Голову ломаю как оптимизировать запрос.
Проект на yii2
я бы на вашем месте кроном делал подготовку данных в отдельную коллекцию, если вам не нужен прямо реалтайм. все остальные решения будут все равно проигрывать по перформансу
 yopp
yopp